

 新火种
2023-10-29
新火种
2023-10-29 


浙大蔡登团队:基于序列对比学习的长视频逐帧动作表征

编译 | 龚倩
编辑 | 陈彩娴引言

论文链接:https://arxiv.org/pdf/2203.14957.pdf
在过去几年中,基于深度学习的视频理解在视频分类任务上取得了巨大成功。I3D和SlowFast等网络通常将短视频片段(32帧或64帧)作为输入,提取全局表征来预测动作类别。不过,许多实际应用,例如手语翻译、机器人模仿学习、动作对齐和相位分类都要求算法能够对具有数百帧的长视频进行建模,并提取逐帧表征,而不是全局特征。

(a) 在FineGym 数据集上的细粒度帧检索

(b) 在Pouring 数据集上的相位边界检测
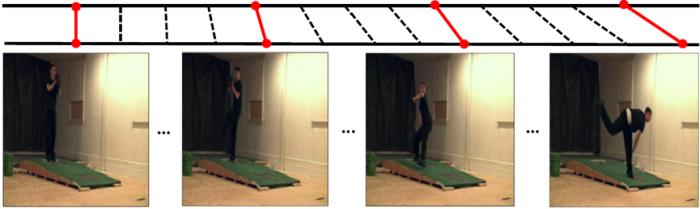
(c)在PennAction 数据集上的时间视频对齐
以前的方法尝试通过监督学习来学习逐帧表征,其中子动作或相位边界被注释。然而,在大规模数据集上手动标记每个帧和精确的动作边界非常耗时,甚至不切实际,从而妨碍了基于全监督学习训练的模型在现实场景中的推广。为了减少对标记数据的依赖性,TCC、LAV和GTA等方法通过使用循环一致性损失或软动态时间扭曲来进行弱监督学习。所有这些方法都依赖于视频水平的注释,并且是用表现相同动作的成对视频进行训练的。该前提使得在没有可用标签的更一般的视频数据集中无法应用这些方法。
本研究的目的是以自监督方式学习长视频中具有时空上下文信息的逐帧表征。受对比表征学习最新进展的启发,我们提出了一个新框架——对比动作表征学习(CARL)。我们假设在训练期间没有可用的标签,并且训练和测试集中的视频都很长(数百帧)。此外,我们不依赖具有相同动作的成对视频进行训练,从而能够以更低的成本扩大训练集规模。
为数百帧的长视频建模是一项挑战。直接使用为短视频片段分类而设计的现成骨架也不太现实,因为我们的任务是提取长视频的逐帧表征。在本研究中,我们提出了一种简单而高效的视频编码器,它由一个对每帧的空间信息进行编码的2D网络和一个对时间交互进行建模的Transformer编码器组成。然后使用逐帧特征进行表征学习。
最近,SimCLR使用实例鉴别作为网络前置任务,并引入了一个名为NT-Xent的对比损失,该对比损失最大化相同数据的两个增强视图之间的一致性。在他们的实现中,除正面参照样本外的所有实例都被判定为负样本。与图像数据不同的是,视频提供了更丰富的实例(每一帧都被视为一个实例),相邻帧具有很高的语义相似性。直接将这些帧视为负样本可能会损害学习过程。为了避免这个问题,我们提出了一种新的序列对比损失框架(SCL),它通过最小化两个增强视频视图的序列相似性与先验高斯分布之间的KL散度来优化嵌入空间。
综上,本文的主要贡献总结如下:
我们提出了一个名为对比动作表征学习(CARL)的新架构,以自监督方式学习长视频中具有时空上下文信息的逐帧动作表征。我们的方法不依赖于任何数据注释,也不对数据集进行假设。
我们引入了一种基于Transformer的网络来对长视频进行高效编码,和一种新的序列对比损耗(SCL)用于表征学习。同时,我们设计了一系列时空数据增强,以增加训练数据的多样性。
我们的框架在不同数据集的多个任务上大大优于目前为止最先进的方法。例如,在FineGym数据集上的线性评估协议下,我们的框架实现了41.75%的准确率,比现有的最佳方法GTA高出+13.94%。在Penn Action和Kendall's Tau数据集上,我们的方法分别实现了91.67%和99.1%的细粒度分类,以及前五个细粒度帧检索精度的90.58%,这些结果都优于现有的最佳方法。
方法
2.1. 概述
图2中我们对CARL架构进行了概述。首先通过一系列时空数据增强为输入视频构建两个增强视图。此步骤称为数据预处理。然后,我们将两个增强视图输入到帧级视频编码器(FVE)中,以提取密集表征。遵循SimCLR,FVE附加了一个小型投影网络,它是一个两层的MLP,用于获得潜在嵌入。由于时间上相邻的帧高度相关,我们假设两个视图之间的相似性分布遵循先验高斯分布。基于此,我们提出了一种新的序列对比损失(SCL)来优化嵌入空间中的逐帧表征。

图2 架构概述(CARL)。通过一系列时空数据增强,从训练视频构建两个增强视图。帧级视频编码器(FVE)和投影头通过最小化两个视图之间的序列对比损失(SCL)进行优化。
2.2. 视图构建
首先介绍本方法的视图构建步骤,如图2中的"数据预处理"部分所示。在自监督学习中,数据增强对于避免平凡解至关重要。以前针对图像数据的方法只需要空间增强,与此不同,我们引入了一系列时空数据增强,以进一步增加视频的多样性。
具体而言,对于一个具有S帧的训练视频V,我们的目标是通过一系列时空数据增强,独立地构造两个T帧的增强视频。对于时间数据增强,我们首先对V执行随机时间裁剪,以生成两个长度为[T,αT]帧的随机裁剪片段,其中α是控制最大裁剪长度的超参数。在此过程中,我们保证两个剪辑片段之间至少存在β%的重叠帧。然后对每个视频序列随机采样T帧,获得视频序列V1和V2,默认设置T=240。对于小于T帧的视频,在裁减之前会对空帧进行填充。最后,分别在V1和V2上应用几种时间一致的空间数据增强,包括随机调整大小和裁剪、水平翻转、随机颜色失真和随机高斯模糊。
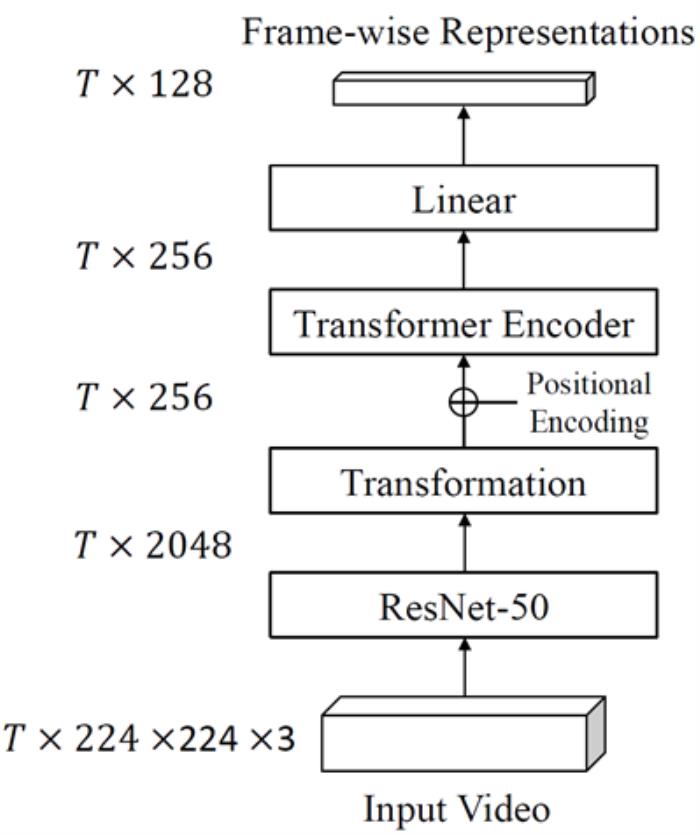
图3 帧级视频编码器(FVE)的结构。输入T帧长视频,输出逐帧表征。ResNet-50在ImageNet上进行了预训练。我们冻结了ResNet-50的前四个残差块,只微调最后一个块。
2.3. 帧级视频编码器
直接应用视频分类架构对数百帧的长视频序列进行建模,因其计算量巨大而无法实现。TCC提出了一种视频编码器,它将2D ResNet和3D卷积相结合,以生成逐帧特征。然而叠加太多3D卷积层会导致计算成本过高。这导致这种类型的设计可能只有有限的感受野来捕捉时间上下文。最近,Transformers在计算机视觉方面取得了巨大的进步。Transformers利用注意机制解决序列到序列任务,同时轻松处理远距离依赖关系。在本网络实现中,我们采用了Transformer编码器来建模时间上下文。
图3展示了我们的帧级视频编码器(FVE)。为了在表征性能和推理速度之间达到平衡,我们首先使用一个2D网络(例如ResNet-50)沿时间维度提取长度为T×224×224×3的RGB视频序列的空间特征。然后用一个转换块(该转换块由两个具有批量归一化ReLU的全连接层组成),将空间特征投影到大小为T×256的中间嵌入。遵循常规做法,我们在中间嵌入的顶部添加了正弦-余弦位置编码,以编码顺序信息。接下来,将编码后的嵌入输入到3层Transformer编码器中,以对时间上下文进行建模。最后,采用一个线性层来获取最终的逐帧表征H。
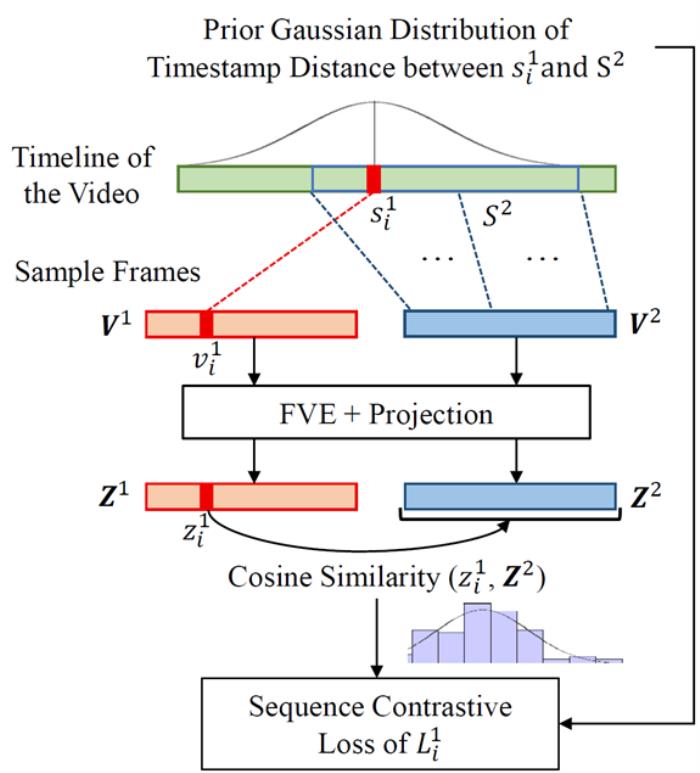
图4 序列对比损失图解。以V1中的一个视频帧损失计算过程为例。我们首先计算时间戳距离的先验高斯分布。然后计算该帧的嵌入与V2中所有视频帧的嵌入之间的嵌入相似性分布,最后将嵌入空间中两个分布的KL散度最小化。
2D 的ResNet-50网络在ImageNet上进行了预训练。考虑到计算预算有限,我们冻结了前四个残差块,因为它们已经通过预训练学习了良好的低级视觉表征。这种简单的设计确保本网络可以在超过500帧的视频上进行训练和测试。VTN采用了一种类似的基于Transformer的混合网络来执行视频分类任务。他们使用[CLS]令牌来生成全局特征,而我们的网络是通过考虑时空上下文来提取帧表征。此外,我们的网络尝试了对更长的视频序列进行建模。
2.4. 序列对比损失
SimCLR通过最大化同一实例的增强视图之间的一致性,引入了一个叫做NTXent的对比损失。
与图像的自监督学习不同,视频提供了丰富的序列信息,这是一个重要的监督信号。对于典型的实例判别,除了正面参考样本之外的所有实例都被判定为负样本。然而,参考帧附近的帧高度相关。直接将这些帧视为负样本可能会损害学习过程,因此我们应该尽量避免这个问题。为了优化逐帧表征,我们提出了一种新的序列对比损失(SCL),它通过最小化两个增强视图的嵌入相似性和先验高斯分布之间的KL散度来实现,如图4所示。
具体来说,与SimCLR类似,我们使用一个由两层MLP组成的小型投影网络g,由FVE编码的帧表征H由该投影网络投影到潜在嵌入Z。考虑到两个视频序列V1和V2对应的嵌入向量Z1和Z2中每个潜在嵌入,在时间上相邻的帧比相距更远的帧相关性更高,我们假设每个视频帧的潜在嵌入和另一个视频序列的潜在向量之间的嵌入相似性遵循时间戳距离的先验高斯分布。基于这个假设,我们使用KL散度优化嵌入空间。具体来说,对于V1,我们首先计算 V1中每个帧的损失,然后计算V1所有帧损失的平均值即为V1的总损失,V2同理,序列对比损失为两个视频序列V1和V2总损失的和。值得注意的是,本方法中的损失并不依赖于V1和V2之间的帧到帧的对应关系,这增加了时空数据增强的多样性。
实验结果
我们使用三个视频数据集,即PennAction、FineGym和Pouring来评估本方法的性能。我们在三个数据集上将本方法与迄今为止最先进的技术进行了比较。
PennAction数据集上的结果
如表2所示,我们报告的结果低于平均精度@K指标(Average Precision@K metric),该指标衡量细粒度帧检索的性能。出乎意料的是,尽管我们的模型没有经过成对数据的训练,但它仍然可以从其他视频中成功地找到具有相似语义的帧。对于所有的AP@K,我们的方法优于以前的方法至少11%。
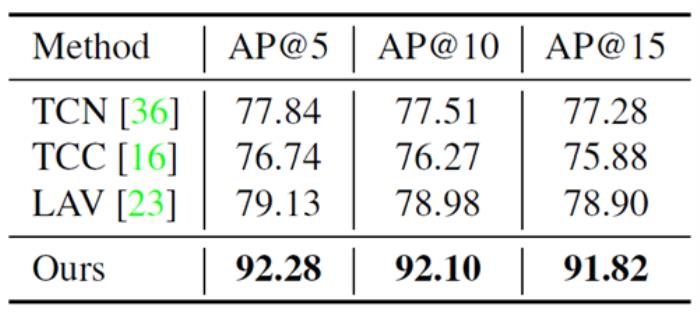
表2 在PennAction数据集上的细粒度帧检索结果。
FineGym数据集上的结果
表3总结了FineGym99和FineGym288上细粒度动作分类的实验结果。结果显示我们的方法优于其他自监督和弱监督方法。我们的方法在FineGym99和FineGym288上的性能比之前最先进的方法GTA分别高出+13.94%和+11.07%。如TCC、TW和GTA等弱监督方法假设训练集中的两个视频之间存在最佳对齐。然而,对于FineGym数据集,即使在描述同一动作的两个视频中,子动作的设置和顺序也可能不同。因此,这些方法找到的对齐可能不正确,因而会阻碍学习。我们的方法在两个指标上有很大的提高,从而验证了我们框架的有效性。
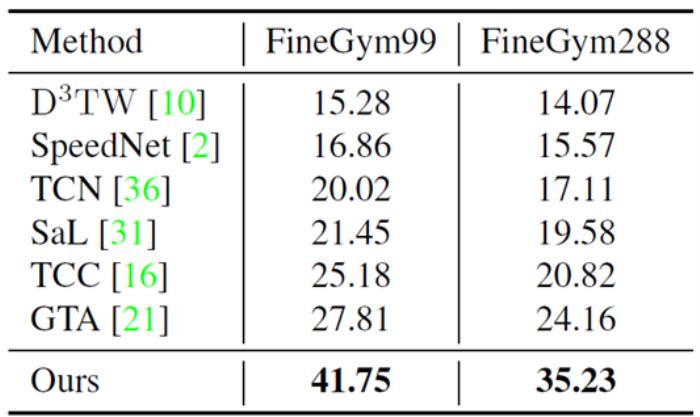
表3 以细粒度动作分类为评估指标, 在FineGym上我们的方法与最先进的方法进行比较。
Pouring数据集上的结果
如表4所示,我们的方法在一个相对较小的数据集Pouring上性能也是最好的。这些结果进一步证明了我们的方法具有很强的泛化能力。
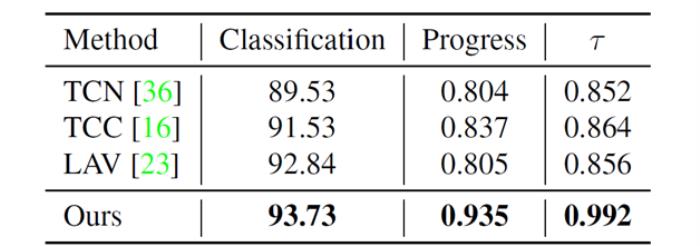
表4 在Pouring数据集上与最先进方法的比较
结论
在本文中,我们提出了一个对比动作表征学习(CARL)的新框架,以自监督的方式学习逐帧动作表征,尤其是长视频。为了对数百帧的长视频进行建模,我们引入了一个简单而高效的网络,称为帧级视频编码器(FVE),该网络在训练过程中参考了时空上下文。
此外,我们还提出了一种新的用于逐帧表征学习的序列对比损失(SCL)。SCL通过最小化两个增强视图的序列相似性与先验高斯分布之间的KL散度来优化嵌入空间。我们在各种数据集和任务上的实验结果证明了该方法的有效性和通用性。


相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
