

 新火种
2023-10-28
新火种
2023-10-28 

4K画质3D合成视频不再卡成幻灯片,新方法将渲染速度提高了30多倍
本文提出了一种突破性的点云表示 4K4D,能够以 4K 分辨率对动态 3D 场景进行高保真实时渲染,达到了前所未有的渲染速度和令人印象深刻的渲染质量。
当 4K 画质、60 帧视频在某些 APP 上还只能开会员观看时,AI 研究者已经把 3D 动态合成视频做到了 4K 级别,而且画面相当流畅。
但是,这种 3D 动态场景的合成一直是个难点,无论是在画质上还是流畅度上。
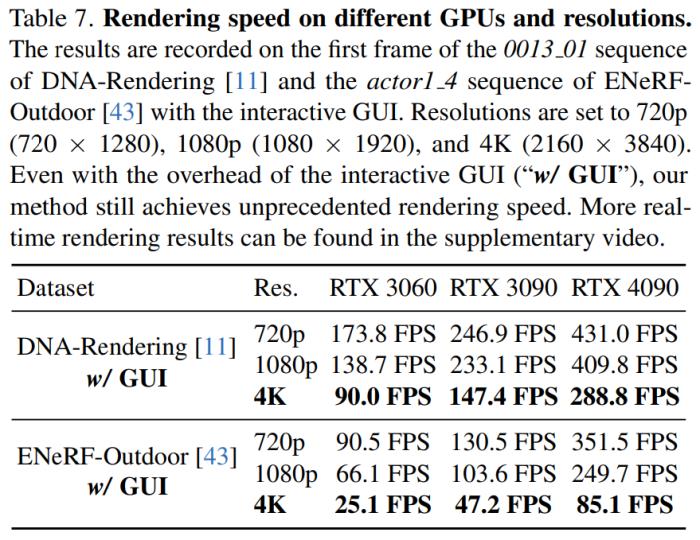
最近,来自浙江大学、像衍科技和蚂蚁集团的研究者对这个问题发起了挑战。在一篇题为「4K4D: Real-Time 4D View Synthesis at 4K Resolution」的论文中,他们提出了一种名为4K4D的点云表示方法,大大提升了高分辨率3D动态场景合成的渲染速度。具体来说,使用 RTX 4090 GPU,他们的方法能以 4K 分辨率进行渲染,帧率可达80 FPS;以1080p分辨率进行渲染时,帧率可达400FPS。总体来看,它的速度是以前方法的30多倍,而且渲染质量达到了SOTA。
论文概览 论文链接:https://arxiv.org/pdf/2310.11448.pdf项目链接:https://zju3dv.github.io/4k4d/
论文链接:https://arxiv.org/pdf/2310.11448.pdf项目链接:https://zju3dv.github.io/4k4d/
动态视图合成旨在从捕获的视频中重建动态 3D 场景,并创建沉浸式虚拟回放,这是计算机视觉和计算机图形学中长期研究的问题。这种技术实用性的关键在于它能够以高保真度实时渲染,使其能够应用于 VR/AR、体育广播和艺术表演捕捉。传统方法将动态 3D 场景表示为纹理网格序列,并使用复杂的硬件进行重建。因此,它们通常仅限于受控环境。
最近,隐式神经表示在通过可微渲染从 RGB 视频重建动态 3D 场景方面取得了巨大成功。例如《Neural 3d video synthesis from multi-view video》将目标场景建模为动态辐射场,利用体渲染合成图像,并与输入图像进行对比优化。尽管动态视图合成结果令人印象深刻,但由于网络评估昂贵,现有方法通常需要几秒钟甚至几分钟才能以 1080p 分辨率渲染一张图像。
受静态视图合成方法的启发,一些动态视图合成方法通过降低网络评估的成本或次数来提高渲染速度。通过这些策略,MLP Maps 能够以 41.7 fps 的速度渲染前景动态人物。然而,渲染速度的挑战仍然存在,因为 MLP Maps 的实时性能只有在合成中等分辨率(384×512)的图像时才能实现。当渲染 4K 分辨率的图像时,它的速度降低到只有 1.3 FPS。
在这篇论文中,研究者提出了一种新的神经表示 ——4K4D,用于建模和渲染动态 3D 场景。如图 1 所示,4K4D 在渲染速度上明显优于以前的动态视图合成方法,同时在渲染质量上具有竞争力。
研究者发现,基于 MLP 的 SH 模型难以表示动态场景的外观。为了缓解这个问题,他们还引入了一个图像混合模型来与 SH 模型结合,以表示场景的外观。一个重要的设计是,他们使图像混合网络独立于观看方向,因此可以在训练后预先计算,以提高渲染速度。作为一把双刃剑,该策略使图像混合模型沿观看方向离散。使用连续 SH 模型可以弥补这个问题。与仅使用 SH 模型的 3D Gaussian Splatting 相比,研究者提出的混合外观模型充分利用了输入图像捕获的信息,从而有效地提高了渲染质量。
为了验证新方法的有效性,研究者在多个广泛使用的多视图动态新视图合成数据集上评估了 4K4D,包括 NHR、ENeRF-Outdoo、DNA-Rendering 和 Neural3DV。广泛的实验表明,4K4D 不仅渲染速度快了几个数量级,而且在渲染质量方面也明显优于 SOTA 技术。使用 RTX 4090 GPU,新方法在 DNA-Rendering 数据集上达到 400 FPS,分辨率为 1080p;在 ENeRF-Outdoor 数据集上达到 80 FPS,分辨率为 4k。
方法介绍
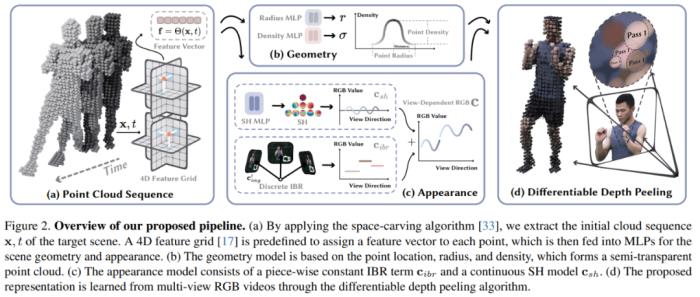
给定捕获动态 3D 场景的多视图视频,本文旨在重建目标场景并实时地进行视图合成。模型架构图如图 2 所示:
4D 嵌入:给定目标场景的粗点云,本文使用神经网络和特征网格表示其动态几何和外观。具体来说,本文首先定义了六个特征平面 θ_xy、θ_xz、θ_yz、θ_tx、θ_ty 和 θ_tz,并采用 K-Planes 策略,利用这六个平面来建模一个 4D 特征场 Θ(x, t):
外观模型:如图 2c 所示,本文使用图像混合技术和球谐函数(SH)模型来构建混合外观模型,其中图像混合技术表示离散视图外观 c_ibr,SH 模型表示连续的依赖于视图的外观 c_sh。对于第 t 帧处的点 x,其在视图方向 d 上的颜色为:
本文提出的动态场景表示借助深度剥离算法可以渲染成图像。
研究者开发了一个自定义着色器来实现由 K 个渲染通道组成的深度剥离算法。即对于一个特定的像素 u,研究者进行了多步处理,最后,经过 K 次渲染后,像素 u 得到一组排序点 {x_k|k = 1, ..., K}。
基于这些点 {x_k|k = 1, ..., K},得到体渲染中像素 u 的颜色表示为:
本文在 DNA-Rendering、ENeRF-Outdoor、 NHR 以及 Neural3DV 数据集上评估了 4K4D 方法。
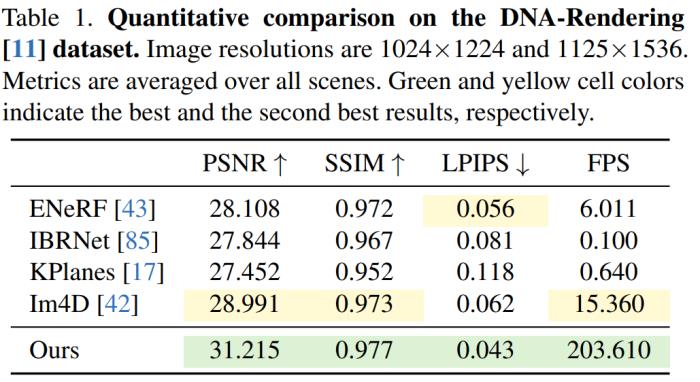
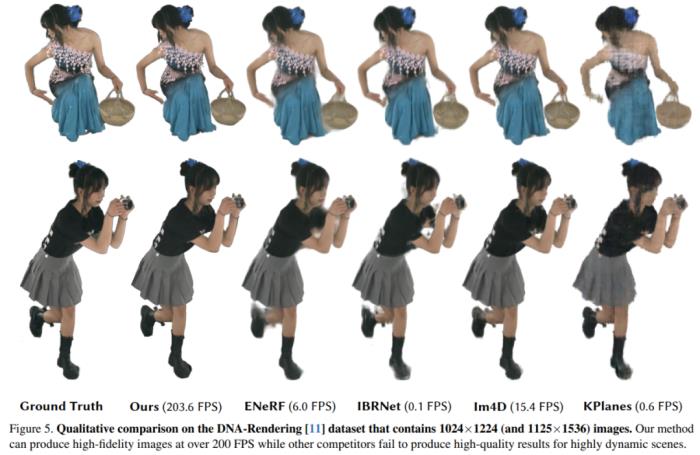
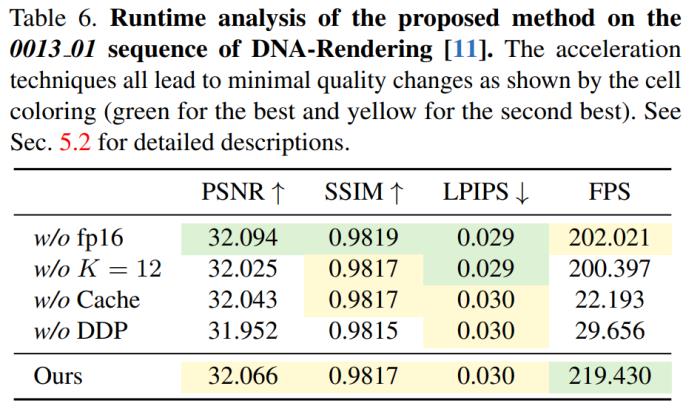
在 DNA-Rendering 数据集上的结果如表 1 所示,结果显示,4K4D 渲染速度比具有 SOTA 性能的 ENeRF 快 30 多倍,并且渲染质量还更好。
当 4K 画质、60 帧视频在某些 APP 上还只能开会员观看时,AI 研究者已经把 3D 动态合成视频做到了 4K 级别,而且画面相当流畅。
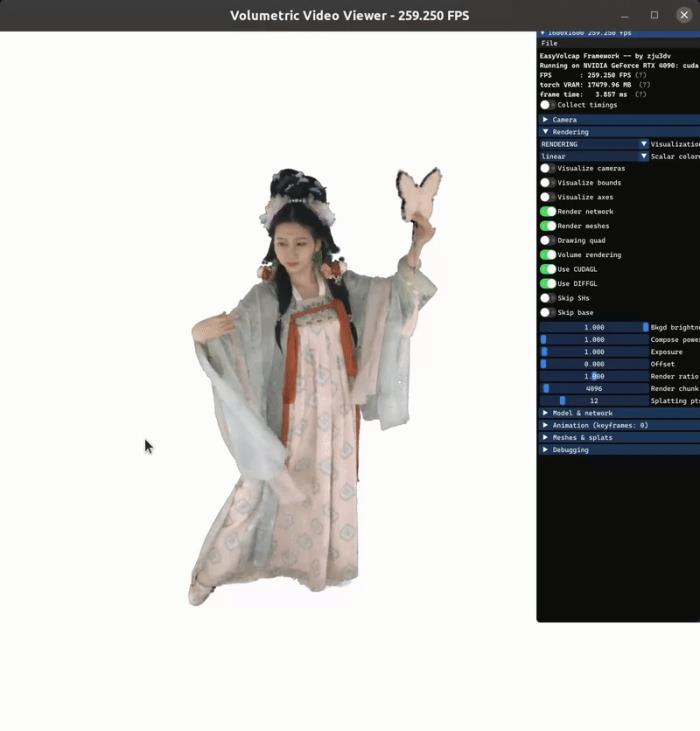

但是,这种 3D 动态场景的合成一直是个难点,无论是在画质上还是流畅度上。
最近,来自浙江大学、像衍科技和蚂蚁集团的研究者对这个问题发起了挑战。在一篇题为「4K4D: Real-Time 4D View Synthesis at 4K Resolution」的论文中,他们提出了一种名为4K4D的点云表示方法,大大提升了高分辨率3D动态场景合成的渲染速度。具体来说,使用 RTX 4090 GPU,他们的方法能以 4K 分辨率进行渲染,帧率可达80 FPS;以1080p分辨率进行渲染时,帧率可达400FPS。总体来看,它的速度是以前方法的30多倍,而且渲染质量达到了SOTA。

论文概览
论文链接:https://arxiv.org/pdf/2310.11448.pdf项目链接:https://zju3dv.github.io/4k4d/动态视图合成旨在从捕获的视频中重建动态 3D 场景,并创建沉浸式虚拟回放,这是计算机视觉和计算机图形学中长期研究的问题。这种技术实用性的关键在于它能够以高保真度实时渲染,使其能够应用于 VR/AR、体育广播和艺术表演捕捉。传统方法将动态 3D 场景表示为纹理网格序列,并使用复杂的硬件进行重建。因此,它们通常仅限于受控环境。
最近,隐式神经表示在通过可微渲染从 RGB 视频重建动态 3D 场景方面取得了巨大成功。例如《Neural 3d video synthesis from multi-view video》将目标场景建模为动态辐射场,利用体渲染合成图像,并与输入图像进行对比优化。尽管动态视图合成结果令人印象深刻,但由于网络评估昂贵,现有方法通常需要几秒钟甚至几分钟才能以 1080p 分辨率渲染一张图像。
受静态视图合成方法的启发,一些动态视图合成方法通过降低网络评估的成本或次数来提高渲染速度。通过这些策略,MLP Maps 能够以 41.7 fps 的速度渲染前景动态人物。然而,渲染速度的挑战仍然存在,因为 MLP Maps 的实时性能只有在合成中等分辨率(384×512)的图像时才能实现。当渲染 4K 分辨率的图像时,它的速度降低到只有 1.3 FPS。
在这篇论文中,研究者提出了一种新的神经表示 ——4K4D,用于建模和渲染动态 3D 场景。如图 1 所示,4K4D 在渲染速度上明显优于以前的动态视图合成方法,同时在渲染质量上具有竞争力。

研究者发现,基于 MLP 的 SH 模型难以表示动态场景的外观。为了缓解这个问题,他们还引入了一个图像混合模型来与 SH 模型结合,以表示场景的外观。一个重要的设计是,他们使图像混合网络独立于观看方向,因此可以在训练后预先计算,以提高渲染速度。作为一把双刃剑,该策略使图像混合模型沿观看方向离散。使用连续 SH 模型可以弥补这个问题。与仅使用 SH 模型的 3D Gaussian Splatting 相比,研究者提出的混合外观模型充分利用了输入图像捕获的信息,从而有效地提高了渲染质量。
为了验证新方法的有效性,研究者在多个广泛使用的多视图动态新视图合成数据集上评估了 4K4D,包括 NHR、ENeRF-Outdoo、DNA-Rendering 和 Neural3DV。广泛的实验表明,4K4D 不仅渲染速度快了几个数量级,而且在渲染质量方面也明显优于 SOTA 技术。使用 RTX 4090 GPU,新方法在 DNA-Rendering 数据集上达到 400 FPS,分辨率为 1080p;在 ENeRF-Outdoor 数据集上达到 80 FPS,分辨率为 4k。
方法介绍
给定捕获动态 3D 场景的多视图视频,本文旨在重建目标场景并实时地进行视图合成。模型架构图如图 2 所示:
4D 嵌入:给定目标场景的粗点云,本文使用神经网络和特征网格表示其动态几何和外观。具体来说,本文首先定义了六个特征平面 θ_xy、θ_xz、θ_yz、θ_tx、θ_ty 和 θ_tz,并采用 K-Planes 策略,利用这六个平面来建模一个 4D 特征场 Θ(x, t):
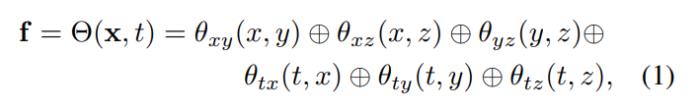
外观模型:如图 2c 所示,本文使用图像混合技术和球谐函数(SH)模型来构建混合外观模型,其中图像混合技术表示离散视图外观 c_ibr,SH 模型表示连续的依赖于视图的外观 c_sh。对于第 t 帧处的点 x,其在视图方向 d 上的颜色为:
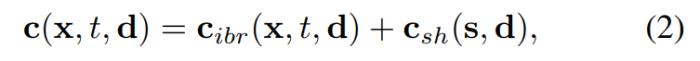
本文提出的动态场景表示借助深度剥离算法可以渲染成图像。
研究者开发了一个自定义着色器来实现由 K 个渲染通道组成的深度剥离算法。即对于一个特定的像素 u,研究者进行了多步处理,最后,经过 K 次渲染后,像素 u 得到一组排序点 {x_k|k = 1, ..., K}。
基于这些点 {x_k|k = 1, ..., K},得到体渲染中像素 u 的颜色表示为:
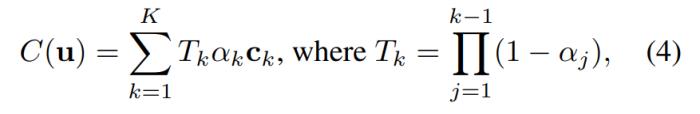

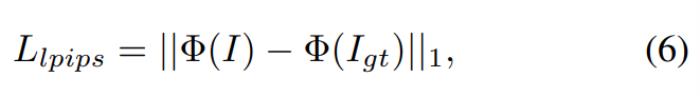
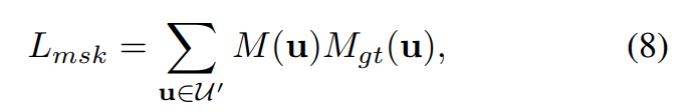
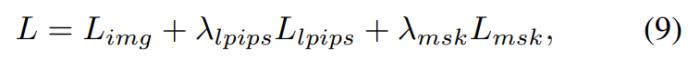
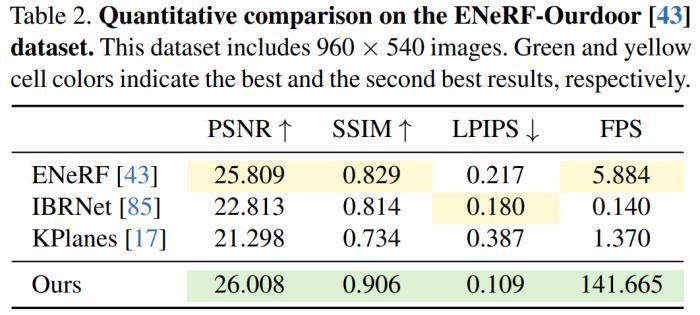
本文在 DNA-Rendering、ENeRF-Outdoor、 NHR 以及 Neural3DV 数据集上评估了 4K4D 方法。
在 DNA-Rendering 数据集上的结果如表 1 所示,结果显示,4K4D 渲染速度比具有 SOTA 性能的 ENeRF 快 30 多倍,并且渲染质量还更好。

相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










