新火种
2023-10-31
新火种
2023-10-31 


对话推荐系统的进展与五个关键挑战

作者|谢明辉
推荐系统旨在从用户的交互历史识别出用户的偏好,目前已经在工业界得到广泛应用。但是传统静态推荐模型难以解决两个重要的问题。1,用户到底喜欢什么?2,为什么用户喜欢一个物品?因为静态的推荐模型缺乏用户的实时反馈和显式指导。
近年来,对话推荐系统正在逐渐解决这两个问题。在对话推荐系统中,系统能够通过自然语言和用户进行动态交互,能识别出用户的精确偏好。虽然对话推荐系统(conversational recommender systems)已经得到一些发展,但是远没成熟。(下文CRS指对话推荐系统)
该篇文章将首先介绍对话推荐系统,然后总结CRS中5个关键挑战:
1,基于问题的用户偏好识别。
2,多轮对话的策略。
3,对话理解和生成。
4,Exploration-exploitation trade-offs。
5,评估和用户模拟。文章还对未来有前景的方向进行了展望。
论文链接(已收录于AI open):https://www.aminer.cn/pub/600fe40f91e011256c955f6a
介绍
对话推荐系统的定义
A recommendation system that can elicit the dynamic preferences of users and take actions based on their current needs through real-time multi-turn interactions.
一个有关对话推荐系统的简单举例如下:
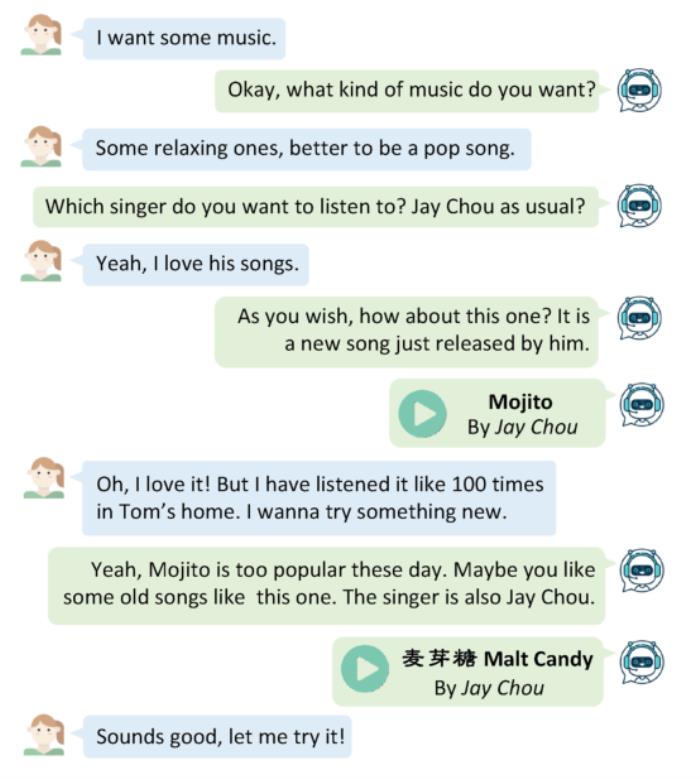
根据用户之前的偏好(喜欢周杰伦的歌),系统进行了推荐。当用户实时反馈后,系统能够轻松的提供新的推荐结果,来满足用户。
通常,CRS由用户交互接口、对话策略模块、推荐引擎三部分组成。用户接口作为用户和机器的交互接口,从用户的对话中提取信息,转化为机器可理解的表示;对话策略模块是CRS的大脑,负责决定识别用户偏好、维持多轮对话和带领话题;推荐引擎负责建模实体间的关系,学习用户偏好,从物品和它的属性中提取信息。CRS的5个关键挑战对应了通用框架中的模块。
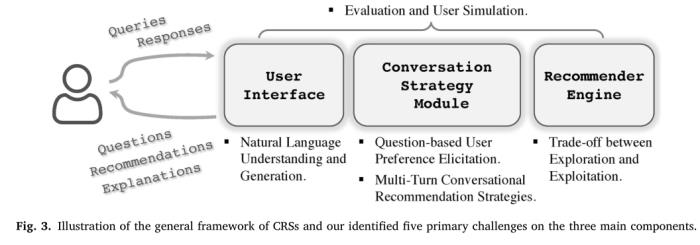
CRS的挑战
5个关键挑战和对应的经典方法,如下图。

基于问题的用户偏好识别
基于问题的偏好识别是通过向用户询问物品或者物品的属性识别出用户的偏好。
询问物品
传统的推荐系统直接向用户询问物品本身,在此基础上,添加与用户的自然语言交互接口,成为对话推荐系统。
基于选择的方法
让用户从待选列表中选择自己喜欢的物品。用户选择偏爱的物品之后,系统根据用户的选择更新推荐。尽可能让候选物品不同。
基于交互推荐的方法
交互推荐主要基于RL;一些研究者将多臂机(MAB)算法应用到CRS;一是因为MAB算法高效,且天然适合对话场景;二是MAB算法能够探索出用户可能喜欢但是从来没有尝试的物品;但基于MAB的算法通常假设用户的偏好在交互过程中保持不变。为了建模动态的偏好和长期效用utility,一些研究者提出了将DQN(Deep Q-network)和DDPG(deep deterministic
通过直接向用户询问物品来对用户喜好进行建模的方式效率低,因为候选集合往往很大。而且在真实的CRS中,用户在对话轮数多了之后,就会无法忍受。所以更为实际的方法是询问用户喜欢什么属性。现在的研究热点集中在基于询问属性的方法。
询问属性
该方法的基本假设是,如果用户喜欢一个物品,那么他也喜欢用户的属性。
询问属性的方法更有效,因为用户是否喜欢某个属性能够很大程度上减少推荐的候选物品数。该方法的关键在于如何选择一系列属性对用户进行询问,来最小化当前用户的需求的不确定性。另外,每次都询问用户,具有最大不确定程度喜欢的属性,而不会询问已经喜欢或不喜欢的属性。
从历史交互中拟合模式
一个经典工作,Christakopoulou等人在2018年提出的question & recommendation模型。每轮系统让用户选择一个或多个不同的话题,如NBA,美食等,然后从这些话题中选择物品推荐给用户。模型包含了trigger模块,来决定是否询问属性,或者做推荐。这个算法已经在YouTube部署,用来解决用户冷启动问题。类似的模型都使用预先设定好的对话末班,因为核心人物是推荐,而非NLG。另外这些模型只是从历史信息学习用户偏好,没有考虑当用户拒绝推荐结果后的回应。
减小不确定性基于评价的方法:传统的方法通过删除不满足的属性,来缩小候选物品范围。基于神经网络向量的方法,将评价编码为隐向量,用来表示物品可解释的属性。Wu等人在2019年提出了一种针对平阿基的可解释的CF方法。他们使用NFC模型将用户i对物品j的偏好编码成隐向量\hat z_{i,j},然后使用\hat z_{i,j}计算出打分\hat r_{i,j}和可解释的属性向量\hat s_{i,j}.当用户不喜欢某个属性时,系统将对应的属性向量\hat s_{i,j}对应的维度设置为0。然后更新隐向量。
基于RL的方法
借助deep policy network,系统不仅选择属性并且控制什么时候转移话题。
图限制的候选实体(Graph-constrained Candidates)
图经常用来表示不同实体之间的关系。Lei等人在2020年提出一种在异构图进行交互的路径推理算法。用户和物品表示为节点,关系表示为节点之间的边。对话可以转化为图上的路径。作者比较不同属性之间的偏好,选择最不确定的属性进行询问。用户对某个物品的偏好建模为用户对属性偏好的均值。利用图信息能充分减小搜索空间。其他一些方法使用GNN类似的方法。
多轮对话的技巧
问题驱动的方法关注“问什么”,而多轮对话主要关注“什么时候问”或者“怎么维持对话”。
何时问、何时推荐
在交互中使用好的策略,对提升用户体验很关键。Zhang等人在2018年提出SAUR模型。当对用户需求置信度较高时,trigger会激活推荐模块。在这里,trigger是在所有候选实体打分上的sigmoid值。但是,这种控制策略过于简单。Sun等人在2018年提出CRM模型,模型使用belief tracker对用户输出进行追踪,然后输出表示目前会话状态的隐向量。然后将其输入到deep policy网络中决定什么时候进行推荐。DPN使用policy gradient方法做决策。
更广泛的对话技巧
之前的技巧仍缺乏智能。原因之一是,大多数CRS模型假设用户总是知道他们想要什么,然后模型学习到用户的偏好。但用户有时候都不清楚他们想要什么,所以CRS还需要指引话题,并且影响用户的心理。一些研究尝试让CRS能够让话题更具吸引力,让用户有参与感。
多话题学习(Multi-topic learning in conversations)
Liu等人在2020年提出了多类型对话的任务。他们提出的模型能够在不同类型对话切换,如从闲聊式对话切换到推荐式对话。他们提出了multi-goal driven conversation generation (MGCG) 框架,包含了一个goal planning module和a goal-guided responding module。前者将推荐作为主要目标,将话题转移作为短期目标。给定上下文X,和最后一轮的目标g_{t-1},模型转移到目标g_t的概率为P_{CG}(g_t \neq g_{t-1}),若概率值大于0.5,则转移。否则,保持不变。针对特定任务的数据集非常重要。Liu等人在2020年发布了一个多类型交互的数据集DuRecDial。zhou等人在2020年发布了一个话题引导的数据集。
特殊能力(Special ability: suggesting, negotiating, and persuading)
除了偏好识别和推荐,还有各种各样的任务需要CRS具有不同的能力。这些能力都是高级需求。例如,当用户询问“Nissan GTR Price”,系统能够提供一些建议帮助yoghurt完成一个任务,比如"How much does it cost to lease a Nissan GT-R?".这些问题建议可以使用户带来各种各样的未来结果的沉浸式搜索体验。Lewis等人在2017年提出一个能和用户进行谈判的系统。他们将问题建模为分配问题:物品需要分配给两人,每个物品对于每个人的价值不同。两人进行谈判,达成一个分配的协议。
Dialogue understanding and generation
对话理解
大部分CRS主要关注的是核心的推荐逻辑和多轮对话技巧,它们难以从原始对话中提出用户意图,它们需要预处理的结构化的输入,如打分、YES/NO问题。而实际情况,用户的回答或提问往往多种多样。对话理解方法有槽填充(Slot filling),和意图识别。槽填充(Slot filling)事先设定意图,使用模型根据用户输入填写模板的相应空值。意图识别常用神经网络从用户的对话中提取情感。
Response generation
CRS生成的回答至少要满足两个层次的要求。低层次的要求是生成的回答合适且正确;高层次的要求是生成的回答包含推荐物品有价值的信息。主要分为Retrieval-based Methods和Generation-based Methods
Retrieval-based Methods
基于抽取的方法主要做法是从候选回答中挑选合适的作为回答。问题被建模成用户问题和候选回答的匹配问题。一种方法是,使用神经网络分别学习用户问题和候选答案的表示,然后通过一个打分函数,得到两者的匹配程度;另一种方法是,先融合两者的表示,然后通过模型学习两者的深层关系。两种方法各有利弊,前者实现更高效,更适合线上部署;后者更有效,因为匹配信息被深层次的挖掘。
Generation-based Methods
基础的生成模型是RNN,能够输入问题,逐个单词生成回答。相较于基于抽取的方法,基于生成的方法有以下挑战:
1,生成的答案可能不是有正确语法的语句。
2,人们容易区分出机器生成的语言和人类生成的语言,因为机器缺乏基本的常识、情感等。
3,模型倾向于生成安全回答,也就是一些放之四海皆准的回答,如"OK";4,如何评价生成的回答。对于CRS,生成的回答需要包含推荐物品。
Incorporating recommendation-oriented information
使用端到端框架的CRS的主要缺点是,只有在训练过程中出现的物品才会被推荐。因此,模型性能被训练数据的质量严重限制。为此,Chen等人在2019年提出将领域知识图谱融入到推荐系统中,一方面可以帮助推荐系统从知识图谱中提取信息,另一方面,可以帮助对话系统生成识别出与物品相关的词汇,生成更连续和可解释的回答。
另外还有些研究者尝试增加回答的多样性和可解释性,比如前面提到的多话题学习模型。
Exploration-exploitation trade-offs
Exploration-Exploitation (E&E) trade-off主要被用于解决CRS的冷启动问题,通过Exploitation,系统返回最流行的选择;通过探索,模型尝试搜集一些未知选项的信息。MAB多臂机算法是E&E一个经典算法,主要用来改善模型的推荐效果。
多臂机介绍
多臂机问题来源于赌博。老虎机有K个摇臂,每个摇臂以一定的概率吐出金币,且概率是未知的 。玩家每次只能从K个摇臂中选择其中一个,且相邻两次选择或奖励没有任何关系。玩家的目的是通过一定的策略使自己的奖励最大。用户可以选择当前具有最大平均奖励的摇臂,或者冒险尝试另一个摇臂。
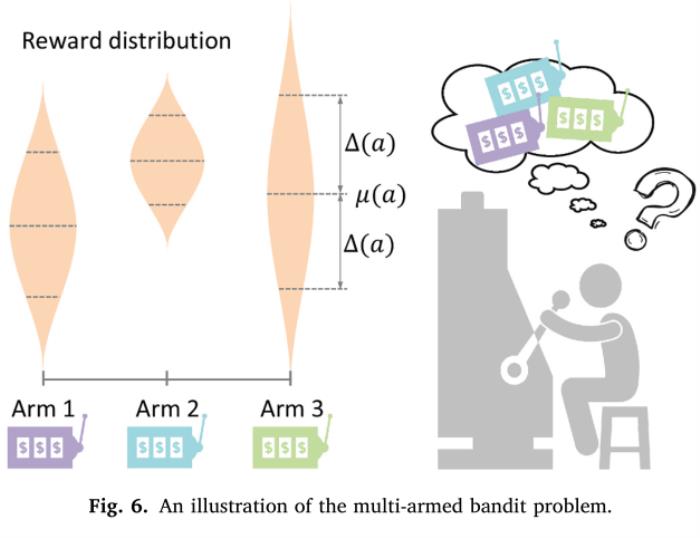
多臂机在CRS的应用
待推荐的物品可以看做MAB中的摇臂,系统可以选择当前用户偏好的物品,也可以冒险尝试用户未知偏好的物品。传统MAB方法将物品看做相互独立的,并且忽略了物品特征信息,如属性。Li等人提出了第一个使用文本信息的多臂机算法,类似于协同过滤算法,利用了用户和物品的特征信息。
多臂机算法能够在线学习,几轮交互之后便能更新用户的偏好,调整对话策略。
Evaluate CRSs
对CRS的评价分为两类。第一类是Turn-level的评价,评估每轮的输出,是一个监督预测问题;第二类是Conversation-level的评价,评估多轮对话的技巧,是一个序列决策问题。
数据集和工具
常用CRS数据集
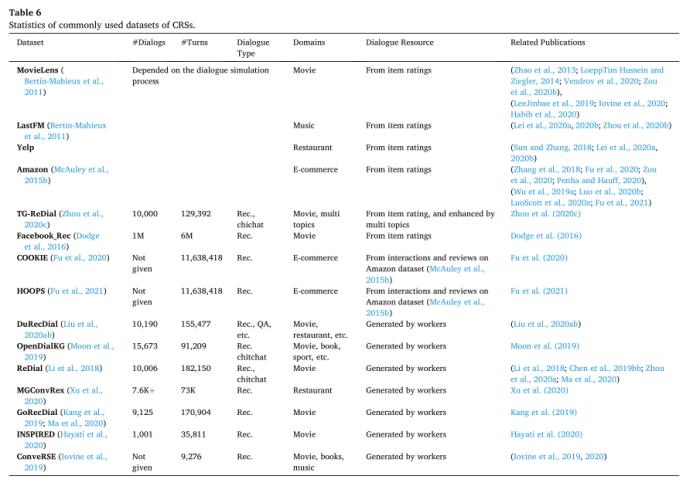
虽然数据集数量较多,但是仍不足以开发能够工业应用的CRS。除了数据集规模过小,还有就是数据集比较有规则,难以适应真实世界的复杂情况。
常用工具
zhou等人实现了开源工具包,CRSLab。工具包包含了三个子任务:推荐,对话,策略,对应了CRS的三个部分。一些模型通过这三个任务实现。工具包还包含评估模块,不仅能够进行自动评估,还能通过交互接口进行人工评估。
Turn-level evaluation
语言生成的评价
两个常用指标是BLEU和Rougue。BLEU衡量的是生成词的准确率,即生成的词有多少出现在了正确答案上。Rougue衡量的是生成词的召回率,正确答案的词在生成回答中出现了多少。但是这两个指标是否能够有效评价语言生成任务具有争议,因为这两个指标只能评价词汇变化,不能评价语义和语法上的变化。另外,CRS模型的任务不是预测最可能的回答,而是对话的长期有效。所以,其他的一些指标,如多样性、连续性,反映了用户的满意程度可能更加适合评估CRS。
推荐的评价
推荐系统评价分为基于评分和基于排序的评价。基于评分的评价中,用户反馈是评分,如1-5分。常用的评价指标有MSE和RMSE;基于排序的评价中,用户反馈可以是隐式的点击,购买等操作。只需预测物品的相对顺序即可,在实际情况更常用。常见的基于排序的指标有点击率、F1分数,MRR、MAP等。
Conversation-level evaluation
不同于Turn-level evaluation,Conversation-level evaluation没有中间的监督信号。因此需要在线用户或者利用历史数据进行用户模拟。
在线用户测试可以直接根据用户的真实反馈进行评价。常用的指标有,平均轮数(AT)和recommendation
success rate (SR@t)。平均轮数(AT)指系统为了成功完成推荐所需对话轮数,而SR@t是指有多少对话在第t轮完成了推荐。Off-policy evaluation也称为反事实推理。问题会设计成反事实问题,比如,如果我们用\pi_{\theta}代替\pi_{\beta},会发生什么?
用户模拟通常有4个技巧:
1,直接使用用户的交互历史。将人类交互数据集的一部分作为测试数据集。
2,估计用户在所有物品的偏好。由于数据集中包含的物品有限,数据集之外的物品往往被视为不喜欢的物品。为此,最好是估计用户在所有物品的偏好。给定物品和它的信息,模拟用户在该物品上的偏好。
3,从所有用户的评价抽取。除了用户行为之外,许多电商平台包含很多文本评价数据,物品的评价会显式地提及物品的属性,能够反映用户在该物品上的偏好。但是,物品的缺点并不能解释用户为何购买该物品,因此只有积极的评价,才会被认为用户选择该物品的原因。
4,模拟人类对话的语料;CRS根据真实的人类对话数据作为训练,学习模拟人类的能力。
未来展望
联合训练三个子任务
CRS的三个子任务推荐、自然语言处理和生成任务、对话技巧通常被单独研究。但是这三个子任务共享一些实体和数据。比如,用户的评价包含丰富的语义信息,但是只会给推荐引擎观点信息。
偏差
推荐系统包含各种偏差,比如 popularity bias,conformity bias等。这些偏差可以在与用户交互过程中消除,因为CRS可以直接询问用户关于流行物品的属性,而不像传统推荐系统直接向用户推荐大家都喜欢的物品。exposure bias会导致用户只能持续消费推荐系统曝光的物品。
复杂多轮对话技巧
目前的对轮对话的技巧过于简单。有些工作是基于手工设计的函数决定何时询问,何时推荐。有些基于DL的工作甚至没有显式的管理多轮对话的模块。有些工作是基于强化学习,但是在设计动作、状态、奖励方面还有较大的改进空间。
另外,引入外部知识也可以改进CRS。物品的属性信息和知识图谱中丰富的语义信息都可以帮助CRS建模用户偏好。多模态数据也可以引入到之前基于文本的CRS,提供全新维度的信息。
更好的评估和用户模拟
CRS的评估需要用户的实时反馈,但是代价昂贵。绝大多数CRS模拟用户,但是并不能完全达到真实用户的效果。一些可行的方向包括构建频繁的用户交互,在slate推荐中建模用户的选择行为。
关于AI OpenAI Open是一个可自由访问的平台,所有文章都永久免费提供给所有人阅读和下载。该期刊专注于分享关于人工智能理论及其应用的可行性知识和前瞻性观点,欢迎关于人工智能及其应用的所有方面的研究文章、综述、评论文章、观点、短篇交流和技术说明。AI Open将作为中国面向国际人工智能学术、产业界的交流渠道,传播人工智能的最新理论、技术与应用创新,提高我国人工智能的学术水平和国际影响力。AI Open目前已被DOAJ收录,目前累计下载量已经达到6w+,乐观预计1年内能进入SCI。

相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章