

 新火种
2023-10-30
新火种
2023-10-30 


观察|大模型潮即将耗尽全宇宙文本,高质量数据从哪里来?
·专家警告,ChatGPT等人工智能驱动的机器人可能很快就会“耗尽宇宙中的文本”。同时,用AI生成的数据“反哺”AI或造成模型崩溃。未来模型训练使用的高质量数据可能会愈来愈昂贵,网络走向碎片化和封闭化。
·“当大模型发展走向更深度,比如行业大模型,所需的数据就不是互联网免费公开的数据了,要训练出精度极高的的模型,需要的是行业专业知识,甚至商业机密类型的知识。要让大家贡献这样的语料库,肯定需要有一种权益分配机制。”
作为人工智能基础设施的“三驾马车”之一,数据的重要性一直不言而喻。随着大语言模型热潮进入高峰期,业界对数据的关注度前所未有。
7月初,加州大学伯克利分校计算机科学教授、《人工智能——现代方法》作者斯图尔特·罗素(Stuart Russell)发出警告称,ChatGPT等人工智能驱动的机器人可能很快就会“耗尽宇宙中的文本”,通过收集大量文本来训练机器人的技术“开始遇到困难”。研究机构Epoch估计,机器学习数据集可能会在2026年前耗尽所有“高质量语言数据”。
“数据质量和数据量将是下一阶段大模型能力涌现关键中的关键。”中信智库专家委员会主任、中信建投证券研究所所长武超在2023世界人工智能大会(WAIC)上分享了一个测算,“未来一个模型的好坏,20%由算法决定,80%由数据质量决定。接下来高质量的数据将是提升模型性能的关键。”
然而,高质量数据从哪里来?目前,数据行业仍然面临多项亟待解决的问题,比如数据质量的标准是什么,如何促进数据分享和流通,如何设计定价和分配收益体系。
高质量数据告急
上海数据交易所副总经理韦志林7月8日在接受澎湃科技(www.thepaper.cn)在内的媒体采访时表示,在数据、算力、算法“三驾马车”里,数据是最核心、最长远、最基础性的要素。
大型语言模型(LLM)有如今令人惊艳的表现,背后的机制被概括为“智能涌现”,简单理解的话,就是以前没教过AI的技能它现在也会了。而大量的数据集是“智能涌现”的重要基础。
大型语言模型是具有数十亿到数万亿参数的深度神经网络,被“预训练”于数TB(Terabytes,1TB=1024GB)的巨大自然语言语料库上,包括结构化数据、在线图书和其他内容。中电金信研究院副院长单海军在2023世界人工智能大会期间对澎湃科技表示,大模型本质上是概率生成模型,其核心亮点在于能理解(上下文提示学习)、能推理(思维链)和有价值观(人类反馈强化学习)。ChatGPT比较大的突破是在GPT-3出现时,大概1750亿参数量,数据量为45个TB。
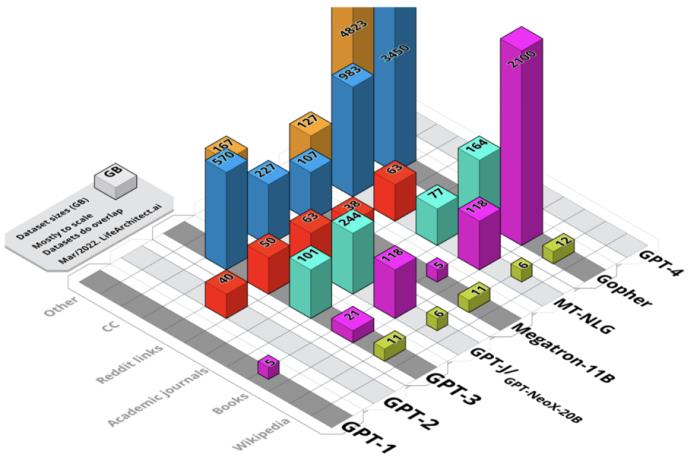
2018年到2022年初从GPT-1到Gopher的精选语言模型的所有数据集的综合视图。未加权大小,以GB为单位。图源:Alan D. Thompson
“OpenAI一直以来努力的方向都是寻求更多的优质数据,深度解析已有的数据,从而使自己的能力越来越强大。”7月12日,复旦大学教授、上海市数据科学重点实验室主任肖仰华对澎湃科技表示,“获取大规模、高质量、多样性的数据,并深入解析这些数据,可能是推动大模型发展的重要思路之一。”
然而,高质量数据正在告急。
人工智能研究人员小组Epoch去年11月进行的一项研究估计,机器学习数据集可能会在2026年前耗尽所有“高质量语言数据”。而这项研究发布时全球范围内的大模型潮还没有出现。根据该研究,“高质量”集中的语言数据来自“书籍、新闻文章、科学论文、维基百科和过滤的网络内容”。
与此同时,OpenAI等生成式AI开发机构为训练大型语言模型而进行的数据收集行为也越来越受争议。6月底,OpenAI遭集体诉讼,被指窃取“大量个人数据”来训练ChatGPT。包括Reddit和推特在内的社交媒体对其平台数据被随意使用表示不满,马斯克7月1日以此理由对推特的阅读条数实行了临时限制。
7月12日,罗素在接受科技财经媒体Insider的采访时表示,许多报道虽然未经证实,但都详细说明了OpenAI从私人来源购买了文本数据集。虽然这种购买有各种可能的解释,但“自然的推论是没有足够的高质量公共数据。”
有专家提出,或许在数据耗尽前会出现新的解决办法。比如,可以让大模型自己持续生成新数据,然后经过某种质量过滤,反过来再用于训练模型,这被称为自我学习或“反哺”。但是,根据牛津大学、剑桥大学、伦敦帝国学院等机构的研究人员今年5月在预印本平台arXiv上发表的论文,AI用AI生成的数据进行训练,会导致AI模型存在不可逆转的缺陷,他们将其称之为模型崩溃(Model Collapse)。这意味着未来模型训练使用的高质量数据将会愈来愈昂贵,网络走向碎片化和封闭化,内容创作者将会竭尽全力防止其内容被免费抓取。
不难看出,高质量数据的获取会越来越难。“我们现在大部分的数据来源还是互联网,下半年数据从哪来?我觉得这个很关键,最后大家会拼私有数据,或者你有我没有的数据。”上海人工智能实验室青年科学家、OpenDataLab负责人何聪辉在2023世界人工智能大会上谈到。
武超也对澎湃科技表示,接下来谁拥有更高质量的数据,或是能产生源源不断的高质量数据,将成为效能提升的关键。
“以数据为中心”的困扰
何聪辉认为,接下来整个模型研发的范式会慢慢从“以模型为中心”变成“以数据为中心”。但以数据为中心有一个困扰——缺乏标准,数据质量的关键性常常被提及,但实际上目前很难有人说清楚什么才是好的数据质量,标准是什么。
在实践过程中,何聪辉也面临这样的问题,“我们在这个过程中的实践方式是把数据拆细,越做越细,有每一个细分领域和细分主题,慢慢数据的质量标准就提出来了。同时,光看数据不够,还要看数据的背后,我们会结合数据和数据对应意向的模型效能提升,两边结合制定一套数据质量迭代机制。”
去年,何聪辉所在的上海人工智能实验室发布人工智能开放数据平台OpenDataLab,提供5500多个高质量数据集,“但这仅仅停留在公开数据集的层面,我们希望数据交易所,以及前两天成立的大规模语料数据联盟,能够给研究机构和企业提供更好的数据流通方式。”
7月6日,在2023世界人工智能大会上,上海人工智能实验室、中国科学技术信息研究所、上海数据集团、上海市数商协会、国家气象中心以及中央广播电视总台、上海报业集团等单位联合发起的大模型语料数据联盟宣布正式成立。
7月7日,上海数据交易所官网正式上线语料库,累计挂牌近30个语料数据产品,包含文本、音频、图像等多模态,覆盖金融、交通运输和医疗等领域。
但这样的语料库建设并非水到渠成。“能否有大模型企业所需的高质量语料?目标对象愿不愿意开放数据?”上海数据交易所总经理汤奇峰在2023世界人工智能大会上谈到,难度主要集中于开放程度和数据质量两方面。
韦志林分享道,对于数据的供给,现在面临很多挑战,头部厂商不愿意开放数据,同时,大家也担心数据在共享过程中的安全机制问题。还有一个重要问题,数据开放流通的收益分配机制也还存在疑问。
具体而言,数据共享要解决3个问题。上海零数科技有限公司创始人兼CEO林乐对澎湃科技解释,一是数据容易造假,要保证数据真实可信。二是数据容易复制,这就意味着权属关系不清晰,需要区块链进行确权和授权使用。三是容易泄露隐私,可以用区块链结合隐私计算技术,让数据做到可用不可见。
如何解决收益分配
汤奇峰指出,针对数据质量高但开放程度低的供方,可以通过数据交易链有效破解语料数据流通的信任问题,“核心之一在于产权和参与大模型后的收益分配问题。”
清华大学交叉信息核心技术研究院常务副院长林常乐正在设计一个数据如何定价和分配收益的理论体系。
“某种程度上,像ChatGPT可能几个月就免费使用了人类很多知识。我们看到大模型可以学习一些作家的文章,写出同样风格的文章,或生成梵高的画,但它无需为此付费,这些数据来源的主体也没有由此获得收益。”林常乐在2023世界人工智能大会上谈到,所以目前可能存在一种比较激进的观点:大模型时代知识产权不存在了,或者说传统的知识产权保护不存在了。
但林常乐认为,大模型时代后知识产权保护会发展到对数据的确权、定价和交易。“当大模型发展走向更深度,比如行业大模型,其所需的数据就不是互联网免费公开的数据了,要训练出精度极高的的模型,需要的是行业专业知识,甚至商业机密类型的知识。要让大家贡献这样的语料库,肯定需要有一种权益分配机制。”
林常乐现在在做的“数据资产图谱”,是用数学证明出来一套收益分配的机制,将数据权益进行公平的分配。
如何解决数据流通
工信部赛迪研究院副总工程师、俄罗斯自然科学院外籍院士刘权在WAIC“数实融合,智领未来”产业区块链生态论坛上提到,最近北京版“数据二十条”在业界产生了非常大的反响,它解决了数据流通过程中的核心问题。最明显的是,政务的数据归谁的问题明确了——公共数据归政府所有。那么企业的数据、个人的数据呢?“可以委托北京市数据交易所进行委托经营。”
7月5日,中共北京市委、北京市人民政府印发《关于更好发挥数据要素作用进一步加快发展数字经济的实施意见》的通知。《实施意见》分为九部分,从数据产权、流通交易、收益分配、安全治理等方面构建数据基础制度,共提出23条具体要求,被业内称为北京版“数据二十条”。
“在国内来看,据统计,数据资源80%集中在公共和政府事业单位。我们要解决数据的供给,很大程度上也是希望基于数据二十条(《中共中央、国务院关于构建数据基础制度更好发挥数据要素作用的意见》)对公共数据的开放共享,能够形成一套可复制的机制和范式,来促进形成于公共事业的的数据,再服务于公共。”韦志林说。
韦志林表示,按照现在的统计,中国全社会的数据资源存量排在全球第二,但这些数据分散在各个地方。根据国家信息中心数字中国研究院副院长展钰堡7月7日在2023世界人工智能大会上的梳理,中国目前的全国化数据流通体系包括:有两个数据交易所,一个是上海数据交易所,一个是深圳数据交易所;在国内还有17家数据交易中心,包含北京数据交易中心。

相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










