新火种
2023-11-01
新火种
2023-11-01 


巨量模型时代,浪潮不做旁观者:2457亿,打造全球最大中文语言模型
战鼓催征千嶂寒,阴阳交会九皋盘。
飞军万里浮云外,铁骑丛中明月边。
看到这首诗歌,有超过50%的人误以为是人类的杰作
但其实,它出自巨量模型 源1.0
经过图灵测试认证,源1.0 写诗歌、写对联、生成新闻、续写小说的能力已经让人类的平均误判率达到了50.84%。(超过30%即具备人类智能)
9月28日,浪潮人工智能研究院正式发布全球最大中文预训练语言模型“源1.0”。历时四个月研发,源1.0参数量已达2457亿,约GPT-3的1.4倍。

中国工程院院士、浪潮首席科学家王恩东表示,源1.0巨量模型旨在打造更“博学”的AI能力,未来将聚合AI最强算力平台、最优质的算法开发能力,支撑和加速行业智能转型升级,以更具备通用性的智能大模型成就行业AI大脑。
“源1.0”定位中文语言模型,由5000GB中文数据集训练而成。在国内,以中文语言理解为核心的大模型不在少数,参数规模均在亿级以上,如悟道· 文源 26 亿,阿里PLUG 270 亿;华为&循环智能「盘古」1100亿。相比之下,2457亿的 源1.0 可以说是单体模型中绝对的王者。
更值得关注的是,源1.0是业界首个挑战“图灵测试”并且使平均误判率超过50%的巨量模型。图灵测试是判断机器是否具有智能的最经典的方法。通常认为,进行多次测试后,如果人工智能让平均每个参与者做出超过30%的误判,那么这台机器就通过了测试,并被认为具有人类智能。源1.0逼近通过图灵测试,再次证明了大模型实现认知智能的潜力。
为何加入这股“浪潮”?
近几年,巨量模型在人工智能领域大行其道,BERT、GPT-3、Switch Transformer、悟道2.0相继问世,出道即巅峰,在产学各界掀起一阵阵巨浪。如今“巨量模型”一词已经成功破圈,成为全民热词。那么,人工智能遭遇了哪些瓶颈,巨量模型又带来了哪些可能性?
在会后采访中,浪潮信息副总裁、AI&HPC产品线总经理刘军表示,人工智能模型目前存在诸多挑战,当前最首要的问题是模型的通用性不高,即某一个模型往往专用于特定领域,应用于其他领域时效果不好。

也就是说,面对众多行业、诸多业务场景,人工智能需求正呈现出碎片化、多样化的特点,而现阶段的AI模型研发仍处于手工作坊式,从研发、调参、优化、迭代到应用,研发成本极高且难以满足市场定制化需求。而训练超大规模模型在一定程度上解决通用性问题,它可以被应用于翻译,问答,文本生成等等,涵盖自然语言理解的所有领域。
具体来说,从手工作坊式走向“工场模式”,大模型提供了一种可行方案:预训练+下游微调”,大规模预训练可以有效地从大量标记和未标记的数据中捕获知识,通过将知识存储到大量的参数中并对特定任务进行微调,极大地扩展了模型的泛化能力。同时大模型的自监督学习方法,使数据无需标注成为可能,在一定程度上解决了人工标注成本高、周期长、准确度不高的问题。
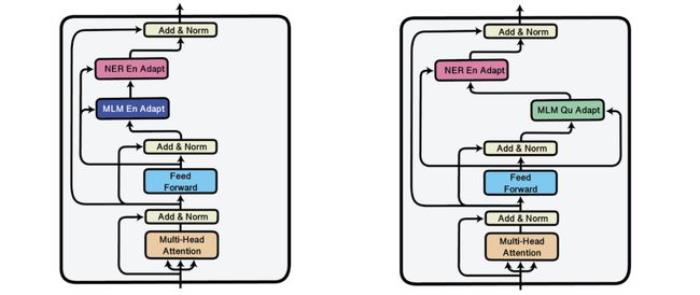
刘军解释说,大模型最重要的优势是表明进入了大规模可复制的产业落地阶段,只需小样本的学习也能达到比以前更好的能力,且模型参数规模越大这种优势越明显,不需要开发使用者再进行大规模的训练,使用小样本就可以训练自己所需模型,能够大大降低开发使用成本。
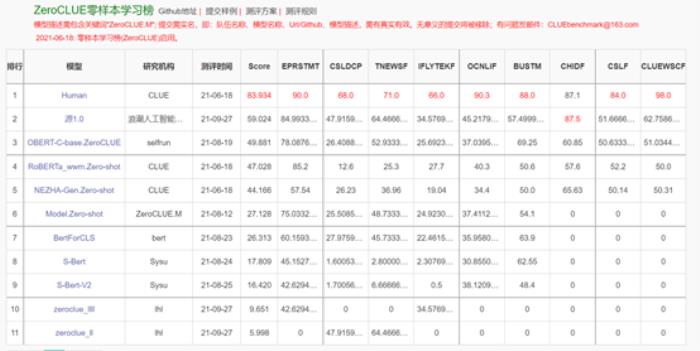
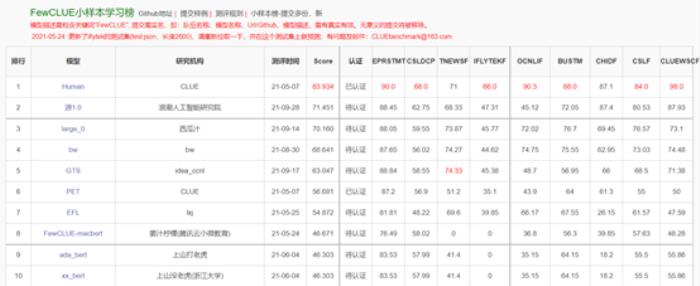
现阶段,零样本学习和小样本学习是最能衡量巨量模型智能程度的两项测试。而源1.0在CLUE基准上刷新了多项任务的SOTA。
官方数据显示:源1.0在零样本榜单中,以超越第二名18.3%的绝对优势遥遥领先。
l 在文献分类、TNEWS,商品分类、OCNLIF、成语完型填空、名词代词关系6项任务中获得冠军。
l 在小样本榜单中,文献分类、商品分类、文献摘要识别真假、名词代词关系4项任务中获得冠军。
https://www.cluebenchmarks.com/zeroclue.html
https://www.cluebenchmarks.com/fewclue.html
"面对产业AI化挑战,巨量模型在多任务泛化及小样本学习上突出能力,以及其探索深度学习的极限和实现通用智能的可能性,浪潮前瞻性的做出了开发巨量模型的重要决策"。刘军表示,浪潮源1.0大模型只是一个开始,未来源1.0将面向学术研究单位和产业实践用户进行开源、开放、共享,降低巨量模型研究和应用的门槛,推进AI产业化和产业AI化的进步,
2457亿 是如何炼成的?
大模型需要“大数据+大算力+强算法”三驾马车并驾齐驱,而对于大部分企业和机构来说,其中任意一项的研发投入都是沉重的负担,尤其是算力成本。比如1750亿参数的GPT-3单次训练需要 355 张 GPU,花费大约 2000 万美元。所以在炼大模型浪潮中,我们只看到了全球顶级的科技企业和科研机构的身影,而浪潮本潮也在其中。
浪潮 源1.0 在算力、算法和数据三个方面都做到了超大规模和巨量化。
首先是数据,浪潮创建了 5000GB 大规模的中文数据集,将近5年互联网上的内容浓缩成了2000亿词。2000亿词是什么概念?假如人一个月能读十本书,一年读一百本书,读 50 年,一生也就读 5000 本数,一本书假如 20 万字,加起来也就 10 亿字。也就是说,人类穷极一生也读不完2000亿词。
在大数据时代,比数据量更珍贵的数据质量。作为AI的底层燃料,模型对数据集质量提出了更高的要求。为此浪潮创新中文数据集生成方法,研制高质量文本分类模型,收集并清洗互联网数据过程中,有效过滤了垃圾文本,最终生成5000GB数据集可以说具备了够大、够真实、够丰富的特点。

在算法层面,源1.0大模型使用了4095PD(PetaFlop/s-day)的计算量,获得高达2457亿的参数量,相对于GPT-3消耗3640PD计算量得到1750亿参数,计算效率大幅提升;在算力层面,源1.0通过算法与算力协同优化,使模型更利于GPU性能发挥,极大的提升了计算效率,实现业界第一训练性能的同时实现业界领先的精度。
谈起浪潮很多人还是停留在初级的印象,这是一家老牌硬件厂商,每年服务器市场占有率在全球范围内高居榜首。其实浪潮也一直活跃在AI前沿方向,自2018年成立浪潮人工智能研究院以来,其异构加速计算、深度学习框架、AI算法等领域已经战绩颇丰。例如,浪潮先后推出了深度学习并行计算框架Caffe-MPI、TensorFlow-Opt、全球首个FPGA高效AI计算开源框架TF2等;此外,在全球顶级的AI赛事上已累计获得56个MLPerf全球AI基准测试冠军。有了这些深厚的AI功底,浪潮在四个月内推出全球最大巨量模型不难理解了.
对于源1.0,业内专业人士评价称,其在巨量数据、超大规模分布式训练的扩展性、计算效率、巨量模型算法及精度提升等等难题上都有所创新和提升。
源1.0 更“博学”了吗?
图灵测试一直被认为是人工智能学术界的”北极星“,也是检验机器是否具有人类智能的唯一标准。以GPT-3为代表的巨量模型出现后,机器开始在多项任务中逼近图灵测试,但直到源1.0之前,没有任何大模型突破30%的关卡。
在“源1.0”的图灵测试中,将模型生成的对话、小说续写、新闻、诗歌、对联与由人类创作的同类作品进行混合并由人群进行分辨,测试结果表明,人群能够准确分辨人与“源1.0”作品差别的成功率已低于50%。
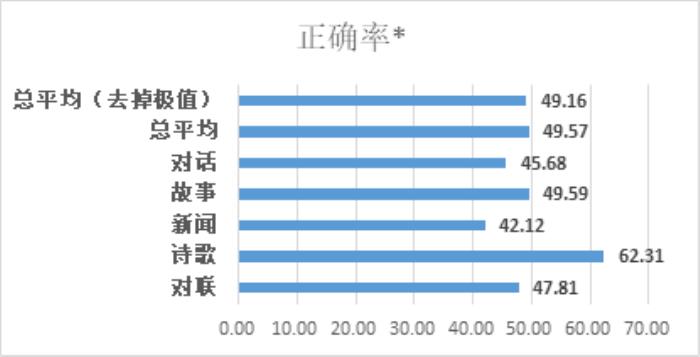
如图,受访者的平均误判率为50.84%,在新闻生成领域误判率高达57.88%。
而抛开数据,源1.0的诗歌、对联的作品确实让人惊艳
五湖四海皆春色,三江八荒任我游
春来人入画,夜半月当灯
和风吹绿柳,细雨润青禾
三江顾客盈门至,四季财源滚滚来.
疑是九天有泪,
为我偷洒。
滴进西湖水里,
沾湿一千里外的月光,
化为我梦里的云彩。
巨量模型的潜力
炼大模型热潮的兴起,离不开谷歌微软、OpenAI、智源研究院等全球顶级科技企业和研发机构的追逐和热捧,在它们看来,巨量模型代表了实现通用人工智能最具潜力的路径,代表了当前传统产业实现智能化转型的新机遇.
而这次,浪潮重磅发布中文单体大模型源1.0,通过图灵测试和小样本学习能力再次印证了业界对超大模型潜力的普遍期望. 前者为模型推理\走向认知智能提供了可能性,后者降低了不同场景的适配难度,提升了模型的泛化应用能力。相信未来这股"浪潮"还会越来越汹涌.
雷锋网雷锋网雷锋网

相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。