

 新火种
2023-10-28
新火种
2023-10-28 


“曹植”大模型主攻写报告,达观数据董事长:机会在垂直行业
·“曹植”大模型可完成多类型、复杂结构的长文本写作,自动起草多种类型的文档,未来将实现多模态内容生成,如长文档中的表格、图表、图片等。其展示的能力不是问答,而是写材料,界面完全针对各项材料应用场景来定制。
·云计算服务商优刻得董事长兼CEO季昕华认为:“如果没有一点泡沫,资本不进来,那对行业并不好,泡沫可控的时候整体氛围比较好。相对来说,整个行业都在竞争,每个投资者都会评估投出的钱是不是有效,所以相对来说是良性的。”

达观数据董事长陈运文在2023世界人工智能大会上演讲。
“目前我们谈论的都是模型本身,包括今年的世界人工智能大会,但我觉得明年、后年大家会开始谈一谈模型用在哪里、解决什么问题,是什么样的产品形态等。”7月7日,达观数据董事长陈运文在世界人工智能大会期间在接受澎湃科技(www.thepaper.cn)采访时表示。
达观数据于2015年成立于上海,是一家为企业提供各类场景智能文本机器人的国家高新技术企业,结合先进的自然语言处理(NLP)、智能文档处理(IDP)、光学字符识别(OCR)、机器人流程自动化(RPA)、知识图谱等技术,为大型企业和政府机构提供文档智能审阅、文档智能写作、知识搜索与问答、办公流程自动化等智能文本机器人产品。
7月7日,达观数据在2023世界人工智能大会“AI生成与垂直大语言模型的无限魅力” 主题论坛上发布“曹植”大模型。据该公司介绍,“这是国内首个垂直行业专用的自主可控的GPT大语言模型,可准确完成多类型、复杂结构的长文本写作,自动起草多种类型的文档,未来将实现多模态内容生成,如长文档中的表格、图表、图片等。”
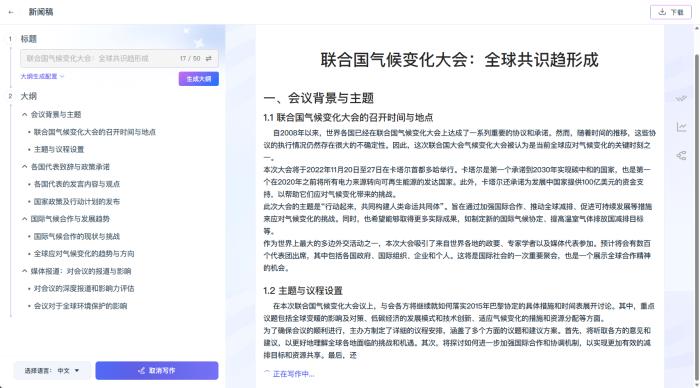
曹植长文本写作应用。
陈运文说,今天看到的大模型展示更多是一问一答的形式,而“未来如果大模型真正发挥作用,一定不会只是一问一答的形式。就像电出现后,1879年出现最多的是造电灯泡的公司,但是电能的应用不止电灯泡一种形式。我们不做灯泡,我们要做洗衣机、做电冰箱,要去想象其他真正满足应用场景的产品形态。”陈运文对记者说,“你可以注意到我们今天展示的‘曹植’的能力都不是问答,而是写报告,它的界面是完全针对写报告这种应用场景来定制的。”
采用混合训练数据方案
“大家都知道,曹植七步成诗。他作为建安七子之一,写作的最著名的篇章《洛神赋》就是古代文学作品里典型首屈一指的长文本。”陈运文在发布会上介绍道,“这也是‘曹植’大模型的专长,做文档资料智能化的分析写作工作。”
“曹植”大模型采用混合训练数据的方案,即包括50%高质量的各行各业混合语料和50%垂直专用语料。“采用混合的方式很好兼容了模型的通用基座能力和垂直行业的专业能力。”陈运文说。
大语言模型本身有非常强大的语言理解能力,但同时也有自己的弊端,比如会产生“幻觉”,即“一本正经地胡说八道”。而在专业领域,所有数据都必须非常严谨准确。如何解决这个矛盾?
“我们一方面是把经典的知识图谱、业务引擎等和大语言模型融合。同时我们也发现,不同参数规模的模型各有利弊,所以我们的模型中既有数十亿参数,也会有数百亿参数,未来还会研发数千亿参数的模型,甚至未来还可以对接其他第三方已有的大模型,让各种模型融会贯通,各取所长。”陈运文说。
如果让一个大模型真正能够处理长文本,它需要聪明地应对多模态的内容,同时能够对复杂的结构元素进行理解和分析。比如分析证券领域的研报,需要让计算机像人一样了解,每个版面的区域是什么含义,板块如何分布,然后才能用大模型的语义理解做进一步的阅读理解工作,除此之外,还要解析没有边框或是有各种复杂嵌套的表格等,在现实应用中,对各种各样的文档资料进行理解与分析是其中难点。
“以前大家看到的很多大模型应用中,它不考虑这么多复杂的模态。而真正要投入使用时会发现,这些模态、格式多样,如果不解决这个问题是没有办法真正投入使用的。”陈运文说,“我相信在各种大模型的发布会上大家可能第一次听说这些技术,但我觉得这些技术才能真正让大模型发挥生产力去解决问题。”
“垂直大模型能解决输出不可控问题”
“未来大模型真正得以运用,还是需要和每一个垂直行业深度结合,去解决每一个行业里面真正的痛点才行。”陈运文认为,“大模型未来在企业的落地形态一定是大模型和多个企业垂直小模型的组合,真正的机会在垂直行业市场落地。”
在“AI生成与垂直大语言模型的无限魅力”论坛中,云计算服务商优刻得董事长季昕华对澎湃科技介绍了其对国内大模型数量的统计:目前国内有130家公司在做大模型,其中做通用大模型的有78家,做垂直大模型的有52家。
“我认为未来的趋势是垂直大模型会越来越多。通用的好处是什么都知道,但是不深,垂直则能解决输出不可控的问题,未来可能是通用加垂直一起来解决问题,而垂直由于它对数据和产品要求会更高,所以作用会更强一些。”季昕华说。
今年3月底,彭博社(Bloomberg)发布金融版ChatGPT“BloombergGPT”。“他们用非常好的训练方式训练出金融领域专用的大语言模型,我觉得做了一个非常好的示范。”陈运文说。
“百模大战”是不是泡沫?“卡布奇诺最好”
“从历史发展来看,实际上除了百模大战之外,曾经有互联网的‘百团大战’甚至‘千团大战’。只是整个模型训练需要比较高的门槛,所以目前才只是出现了100多家,如果没有这么高的门槛,估计有1000家在做,这说明大家对整个行业的预期很好。”季昕华说。
随着ChatGPT用户增速放缓,质疑这次生成式AI热潮是不是泡沫的声音也开始出现。对于记者的相关提问,季昕华有些出乎意料地答道,“我喝咖啡特别喜欢卡布奇诺”。
他接着说,“因为它大部分是咖啡,上面有一点点泡沫,这种味道是比较好的。整个行业发展也是一样,如果没有一点泡沫,资本不进来,那对行业并不好,泡沫可控的时候整体氛围比较好。相对来说,整个行业都在竞争,每个投资者都会评估投出的钱是不是有效,所以相对来说是良性的。”
陈运文也认为百模大战是很合理的状态,“因为新的东西出来一定需要有很多人响应,这也证明了大模型确实是非常有价值的东西。”
根据季昕华的判断,目前国内大模型整体情况比OpenAI的GPT-3.5略微低一些,大概今年年底能达到GPT-3.5的水平,明年能达到GPT-4的水平。“目前来讲,整个大模型的核心问题在于:第一,是否有足够的数据;第二,是否有足够的算力;第三,非常关键的是算法;第四,能否实现线上的闭环,形成闭环反馈对大模型的优化非常有帮助。”
接下来,在“百模大战”之后,陈运文认为就会是开始落地的时候,“这个我们称为先打雷再下雨,目前是大家都知道大模型,但其实在很多工作岗位上还没有怎么用上。接下来需要让这些模型的能力在千行百业落地应用,渗透进去赋能行业。”

相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










