

 新火种
2023-11-01
新火种
2023-11-01 


告别CPU,加速100-1000倍!只用GPU就能完成物理模拟和强化学习训练

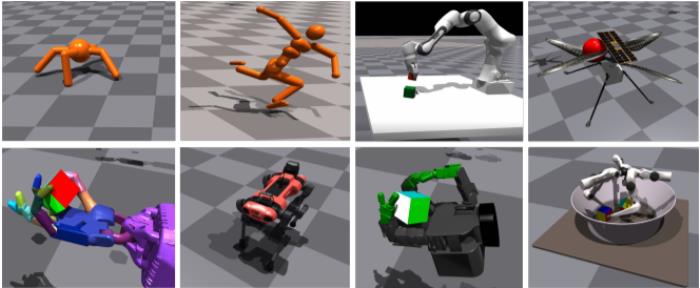 图1:Isaac Gym使不同机器人在复杂环境中进行各种高性能训练。研究人员对8种不同的复杂环境进行了基准测试,并展示了模拟器在单个GPU上进行快速策略训练的优势。上面:Ant, Humanoid,Franka-cube-stack,Ingenuity。下面:Shadow Hand, ANYmal, Allegro, TriFinger.项目地址:https://sites.google.com/view/isaacgym-nvidia1
图1:Isaac Gym使不同机器人在复杂环境中进行各种高性能训练。研究人员对8种不同的复杂环境进行了基准测试,并展示了模拟器在单个GPU上进行快速策略训练的优势。上面:Ant, Humanoid,Franka-cube-stack,Ingenuity。下面:Shadow Hand, ANYmal, Allegro, TriFinger.项目地址:https://sites.google.com/view/isaacgym-nvidia1简介近年来,强化学习(RL)已经成为机器学习中最值得研究的领域之一,它在解决复杂决策问题方面拥有巨大的潜力。无论是围棋、国际象棋等经典策略游戏,还是《星际争霸》、《DOTA》等即时战略游戏,深度强化学习(Deep RL)对于这种具有挑战性的任务表现得都很突出,它在机器人环境中的表现也令人印象深刻,包括腿部运动和灵巧的操作等。模拟器可以提高学习过程中的安全性和迭代速度,在训练机器人的过程中发挥着关键作用。在真实世界中训练仿人机器人,比如让它进行上下楼梯的训练,可能会破坏其器械和周边环境,甚至有可能伤害到操控它的研究人员。有一种方法可以排除在现实世界中训练的安全隐患,那就是在模拟器内进行训练。模拟器可以提供一个高效、可扩展的平台,允许进行大量试错实验。目前,大多数研究人员还是结合CPU和GPU来运行强化学习系统,利用这两个部分分别处理物理模拟和渲染过程的不同步骤。CPU用于模拟环境物理、计算奖励和运行环境,而GPU则用于在训练和推理过程中加速神经网络模型,以及在必要时进行渲染。然而,在优化顺序任务的CPU内核和提供大规模并行性的GPU之间来回转换,需要在训练中系统的不同部分的多个点之间传输数据,这种做法从本质上来说是非常低效的。因此,机器人深度强化学习的扩展面临着两个关键瓶颈:1)庞大的计算需求 2)模拟速度有限。机器人在进行高度自由的复杂学习行为时,这些问题尤为突出。物理引擎如MuJoCo、PyBullet、DART、Drake、V-Rep等都需要大型CPU集群来解决具有挑战性的RL任务,这些无一不面临着上述瓶颈。例如,在“Solving Rubik’s Cube with a Robot Hand”这项研究中,近30,000个CPU核心(920台工人机器,每台有32个核心)被用来训练机器人使用RL解决魔方任务。在一个类似研究“Learning dexterous in-hand manipulation”中,使用了一个由384个系统组成的集群,包含6144个CPU核,加上8个NVIDIA V100 GPU,进行30个小时的训练,RL才能收敛。用硬件加速器可以加快模拟和训练。在计算机图形学方面已经取得巨大成功的GPU自然也能适用于高度并行的模拟。“Gpu-accelerated robotic simulation for distributed reinforcement learning”研究中采取了这种方法,并显示了在GPU上运行模拟的令人喜出望外的结果,这证明了有可能可以极大缩减训练时间以及使用RL解决极具挑战性的任务所需的计算资源。但是,此项工作中仍有一些瓶颈没有解决——模拟是在GPU上进行的,但物理状态会被复制回CPU。因此,观察和奖励是用优化的C++代码计算的,接着再复制回GPU,在那里运行策略和价值网络。此外,该项工作只训练了简单的基于物理学的场景,而不是具有代表性的机器人环境,也没有尝试实现sim2real(从模拟环境迁移到现实环境)。为了解决这些瓶颈问题,我们提出了Isaac Gym——一个端到端的高性能机器人模拟平台。它可以运行一个端到端的GPU加速训练管道,使研究人员能够克服上述限制,在连续控制任务中实现100倍-1000倍的训练速度。Isaac Gym利用NVIDIA PhysX提供了一个GPU加速的模拟后端,使其能够以使用高度并行才能实现的速度来收集机器人RL所需的经验数据。它提供了一个基于PyTorch张量的API来访问GPU上的物理模拟结果。观察张量可以作为策略网络的输入,产生的行动张量可以直接反馈给物理系统。我们注意到,其他研究人员最近已经开始尝试使用与Isaac Gym类似的方法,在硬件加速器上运行端到端训练。通过端到端方法,包括观察、奖励和动作缓存的整个学习过程可以直接在GPU上进行,无需从CPU上读回数据。这种设置允数以万计的模拟环境在一个GPU上同时进行,使研究人员能够只使用一个小型GPU服务器就能解决以前无法完成的任务,轻松地在桌面级计算机上运行以前需要在整个数据中心才能进行的实验。Isaac Gym为创建和填充机器人及物体的场景提供了一个简单的API,支持从常见的URDF和MJCF文件格式加载数据。每个环境可根据需要被复制多次,并且同时保留了副本的可变性(例如通过Domain Randomization来合成新数据)。在不与其他环境互动的情况下,这些环境可以同时进行模拟。而且,研究人员用一个完全由GPU加速的模拟和训练管道降低了研究的门槛,使其可以用一个GPU解决以前只能在大规模CPU集群上实现的任务。Isaac Gym还包括一个基本的近似策略优化(PPO)执行和一个简单的RL任务系统,用户可以根据需要替换其他任务系统或RL算法。虽然一些研究使用PyTorch,但用户也应该能够通过进一步的定制与TensorFlow训练库整合。图2提供了该系统的概览。
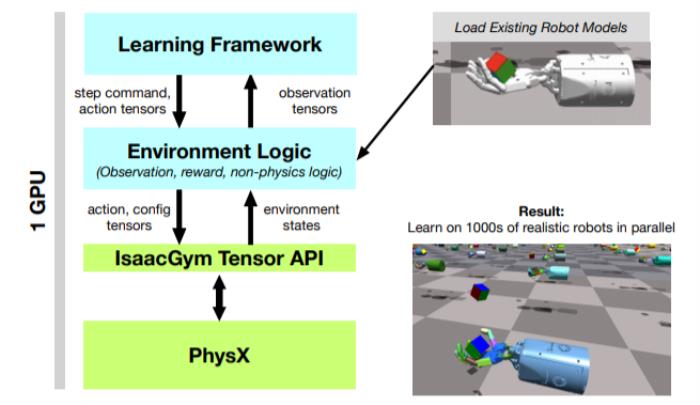 图2:Isaac Gym管道的图示。Tensor API为Python代码提供了一个接口,可以直接在GPU上启动PhysX后端,获取和设置模拟器状态,从而使整个RL训练管道的速度提高100-1000倍,同时提供高保真模拟和与现有机器人模型连接的能力。2
图2:Isaac Gym管道的图示。Tensor API为Python代码提供了一个接口,可以直接在GPU上启动PhysX后端,获取和设置模拟器状态,从而使整个RL训练管道的速度提高100-1000倍,同时提供高保真模拟和与现有机器人模型连接的能力。2表征模拟性能研究人员首先将模拟性能描述为环境数量的函数。当改变这个数字时,目的是通过按比例减少horizon length(即PPO的步骤数,计算奖励前智能体的执行步骤数)来保持RL智能体观察到的整体经验不变,以便进行公平的比较。虽然我们在后面提供了许多环境的详细训练研究,但这里只描述了 Ant、Humanoid 和Shadow Hand 的模拟性能,因为它们足够复杂,可以测试模拟的极限,也代表了复杂性的逐步增加。这三种环境都使用前馈网络进行训练。
蚂蚁(Ant)
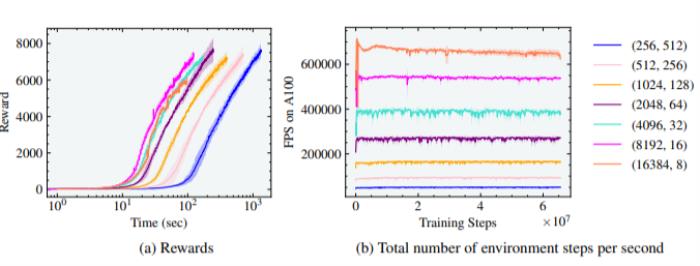 图3:蚂蚁实验的奖励和有效FPS与并行环境的数量有关。最佳训练时间是在8192个环境和16个horizon length 的情况下实现的。研究人员首先用标准的蚂蚁环境进行实验,在这个环境中,训练智能体在平地上运动。我们发现,随着智能体数量的增加,训练时间如预期的那样减少了,也就是当把环境的数量从256个增加为8192个(增加了5个数量级)后,使得达到7000奖励的训练时间减少了一个数量级,训练时间从1000秒(约16.6分钟)减少到100秒(约1.6分钟)。然而,请注意,蚂蚁在单个GPU上仅用20秒就达到了3000奖励的高性能运动。由于蚂蚁是最简单的模拟环境之一,如图3(b)所示,每秒并行环境步骤的数量可高达700K。由于horizon length减少,当环境数量从8192增加到16384时,没有观察到收益。
图3:蚂蚁实验的奖励和有效FPS与并行环境的数量有关。最佳训练时间是在8192个环境和16个horizon length 的情况下实现的。研究人员首先用标准的蚂蚁环境进行实验,在这个环境中,训练智能体在平地上运动。我们发现,随着智能体数量的增加,训练时间如预期的那样减少了,也就是当把环境的数量从256个增加为8192个(增加了5个数量级)后,使得达到7000奖励的训练时间减少了一个数量级,训练时间从1000秒(约16.6分钟)减少到100秒(约1.6分钟)。然而,请注意,蚂蚁在单个GPU上仅用20秒就达到了3000奖励的高性能运动。由于蚂蚁是最简单的模拟环境之一,如图3(b)所示,每秒并行环境步骤的数量可高达700K。由于horizon length减少,当环境数量从8192增加到16384时,没有观察到收益。人形物体(Humanoid)

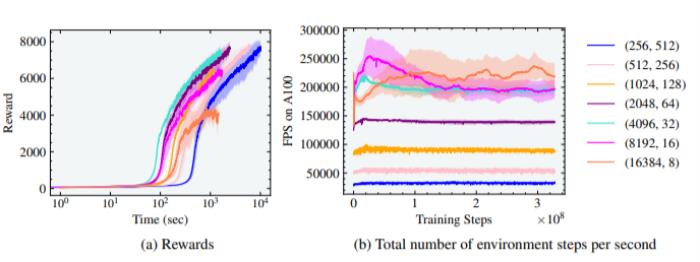 图4:人形实验的奖励和有效FPS与并行环境的数量有关。最佳训练时间是在4096个环境和32个horizon length 的情况下实现的。
图4:人形实验的奖励和有效FPS与并行环境的数量有关。最佳训练时间是在4096个环境和32个horizon length 的情况下实现的。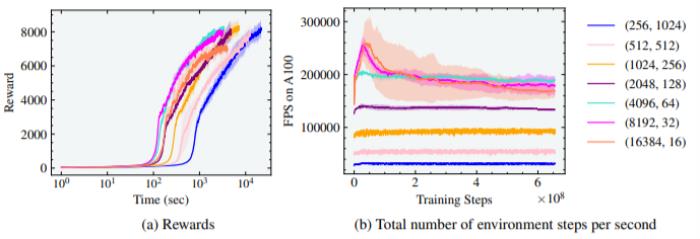 图5:人形实验的奖励和有效FPS与平行环境的数量有关。在4096和8192个环境中实现了最佳训练时间,horizon length 分别为64和32。研究人员在图中4还注意到,随着智能体数量的增加,从256个增加到4096个,达到最高奖励7000的训练时间从10^4秒(约2.7小时)减少到10^3秒(约17分钟)的数量级。然而,奖励为5000左右时,高性能运动出现了,训练时间仅为4分钟。在这种情况下,如果超过4096个环境,就不会有进一步的收益,实际上会导致训练时间的增加和收敛于次优步态。研究人员将此归因于环境的复杂性,这使得在如此小的horizon length 上学习行走具有挑战性。可以通过对另一组环境和horizon length 的组合进行训练来验证这一点,与图4相比,horizon length 增加了2倍。如图5所示,即使在8192和16384环境中,人形机器人也能行走,这两个环境的horizon length 分别为32和16,但足够长,可以进行学习。另外值得注意的是,由于自由度的增加,每秒并行环境步骤的数量从蚂蚁的700K减少到人形的200K,如图4和5所示。
图5:人形实验的奖励和有效FPS与平行环境的数量有关。在4096和8192个环境中实现了最佳训练时间,horizon length 分别为64和32。研究人员在图中4还注意到,随着智能体数量的增加,从256个增加到4096个,达到最高奖励7000的训练时间从10^4秒(约2.7小时)减少到10^3秒(约17分钟)的数量级。然而,奖励为5000左右时,高性能运动出现了,训练时间仅为4分钟。在这种情况下,如果超过4096个环境,就不会有进一步的收益,实际上会导致训练时间的增加和收敛于次优步态。研究人员将此归因于环境的复杂性,这使得在如此小的horizon length 上学习行走具有挑战性。可以通过对另一组环境和horizon length 的组合进行训练来验证这一点,与图4相比,horizon length 增加了2倍。如图5所示,即使在8192和16384环境中,人形机器人也能行走,这两个环境的horizon length 分别为32和16,但足够长,可以进行学习。另外值得注意的是,由于自由度的增加,每秒并行环境步骤的数量从蚂蚁的700K减少到人形的200K,如图4和5所示。影子手(Shadow Hand)
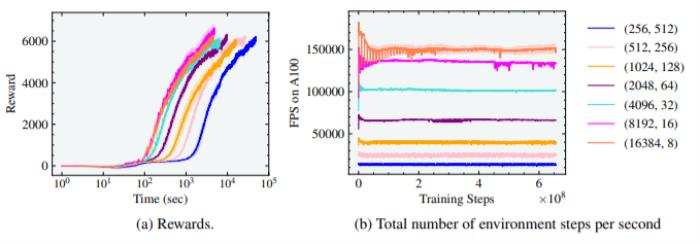 图6:Shadow Hand实验的奖励和有效FPS与并行环境的数量有关。在8192和16384个环境以及16和8个horizon length 的情况下,达到最佳训练时间。最后,研究人员用影子手进行实验,让它学习用手指和手腕将放在手掌上的立方体旋转到目标方向。受所涉及的DoF数量和旋转过程中的接触影响,这项任务具有不小的挑战。我们在 "影子手"环境中的结果也遵循类似的趋势。随着智能体数量的增加,在这种情况下,从256增加到16384,训练时间减少了一个数量级,从5×10^4秒(约14小时)到3×10^3秒(约1小时)。我们发现,该环境在短短5分钟内就达到了连续10次成功的奖励的灵巧性能。此外,16384个智能体的horizon length 为8,仍然允许学习重新摆放立方体。16384个智能体的最大有效帧率为每秒150K个并行环境步骤。
图6:Shadow Hand实验的奖励和有效FPS与并行环境的数量有关。在8192和16384个环境以及16和8个horizon length 的情况下,达到最佳训练时间。最后,研究人员用影子手进行实验,让它学习用手指和手腕将放在手掌上的立方体旋转到目标方向。受所涉及的DoF数量和旋转过程中的接触影响,这项任务具有不小的挑战。我们在 "影子手"环境中的结果也遵循类似的趋势。随着智能体数量的增加,在这种情况下,从256增加到16384,训练时间减少了一个数量级,从5×10^4秒(约14小时)到3×10^3秒(约1小时)。我们发现,该环境在短短5分钟内就达到了连续10次成功的奖励的灵巧性能。此外,16384个智能体的horizon length 为8,仍然允许学习重新摆放立方体。16384个智能体的最大有效帧率为每秒150K个并行环境步骤。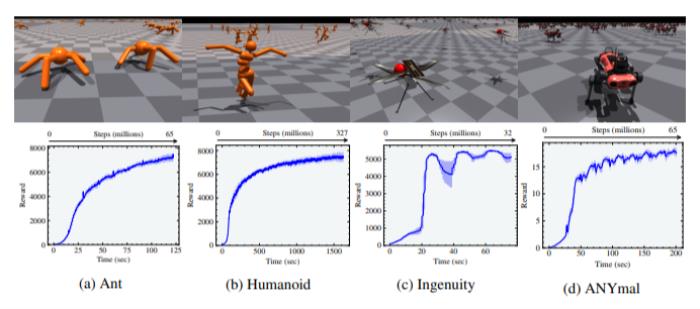 图7:运动环境和相应的奖励曲线
图7:运动环境和相应的奖励曲线

 图9:使用AMP训练的仿人角色模仿旋风踢的动作
图9:使用AMP训练的仿人角色模仿旋风踢的动作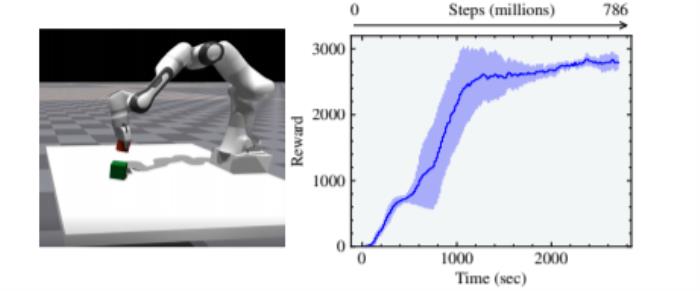 图10:Franka Cube堆叠环境和相应的奖励曲线
图10:Franka Cube堆叠环境和相应的奖励曲线 图11:在Isaac Gym中实现的三种手内操纵环境:Shadow Hand, Trifinger和 Allegro
图11:在Isaac Gym中实现的三种手内操纵环境:Shadow Hand, Trifinger和 Allegro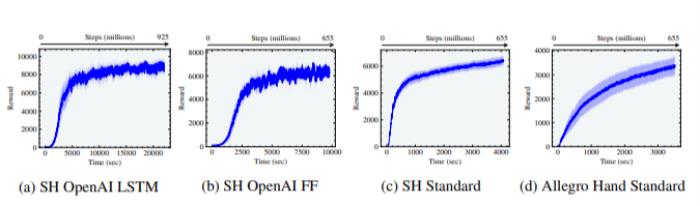 图12:在Isaac Gym中实现的三种手内操纵环境的奖励曲线。这些结果是通过(a)采用OpenAI观察和LSTM的Shadow Hand(b)采用OpenAI观察和前馈网络的Shadow Hand(c)采用标准观察的Shadow Hand(d)采用标准观察的Allegro Hand获得的。Shadow Hand OpenAI是用不对称的actor-critic 和领域随机化训练的,而Shadow Hand标准和Allegro Hand标准是用标准观察和对称的actor-critic训练的,没有领域随机化。
图12:在Isaac Gym中实现的三种手内操纵环境的奖励曲线。这些结果是通过(a)采用OpenAI观察和LSTM的Shadow Hand(b)采用OpenAI观察和前馈网络的Shadow Hand(c)采用标准观察的Shadow Hand(d)采用标准观察的Allegro Hand获得的。Shadow Hand OpenAI是用不对称的actor-critic 和领域随机化训练的,而Shadow Hand标准和Allegro Hand标准是用标准观察和对称的actor-critic训练的,没有领域随机化。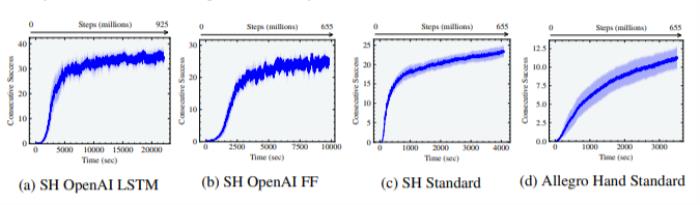

总结研究表明,Isaac Gym是一个高性能和高仿真的平台,可以在单个NVIDIA A100 GPU上对许多具有挑战性的模拟机器人环境进行快速训练,而以前使用传统的RL设置和纯CPU的模拟器则需要大型异构集群的CPU和GPU。此外,模拟后端也适用于学习具有接触的操作,这一点在我们用ANYmal运动和TriFinger立方体摆放进行的模拟到真实的迁移演示中得到了证实。
雷锋网雷锋网雷锋网

相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










