

 新火种
2023-10-27
新火种
2023-10-27 

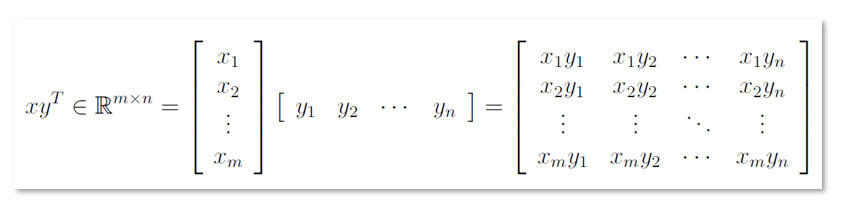

深度学习和机器学习的线性代数入门
本文目录
引言
机器学习ML和深度学习NN中的线性代数
矩阵
向量
矩阵乘法
转置矩阵
逆矩阵
正交矩阵
对角矩阵
正规方程的转置矩阵和逆矩阵
线性方程
向量范数
L1范数/Manhattan范数
L2范数/Euclidean范数
ML中的正则化
Lasso
岭
特征选择与抽取
协方差矩阵
特征值与特征向量
正交性
正交集
扩张空间
基
主成分分析(PCA)
矩阵分解
总结
引言
机器学习和深度学习建立在数学原理和概念之上,因此AI学习者需要了解基本数学原理。在模型构建过程中,我们经常设计各种概念,例如维数灾难、正则化、二进制、多分类、有序回归等。
神经元是深度学习的基本单位,该结构完全基于数学概念,即输入和权重的乘积和。至于Sigmoid,ReLU等等激活函数也依赖于数学原理。
正确理解机器学习和深度学习的概念,掌握以下这些数学领域至关重要:
线性代数
微积分
矩阵分解
概率论
解析几何
机器学习和深度学习中的线性代数
在机器学习中,很多情况下需要向量化处理,为此,掌握线性代数的知识至关重要。对于机器学习中典型的分类或回归问题,通过最小化实际值与预测值差异进行处理,该过程就用到线性代数。通过线性代数可以处理大量数据,可以这么说,“线性代数是数据科学的基本数学。”
在机器学习和深度学习中,我们涉及到线性代数的这些知识:
向量与矩阵
线性方程组
向量空间
偏差
通过线性代数,我们可以实现以下机器学习或深度学习方法:
推导回归方程
通过线性方程预测目标值
支持向量机SVM
降维
均方差或损失函数
正则化
协方差矩阵
卷积
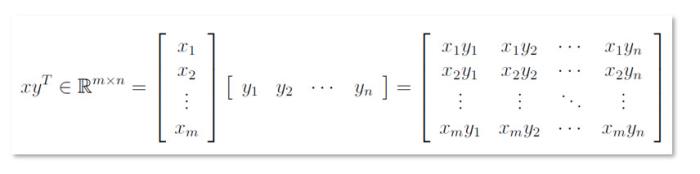
矢量积
矩阵
矩阵是线性代数的重要概念。一个m*n矩阵包含mn个元素,可用于线性方程组或线性映射的计算,也可将其视为一个由m*n个实值元素组成的元组。

矩阵表示
向量
在线性代数中,向量是大小为n*1的矩阵,即只有一列。

矩阵表示
矩阵乘法
矩阵乘法是行和列的点积,其中一个矩阵的行与另一个矩阵列相乘并求和。

矩阵乘法
矩阵乘法在线性回归中的应用
通过多种特征可以预测房屋价格。下表展示了不同房屋的特征及其价格。

不同房屋的特征及其价格

特征变量与目标变量
令:

特征及其系数

房价预测函数
转置矩阵
对于矩阵A∈R^m*n,有矩阵B∈R^n*m满足b_ij = a_ij,称为A的转置,即B=A^T。

A的转置
逆矩阵
对n阶矩阵A,有矩阵B∈R^n*n满足AB =I_n(单位矩阵)= BA的性质,称B为A的逆,表示为A^-1。

矩阵A和B

A和B相乘

A、B互为逆矩阵(得到单位矩阵)
正交矩阵
当且仅当矩阵列向量组是单位正交向量组时,n阶矩阵A∈R^n*n是正交矩阵,有:

正交矩阵

矩阵A及其转置

矩阵A及其转置的乘积
对角矩阵
在n阶矩阵A∈R^n*n中,除主对角线上的元素,其他所有元素均为零,称其为对角矩阵,即:
Aij =0,i != j

对角矩阵
正规方程的转置矩阵和逆矩阵
正规方程通过计算theta j的导数,将其设为零来最小化J。无需Gradient Descent就可直接得到θ的值,θ见下图。

最小化误差
通过上式实现前文“房价预测”。

以矩阵形式表示特征x和目标值y
创建特征x和目标y的矩阵:
import numpy as np Features
x = np.array([[2, 1834, 1],[3, 1534, 2],[2, 962, 3]])# Target or Pricey = [8500, 9600, 258800]
计算x的转置:
# Transpose of xtranspose_x = x.transpose()transpose_x

特征x矩阵的转置
转置矩阵与原矩阵x的乘积:
multi_transpose_x_to_x = np.dot(transpose_x, x)

转置矩阵与原矩阵x的乘积
转置矩阵与原始矩阵乘积的逆:
inverse_of_multi_transpose_x_to_x = np.linalg.inv(multi_transpose_x_to_x)

逆矩阵
x的转置与y的乘积:
multiplication_transposed_x_y = np.dot(transpose_x, y)

x的转置与y的乘积
theta值计算:
theta = np.dot(inverse_of_multi_transpose_x_to_x, multiplication_transposed_x_y)

theta
线性方程
线性方程是线性代数的核心,通过它可以解决许多问题,下图是一条直线方程。


线性方程y=4x-5及其图示
当x=2时:

由上述线性方程式得出的y
线性回归中的线性方程
回归就是给出线性方程的过程,该过程试图找到满足特定数据集的最优曲线,即:
Y = bX + a
其中,a是Y轴截距,决定直线与Y轴相交的点;b是斜率,决定直线倾斜的方向和程度。
示例
通过线性回归预测平方英尺和房屋价格的关系。
数据读取:
import pandas as pd
df = pd.read_csv('house_price.csv')
df.head()

房价表
计算均值:
def get_mean(value):
total = sum(value)
length = len(value)
mean = total/length
return mean
计算方差:
def get_variance(value):
mean = get_mean(value)
mean_difference_square = [pow((item - mean), 2) for item in value]
variance = sum(mean_difference_square)/float(len(value)-1)
return variance
计算协方差:
def get_covariance(value1, value2):
value1_mean = get_mean(value1)
value2_mean = get_mean(value2)
values_size = len(value1)
covariance = 0.0 for i in range(0, values_size):
covariance += (value1[i] - value1_mean) * (value2[i] - value2_mean)
return covariance / float(values_size - 1)
线性回归过程:
def linear_regression(df):
X = df['square_feet']
Y = df['price']
m = len(X)
square_feet_mean = get_mean(X)
price_mean = get_mean(Y)
#variance of X
square_feet_variance = get_variance(X)
price_variance = get_variance(Y)
covariance_of_price_and_square_feet = get_covariance(X, Y)
w1 = covariance_of_price_and_square_feet / float(square_feet_variance) w0 = price_mean - w1 * square_feet_mean
# prediction --> Linear Equation
prediction = w0 + w1 * X
df['price (prediction)'] = prediction
return df['price (prediction)']
以上级线性回归方法:
linear_regression(df)

预测价格
线性回归中的线性方程:

向量范数
向量范数可用于衡量向量的大小,也就是说,范数|| x ||表示变量x的大小,范数|| x-y ||表示两个向量x和y之间的距离。
向量范数计算公式:

常用的向量范数为一阶和二阶:
一阶范数也叫Manhattan范数
二阶范数也叫Euclidean范数
在正则化中会用到一阶和二阶范数。
一阶范数/Manhattan范数
x∈R^n的L1范数定义为:


一阶范数示意图
L2范数/Euclidean范数
x∈R^n的L2范数定义为:


二阶范数示意图
机器学习中的正则化
正则化是指通过修改损失函数以惩罚学习权重的过程,是避免过拟合的有效方式。
正则化在机器学习中的作用:
解决共线性问题
除去噪声数据
避免过拟合
提升模型表现
标准正则化技术包括:
L1正则化(Lasso)
L2正则化(Ridge)
L1正则化(Lasso)
Lasso正则化应用广泛,其形式为:
L2正则化(Ridge)
Ridge正则化表达式:

其中,通过λ调整惩罚项的权重进行控制。
特征提取和特征选择
特征提取和特征选择的主要目的是选择一组最佳的低维特征以提高分类效率,以避免维数灾难。在实践中,通过矩阵操作实现特征选择和特征提取。
特征提取
在特征提取中,我们通过映射函数从现有特征中找到一组新特征,即:

特征选择
特征选择是指从原始特征中选择部分特征。

主要特征抽取方法包括主成分分析PCA和线性判别分析LDA。其中,PCA是一种典型的特征提取方法,了解协方差矩、特征值或特征向量对于理解PCA至关重要。
协方差矩阵
在PCA推导过程中,协方差矩阵起到至关重要的作用。以下两个概念是计算协方差矩阵的基础:
方差
协方差
方差


方差的局限性在于,无法表示变量之间的关系。
协方差
协方差用于衡量两个变量之间的关系:

协方差矩阵
协方差矩阵是方阵,其中每个元素表示两个随机矢量之间的协方差。

协方差矩阵的计算公式:

特征值与特征向量
特征值:令m为n*n矩阵,如果存在非零向量x∈R^n,使得mx =λx,则标量λ为矩阵m的特征值。
特征向量:上式中向量x称为特征值λ的特征向量。
特征值与特征向量的计算
若n阶矩阵m有特征值λ和相应特征向量x,有mx =λx,则mx —λx= 0,得到下式:

求解方程的λ可得到m的所有特征值
示例:
计算一下矩阵的特征值和特征向量。

解:






因此,矩阵m有两个特征值2和-1。每个特征值对应多个特征向量。
正交性
如果向量v和w的点积为零,称两向量正交。
v.w = 0
例如:

正交集
如果某一集合中的所有向量相互正交,且均为单位长度,称为规范正交集合。其张成的子空间称为规范正交集。
扩张空间
令V为向量空间,元素v1,v2,…..,vn∈V。
将这些元素与标量相乘加和,所有的线性组合集称为扩张空间。

示例:

Span (v1, v2, v3) = av1 + bv2 + cv3

基
向量空间的基是一组向量,通过基向量的线性可以组成向量空间中任意一个元素。
示例:
假设向量空间的一组基为:

基向量元素是相互独立的,如:


主成分分析PCA
通过PCA能够对数据进行降维,以处理尽可能多的数据。其原理是:找到方差最大的方向,在该方向上进行投影以减小数据维度。
PCA的计算方法:
设有一个N*1向量,其值为x1,x2,…..,xm。
1.计算样本均值

2.向量元素减均值

3.计算样本协方差矩阵

4.计算协方差矩阵的特征值和特征向量

5.降维:选择前k个特征向量近似x(k
python实现主成分分析
为实现PCA,需要实现以下功能:
获取协方差矩阵
计算特征值和特征向量
通过PCA了解降维
Iris数据导入
import numpy as np
import pylab as pl
import pandas as pd
from sklearn import datasets
import matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScaler load_iris = datasets.load_iris() iris_df = pd.DataFrame(load_iris.data, columns=[load_iris.feature_names]) iris_df.head()

标准化
标准化数据使得所有特征数据处于同一量级区间,有利于分析特征。
standardized_x = StandardScaler().fit_transform(load_iris.data)
standardized_x[:2]

计算协方差矩阵
covariance_matrix_x = np.cov(standardized_x.T)
covariance_matrix_x

计算协方差矩阵得特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(covariance_matrix_x)
eigenvalues

eigenvectors

特征值的方差
total_of_eigenvalues = sum(eigenvalues)
varariance = [(i / total_of_eigenvalues)*100 for i in sorted(eigenvalues, reverse=True)]
varariance

上图中的方差值分别表示:
1st 成分 = 72.96%
2nd 成分 = 22.85%
3rd 成分 = 3.5%
4th 成分 = 0.5%
可以看到,第三和第四成分具有很小的方差,可以忽略不记,这些组分不会对最终结果产生太大影响。
保留占比大的第一、第二成分,并进行以下操作:
eigenpairs = [(np.abs(eigenvalues[i]), eigenvectors[:,i]) for i in range(len(eigenvalues))]
# Sorting from Higher values to lower valueeigenpairs.sort(key=lambda x: x[0], reverse=True) eigenpairs

计算Eigenparis的矩阵权重
matrix_weighing = np.hstack((eigenpairs[0][1].reshape(4,1),eigenpairs[1][1].reshape(4,1)))
matrix_weighing

将标准化矩阵乘以矩阵权重

绘图
plt.figure()target_names = load_iris.target_names
y = load_iris.targetfor c, i, target_name in zip("rgb", [0, 1, 2], target_names):
plt.scatter(Y[y==i,0], Y[y==i,1], c=c, label=target_name)plt.xlabel('PCA 1')
plt.ylabel('PCA 2')
plt.legend()
plt.title('PCA')
plt.show()

Iris数据的主成分分析示意图
矩阵分解
矩阵分解在机器学习中也至关重要,该过程本质上是将矩阵分解为矩阵的乘积。
常用的矩阵分解技术有LU分解,奇异值分解(SVD)等。
奇异值分解(SVD)
SVD可用于减小数据维度,奇异值分解如下:
令M为矩阵,其可以分解为三个矩阵的乘积,即正交矩阵(U),对角矩阵(S)和正交矩阵(V)的转置。

结论
机器学习和深度学习是建立在数学概念之上的,掌握理解数学知识对于算法构建和数据处理有极大帮助。
线性代数的研究包括向量及其操作。在机器学习中,各处可见线性代数的背影,如线性回归,独热编码,主成分分析PCA,推荐系统中的矩阵分解。
深度学习更甚,其完全基于线性代数和微积分。梯度下降,随机梯度下降等优化方法也建立在此之上。
矩阵是线性代数中的重要概念,通过矩阵可以紧凑地表示线性方程组、线性映射等。同样,向量也是重要的概念,将不同向量与标量乘积进行加和可以组成不同的向量空间。
欢迎在评论区回复你的看法,我会虚心接受并进行改进。
免责声明:本文中表达的观点仅为作者个人观点,不(直接或间接)代表卡耐基梅隆大学或与作者相关的其他组织。我知道,本文不尽完善,仅是本人当前的一些看法与思考,希望对读者有所帮助。
资源
Google colab implementation.
Github repository
参考
[1] Linear Algebra, Wikipedia, https://en.wikipedia.org/wiki/Linear_algebra
[2] Euclidean Space, Wikipedia, https://en.wikipedia.org/wiki/Euclidean_space
[3] High-dimensional Simplexes for Supermetric Search, Richard Connor, Lucia Vadicamo, Fausto Rabitti, ResearchGate, https://www.researchgate.net/publication/318720793_High-Dimensional_Simplexes_for_Supermetric_Search
[4] ML | Normal Equation in Linear Regression, GeeksforGeeks, https://www.geeksforgeeks.org/ml-normal-equation-in-linear-regression/
[5] Vector Norms by Roger Crawfis, CSE541 — Department of Computer Science, Stony Brook University, https://www.slideserve.com/jaimie/vector-norms
[6] Variance Estimation Simulation, Online Stat Book by Rice University, http://onlinestatbook.com/2/summarizing_distributions/variance_est.html
[7] Lecture 17: Orthogonality, Oliver Knill, Harvard University, http://people.math.harvard.edu/~knill/teaching/math19b_2011/handouts/math19b_2011.pdf
[8] Orthonormality, Wikipedia, https://en.wikipedia.org/wiki/Orthonormality
[9] Linear Algebra/Basis, Wikibooks, https://en.wikibooks.org/wiki/Linear_Algebra/Basis
[10] Linear Algebra, LibreTexts, https://math.libretexts.org/Bookshelves/Linear_Algebra
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










