

 新火种
2023-10-31
新火种
2023-10-31 


llama.cpp作者创业,用纯C语言框架降低大模型运行成本
通常,神经网络的推理代码是使用 Python 语言编写的。但相比于 Python,C/C++ 代码运行速度更快,编写过程更严谨,因此一些开发者尝试用 C/C++ 语言实现神经网络。
在众多使用 C/C++ 语言编写神经网络代码的开发者中,Georgi Gerganov 是一位佼佼者。Georgi Gerganov 是资深的开源社区开发者,曾为 OpenAI 的 Whisper 自动语音识别模型开发 whisper.cpp。

Georgi Gerganov
今年 3 月 Georgi Gerganov 又构建了开源项目 llama.cpp,llama.cpp 让开发者在没有 GPU 的条件下也能运行 Meta 的 LLaMA 模型。llama.cpp 让开发者在没有 GPU 的条件下也能运行 LLaMA 模型。项目发布后,很快就有开发者尝试并成功在 MacBook 和树莓派上运行 LLaMA。
打开 Georgi Gerganov 的个人主页,我们发现全是开源项目,满满的干货。
现在,Georgi Gerganov 宣布创立一家新公司 ggml.ai,旨在支持 ggml 的开发。ggml 是 Georgi Gerganov 使用 C/C++ 构建了机器学习张量库,能够帮助开发者在消费级硬件上实现大模型,并提升模型性能。ggml 张量库具有以下特点:
用 C 语言编写;
支持 16bit 浮点数;
支持整数量化(包括 4 位、5 位、8 位);
自动微分;
内置优化算法(例如 ADAM、L-BFGS);
为 Apple 芯片设置特定优化;
在 x86 架构上使用 AVX / AVX2 Intrinsic;
通过 WebAssembly 和 WASM SIMD 提供 Web 支持;
无第三方依赖;
运行时零内存分配;
支持指导型语言输出。
作为纯 C 语言编写的框架,ggml 大幅降低了大模型的运行成本。llama.cpp 和 whisper.cpp 都使用了 ggml,我们来看一下使用 llama.cpp 和 whisper.cpp 的例子。
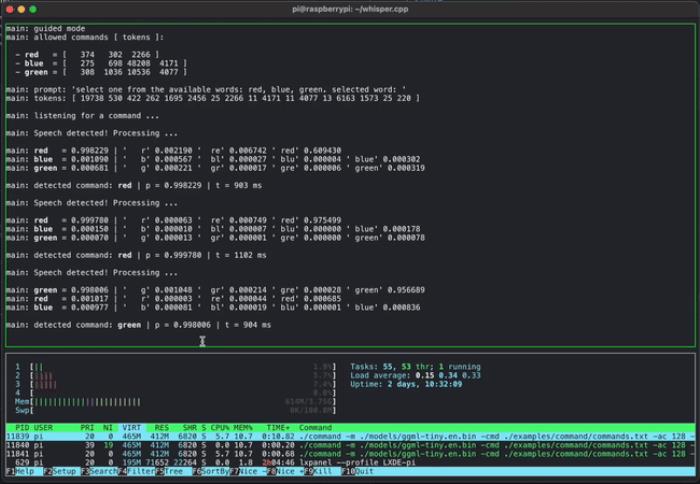
下图是一个在树莓派上使用 whisper.cpp 检测短语音命令的例子:
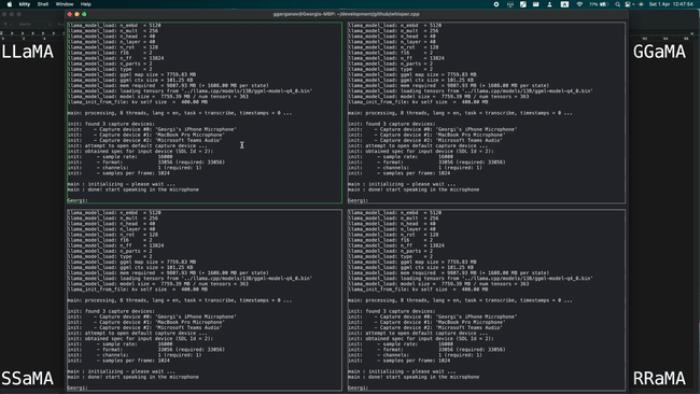
在单个 M1 Pro 上同时运行 LLaMA-13B + Whisper Small 的 4 个实例,如下图所示:
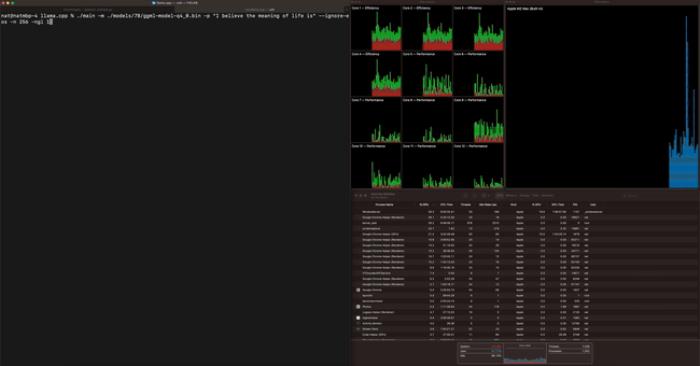
在 M2 Max 上以 40 tok/s 的速度运行 LLaMA-7B,如下图所示:
总体来说,ggml 让本地运行大型语言模型变得更容易,操作更便捷。Georgi Gerganov 成立新公司之后,简单高效的 ggml 张量库将获得更多开发者和投资者的支持。我们相信随着开发人员在技术层面做出努力,大模型的应用前景将会越来越广泛。
参考链接:http://ggml.ai/
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










