新火种
2024-11-18
新火种
2024-11-18 



清华光学AI登Nature!物理神经网络,反向传播不需要了
用光训练神经网络,清华成果最新登上了Nature!
无法应用反向传播算法怎么办?
他们提出了一种全前向模式(Fully Forward Mode,FFM)的训练方法,在物理光学系统中直接执行训练过程,克服了传统基于数字计算机模拟的限制。

简单点说,以前需要对物理系统进行详细建模,然后在计算机上模拟这些模型来训练网络。而FFM方法省去了建模过程,允许系统直接使用实验数据进行学习和优化。
这也意味着,训练不需要再从后向前检查每一层(反向传播),而是可以直接从前向后更新网络的参数。
打个比方,就像拼图一样,反向传播需要先看到最终图片(输出),然后逆向一块块检查复原;而FFM方法更像手中已有部分完成的拼图,只需按照一些光原理(对称互易性)继续填充,而无需回头检查之前的拼图。

这样下来,使用FFM优势也很明显:
一是减少了对数学模型的依赖,可以避免模型不准确带来的问题;二是节省了时间(同时能耗更低),使用光学系统可以并行处理大量的数据和操作,消除反向传播也减少了整个网络中需要检查和调整的步骤。
论文共同一作是来自清华的薛智威、周天贶,通讯作者是清华的方璐教授、戴琼海院士。此外,清华电子系徐智昊、之江实验室虞绍良也参与了这项研究。
消除反向传播
一句话概括FFM原理:
将光学系统映射为参数化的现场神经网络,通过测量输出光场来计算梯度,并使用梯度下降算法更新参数。
简单说就是让光学系统自学,通过观察自己如何处理光线(即测量输出光场)来了解自己的表现,然后利用这些信息来逐步调整自己的设置(参数)。
下图展示了FFM在光学系统中的运行机制:
其中a为传统设计方法的局限性;b为光学系统的组成;c为光学系统到神经网络的映射。
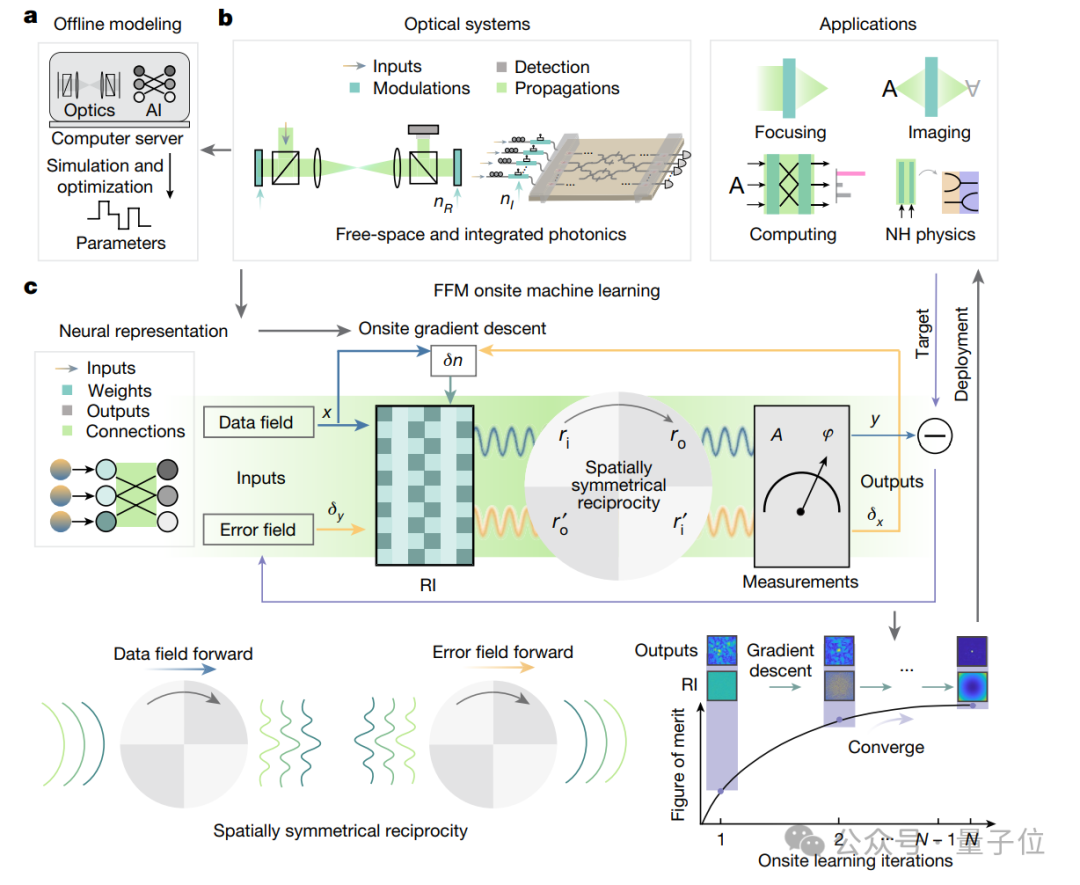
展开来说,一般的光学系统(b),包括自由空间透镜光学和集成光子学,由调制区域(暗绿色)和传播区域(浅绿色)组成。在这些区域中,调制区域的折射率是可调的,而传播区域的折射率是固定的。
而这里的调制和传播区域可以映射到神经网络中的权重和神经元连接。
在神经网络中,这些可调整的部分就像是神经元之间的连接点,可以改变它们的强度(权重)来学习。
利用空间对称互易性原理,数据和误差计算可以共享相同的前向物理传播过程和测量方法。
这有点像镜子里的反射,系统中的每个部分都能以相同的方式响应光的传播和错误反馈。这意味着无论光如何进入系统,系统都能以一致的方式处理它,并根据结果来调整自己。
这样,可以在现场直接计算梯度,用于更新设计区域内的折射率,从而优化系统性能。
通过现场梯度下降方法,光学系统可以逐步调整其参数,直至达到最优状态。
原文将上述全前向模式的梯度下降方法(替代反向传播)用方程最终表示为:
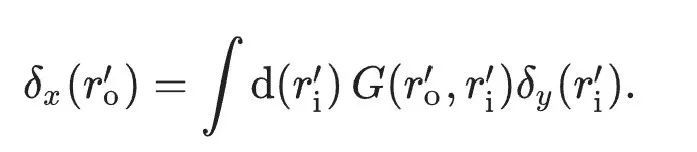
一种光学神经网络训练方法
作为一种光学神经网络训练的方法,FFM有以下优势:
与理想模型相当的准确率
使用FFM可以在自由空间光学神经网络(Optical Neural Network,ONN)上实现有效的自训练过程。
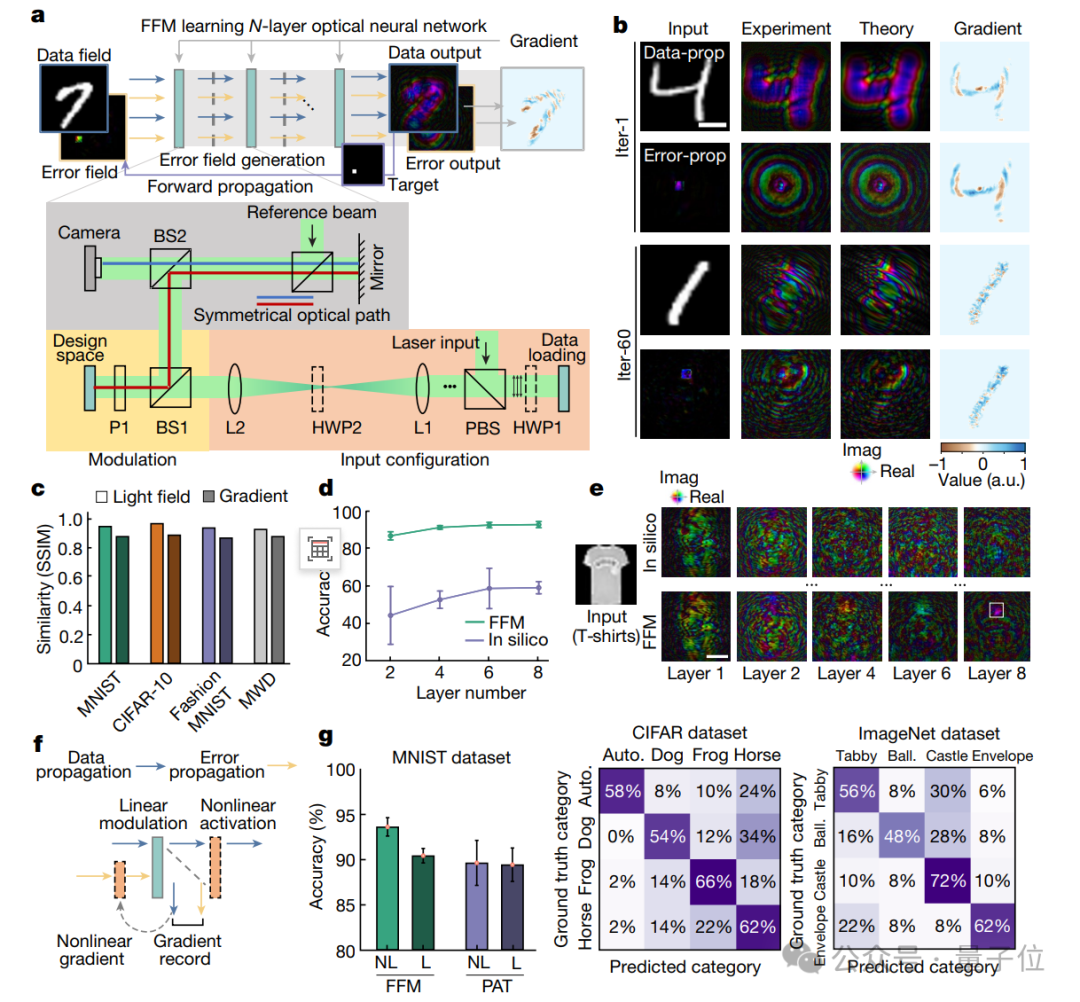
要说明这个结论,研究人员首先用一个单层的ONN在基准数据集上进行了对象分类训练(a)。
具体来说,他们用了一些手写数字的图片(MNIST数据集)来训练这个系统,然后将结果进行了可视化(b)。
结果显示,通过FFM学习训练的ONN在实验光场与理论光场之间相似性极高(SSIM超过0.97)。
换句话说,它学习得非常好,几乎能够完美复制给它的示例。
不过研究人员也提醒:
由于系统存在的不完美之处,理论上计算出的光场和梯度无法完全准确地反映实际物理现象。
接下来,研究人员用更复杂的图片(Fashion-MNIST数据集)来训练系统识别不同的时尚物品。
一开始,当层数从2层增加到8层,计算机训练网络的平均准确度几乎只有理论准确度的一半。
而通过FFM学习方法,系统的网络准确度提升到92.5%,接近理论值。
这表明了,随着网络层数的增加,传统方法训练的网络性能下降,而FFM学习能够维持高精度。
同时,通过将非线性激活纳入FFM学习,可以进一步提升ONN的性能。在实验中,非线性FFM学习能够将分类准确率从90.4%提高到93.0%。
研究进一步证明,通过批量训练非线性ONN,错误传播过程可以被简化,并且训练时间仅增加1到1.7倍。
高分辨率的聚焦能力
FFM在实际应用中也能实现高质量的成像,即使在复杂的散射环境中也能达到接近物理极限的分辨率。
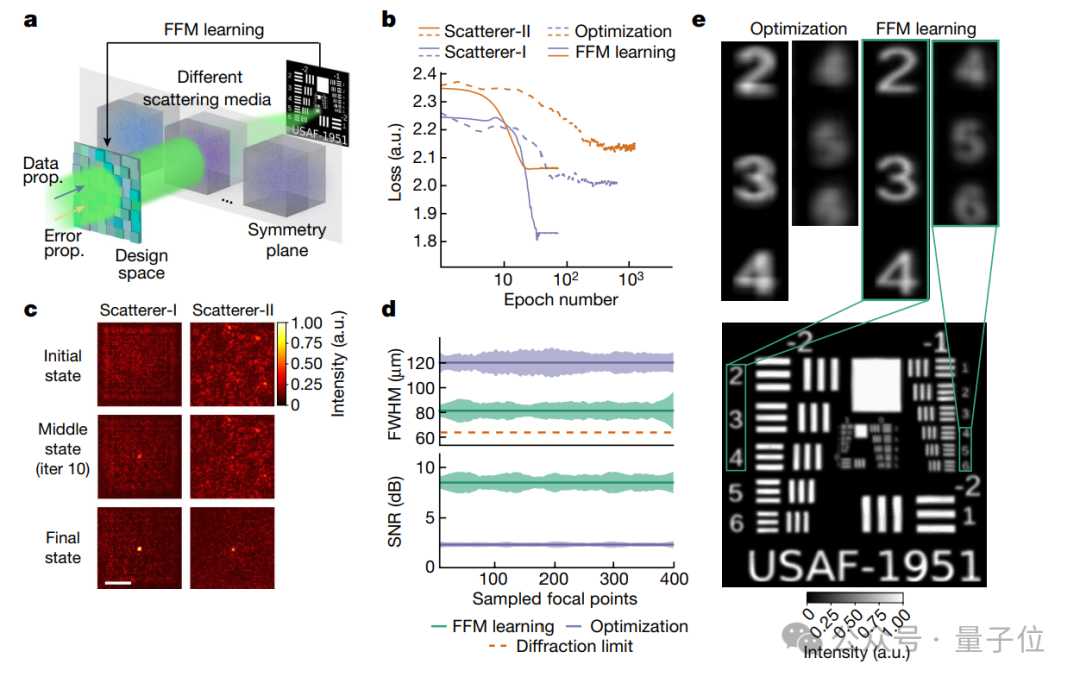
首先,当光波进入散射介质(如雾、烟或生物组织等),聚焦会变得复杂,不过光波在介质中的传播往往保持一定的对称性。
FFM就利用了这种对称性,通过优化光波的传播路径和相位,以减少散射效应对聚焦的负面影响。
其效果也很显著,图b展示了FFM与PSO(粒子群优化)这两种优化方法的对比。
具体来说,实验采用了两种散射介质,一种是随机相位板(Scatterer-I),另一种是透明胶带(Scatterer-II)。
在这两种介质中,FFM仅经过25次设计迭代就实现了收敛(更快找到优化解),收敛损失值分别为1.84和2.07(越低性能越好)。
而PSO方法需要至少400次设计迭代才能达到收敛,且在最终收敛时的损失值为2.01和2.15。
同时,图c展示了FFM能够不断自我优化,它设计的焦点从最初的随机分布逐渐演化和收敛到一个紧密的焦点。
在3.2 mm × 3.2 mm的设计区域内,研究人员进一步对FFM和PSO优化的焦点进行了均匀采样,并比较了它们的FWHM(半峰全宽)和PSNR(峰值信噪比)。
结果显示,FFM聚焦精度更高,成像质量更好。
图e进一步评估了设计的焦点阵列在扫描位于散射介质后面的分辨率图时的性能。
结果令人惊喜,FFM设计的焦点尺寸接近64.5 µm的衍射极限,这是光学成像理论上的最高分辨率标准。
能够并行成像视线之外的物体
既然在散射介质中如此厉害,研究人员又尝试了非视距(NLOS)场景,即物体被隐藏在视线之外的地方。
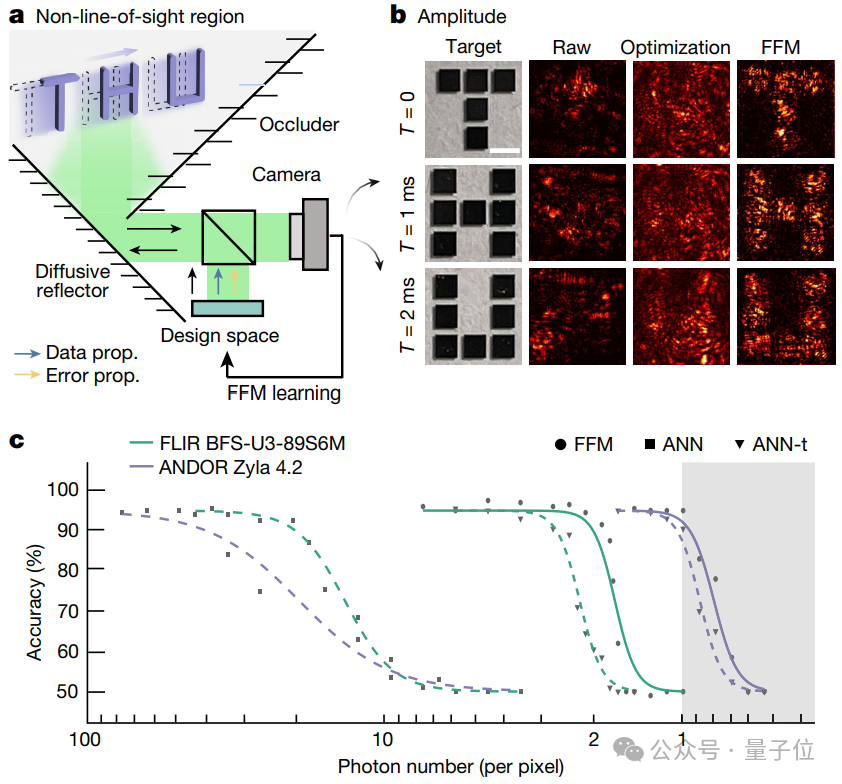
FFM利用了从隐藏物体到观察者之间光路的空间对称性,这允许系统通过全光学的方式在现场重建和分析动态隐藏物体。
通过设计输入波前,FFM能够同时将物体中的所有网格投影到它们的目标位置,实现隐藏物体的并行恢复。
实验中使用了字母形状的隐藏铬靶“T”、“H”和“U”,并设置了曝光时间(1毫秒)和光功率(0.20 mW),以实现对这些动态目标的快速成像。
结果显示,没有FFM设计的波前,图像会严重扭曲。而FFM设计的波前能够恢复所有三个字母的形状,SSIM(结构相似性指数)达到1.0,表明与原始图像的高度相似性。
进一步,与人工神经网络(ANN)在光子效率和分类性能方面相比,FFM显著优于ANN,尤其是在低光子条件下。
具体而言,在光子数量受限的情况下(如许多反射或高度漫射的表面),FFM能够自适应地纠正波前畸变,并需要更少的光子来进行准确分类。
在非Hermitian系统中自动搜索异常点
FFM方法不仅适用于自由空间光学系统,还可以扩展到集成光子系统的自我设计。
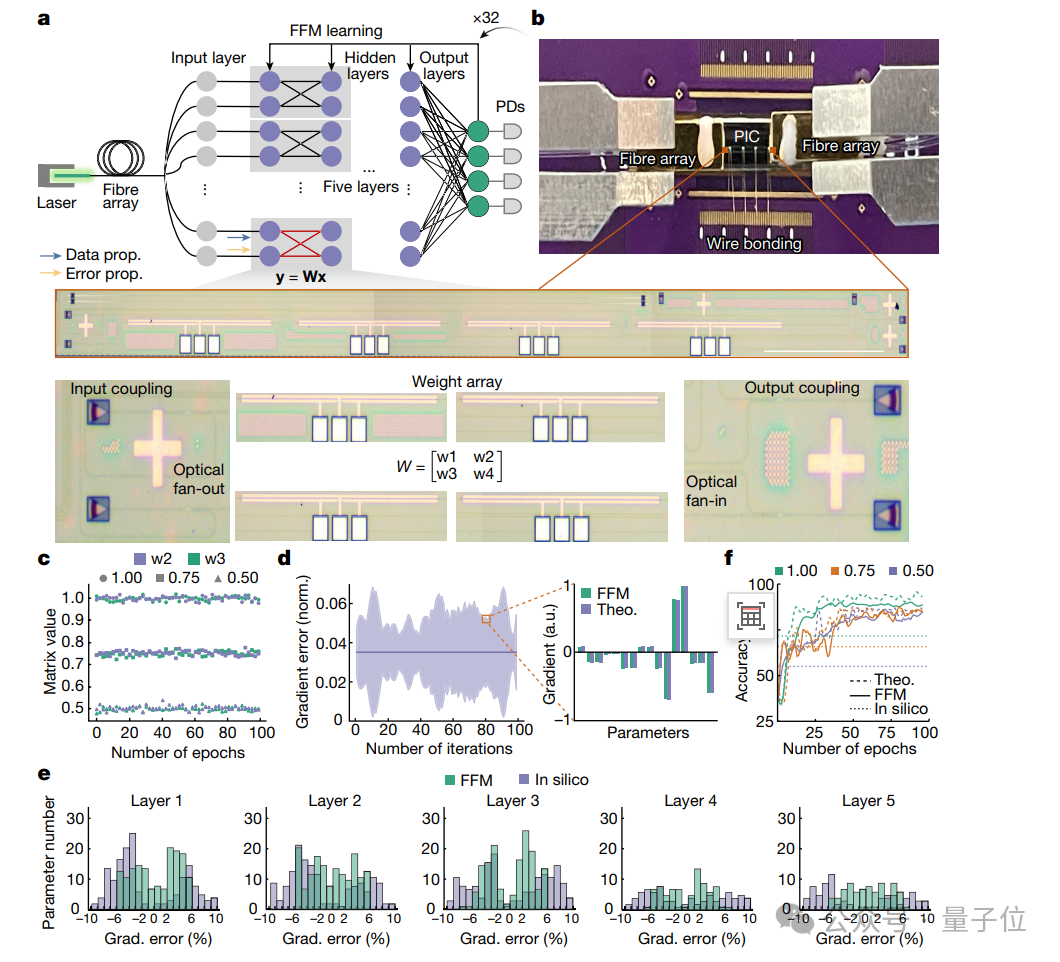
研究人员使用串联和并联配置的对称光子核心,构建了一个集成神经网络(a)。
实验中,对称核心通过不同水平的注入电流配置了可变光衰减器(VOA),实现了不同的衰减系数,以模拟不同的权重。
在图c中,对称核心中编程矩阵值的保真度非常高,时间漂移的标准偏差分别为0.012%,0.012%和0.010%,表明矩阵值非常稳定。
并且,研究人员可视化了每层的误差。对比实验梯度与理论模拟值,其平均偏差为3.5%。
在大约100次迭代(epoch)后,网络达到了收敛状态。
实验结果显示,在三种不同的对称比例配置下(1.0、0.75或0.5),网络的分类准确度分别为94.7%、89.2%和89.0%。
而使用FFM方法的神经网络,得到的分类准确度为94.2%、89.2%和88.7%。
相比之下,如果使用传统的计算机模拟方法来设计网络,实验的分类准确度会低一些,分别为71.7%、65.8%和55.0%。
最后,研究人员还展示了FFM可以自我设计非厄米特系统,通过数值模拟,无需物理模型即可实现对特异点的遍历。
非厄米特系统是物理学中的一个概念,它涉及到量子力学和光学等领域中的系统,这些系统不满足厄米特性(Hermitian)条件。
厄米特性与系统的对称性和能量的实数性有关,非厄米特系统则不满足这些条件,它们可能具有一些特殊的物理现象,比如特异点(Exceptional Points),这是系统的动力学行为在某些点上会发生奇异变化的地方。
总结全文,FFM是一种在物理系统上实现计算密集型训练过程的方法,能够高效并行执行大多数机器学习操作。
更多详细实验设置、数据集准备过程,欢迎查阅原文。
— 完 —
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。