新火种
2025-02-20
新火种
2025-02-20 


AI幻觉:它真的会一本正经胡说八道!
你是不是也遇到过这样的情况:问AI一个问题,它给了你一个特别详细、丰富,看上去好有逻辑的答案。
但当我们去核实时,却发现这些信息完全是虚构的?
这就是著名的“AI幻觉”现象。
 上下滑动查看更多,图源:河森堡新浪微博
上下滑动查看更多,图源:河森堡新浪微博
为什么会出现AI幻觉呢?今天就让我们一起来揭开这个谜题。
为什么会出现AI幻觉?
AI幻觉指的是AI会生成看似合理但实际确实错误的信息,最常见的表现就是会编造一些不存在的事实或者细节。
就像在考试时遇到不会的题目,我们会试图用已知的知识去推测答案一样。
AI在遇到信息缺失或不确定的情况时,会基于自己的“经验”(训练数据)进行填补和推理。
这不是因为它想要欺骗我们,而是因为它在试图用自己理解的模式来完成这个任务。
1、基于统计关系的预测
因为AI(尤其是像ChatGPT这样的语言模型)通过大量的训练数据学习文字之间的统计关系。它的核心目标是根据上下文预测最可能出现的下一个词,并不是对问题或内容进行真正的理解。
所以,AI本质上是通过概率最大化来生成内容,而不是通过逻辑推理来生成内容的。
简单来说,AI就像是一个博览群书的智者,通过学习海量的文本和资料来获取知识。但是它并不是真正理解这些知识,而是通过找到文字之间的统计关系和模式来“预测”下一个最合适的词。
换言之,AI是根据之前学到的大量例子,来猜测接下来最有可能出现的词。
不过有时候,模型也会“猜错”。如果前面出现一点偏差,后面的内容就会像滚雪球一样越滚越大。
这就是为什么AI有时会从一个小错误开始,最后编织出一个完全虚构的故事。
2、训练数据的局限性
由于AI并没有真实世界的体验,它的所有“认知”都来自训练数据。
可是训练数据不可能包含世界上所有的信息,有时候甚至还会包含错误信息。这就像是一个人只能根据自己读过的书来回答问题。
如果书里有错误信息,或者某些领域的知识缺失,就容易产生错误的判断。
举个例子:早期AI幻觉较大的时候,可能会出现AI学过“北京是中国的首都”和“巴黎有埃菲尔铁塔”这两个知识点。
当我们问它“北京有什么著名建筑”时,它可能会把这些知识错误地混合在一起,说“北京有埃菲尔铁塔”。
3、过拟合问题
因为大模型的训练参数量非常庞大,大模型会在训练数据上产生“过拟合”的问题。
也就是因为记住了太多错误或者无关紧要的东西,从而让AI对训练数据中的噪声过于敏感,最终导致幻觉产生。
4、有限的上下文窗口
受限于技术原因,虽然现在大模型的上下文窗口越来越大(比如可以处理64k或128k个tokens),但它们仍然是在一个有限的范围内理解文本。
这就像是隔着一个小窗口看书,看不到整本书的内容,容易产生理解偏差。
5、生成流畅回答的设计
现在很多大模型被设计成要给出流畅的回答,当它对某个问题不太确定时,与其说“我不知道”,它更倾向于基于已有知识编造看起来合理的答案。
上面的种种情况叠加在一起,造成了现在非常严重的AI幻觉问题。
如何才能降低AI幻觉?
AI看起来很方便,但AI一本正经的“胡说八道”有时候真的让人非常头疼,给的信息经常需要反复核实,有时反而不如直接上网搜索来得实在。
那么,如何应对AI幻觉呢?我们总结了下面这些方法帮助大家。
1、优化提问
想要获得准确答案,提问方式很关键。与AI交流也需要明确和具体,避免模糊或开放性的问题,提问越具体、清晰,AI的回答越准确。
同时,我们在提问的时候要提供足够多的上下文或背景信息,这样也可以减少AI胡乱推测的可能性。总结成提示词技巧就是下面四种问法:
1.设定边界:“请严格限定在2022年《自然》期刊发表的研究范围内”;
示例:“介绍ChatGPT的发展历程”→“请仅基于OpenAI官方2022-2023年的公开文档,介绍ChatGPT的发展历程”
2.标注不确定:“对于模糊信息,需要标注‘此处为推测内容’”;
示例:“分析特斯拉2025年的市场份额”→“分析特斯拉2025年的市场份额,对于非官方数据或预测性内容,请标注[推测内容]”
3.步骤拆解:“第一步列举确定的事实依据,第二步展开详细分析”;
示例:“评估人工智能对就业的影响”→“请分两步评估AI对就业的影响:
1)先列出目前已发生的具体影响案例;
2)基于这些案例进行未来趋势分析”。
4.明确约束:明确告诉AI要基于已有事实回答,不要进行推测。
示例:“预测2024年房地产市场走势”→“请仅基于2023年的实际房地产数据和已出台的相关政策进行分析,不要加入任何推测性内容”。
2、分批输出
因为AI内容是根据概率来进行生成的,一次性生成的内容越多,出现AI幻觉的概率就越大,我们可以主动限制它的输出数量。
比如:如果我要写一篇长文章,就会这么跟AI说:“咱们一段一段来写,先把开头写好。等这部分满意了,再继续写下一段。”
这样不仅内容更准确,也更容易把控生成内容的质量。
3、交叉验证
想要提高AI回答的可靠性,还有一个实用的方法是采用“多模型交叉验证”。
使用的一个AI聚合平台:可以让多个AI模型同时回答同一个问题。
当遇到需要严谨答案的问题时,就会启动这个功能,让不同的大模型一起参与讨论,通过对比它们的答案来获得更全面的认识。
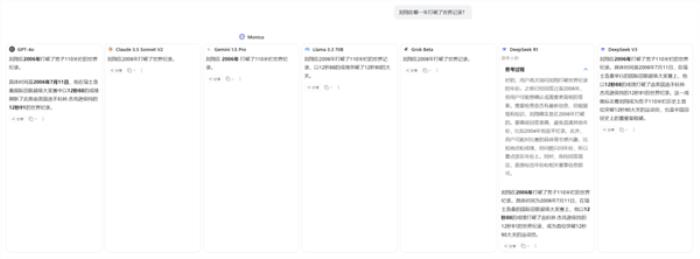 点击可放大,图片来源:作者提供
点击可放大,图片来源:作者提供
再比如纳米AI搜索平台的“多模型协作”功能,它能让不同的AI模型各司其职,形成一个高效的协作团队。
让擅长推理的DeepSeek-R1负责分析规划,再由通义千问进行纠错补充,最后交给豆包AI来梳理总结。
这种“专家组”式的协作模式,不仅能提升内容的可信度,还能带来更加全面和深入的见解。
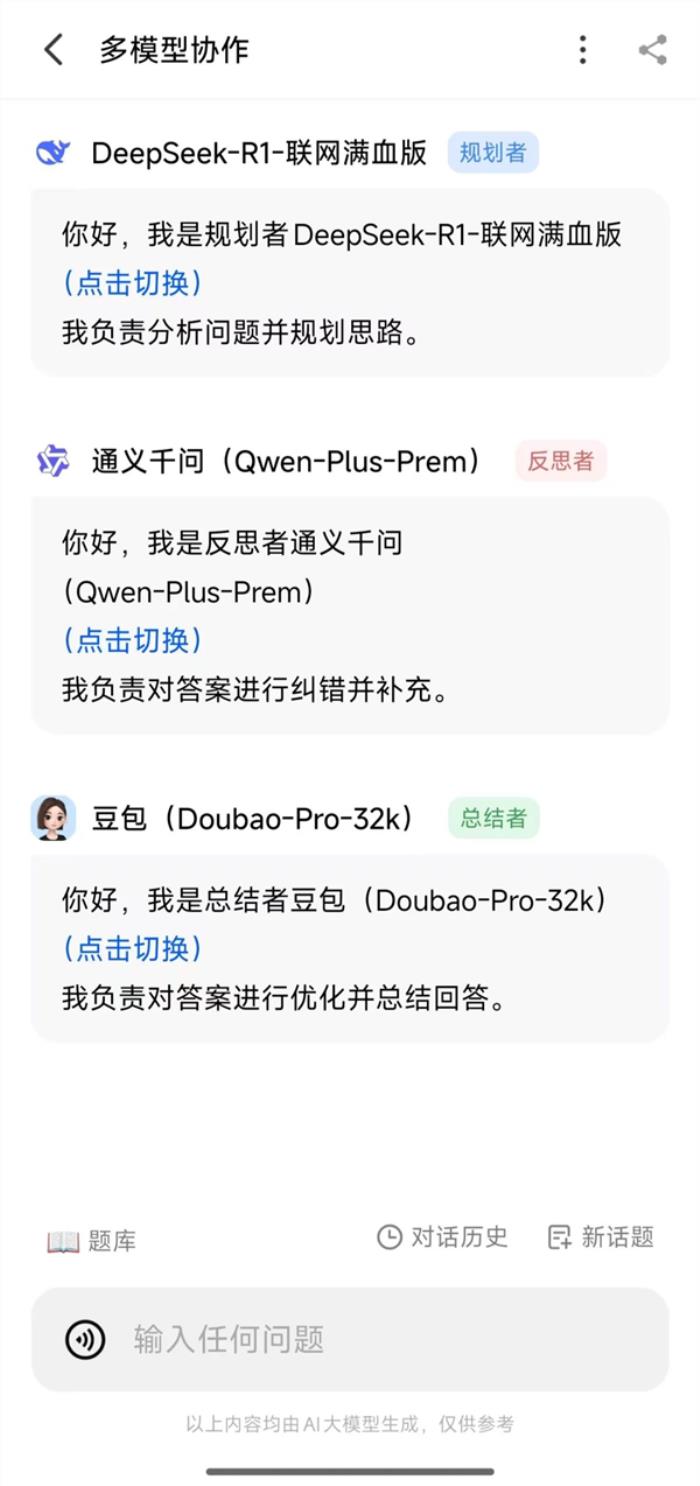 上下滑动查看更多,图源:作者提供
上下滑动查看更多,图源:作者提供
4、RAG技术
AI是一个聪明但健忘的人,为了让他表现更靠谱,我们可以给他配一个超级百科全书,他可以随时查阅里面的内容来回答问题。
这本“百科全书”就是RAG的核心,它让AI在回答问题之前,先从可靠的资料中找到相关信息,再根据这些信息生成答案。
这样一来,AI就不容易“胡说八道”了。
目前RAG技术多用在医疗、法律、金融等专业领域,通过构建知识库来提升回答的准确性。
当然实际使用中像医疗、法律、金融这样的高风险领域,AI生成的内容还是必须要经过专业人士的审查的。
5、巧用AI幻觉
最后再说一个AI幻觉的好处。很多时候AI幻觉也是天马行空的创意火花!
就像一个异想天开的艺术家,不受常规思维的束缚,能蹦出令人惊喜的点子。
看看DeepSeek就知道了,它确实比ChatGPT和Claude更容易出现幻觉,但是今年DeepSeek能火得如此出圈也离不开其强大的创造能力。
有时候与其把AI幻觉当成缺陷,不如把它看作创意的源泉!在写作、艺术创作或头脑风暴时,这些“跳跃性思维”反而可能帮我们打开新世界的大门。
AI幻觉的本质——AI在知识的迷雾中,有时会创造出看似真实,实则虚幻的“影子”。
但就像任何工具一样,关键在于如何使用。当我们学会用正确的方式与AI对话,善用它的创造力,同时保持独立思考,AI就能成为我们得力的助手,而不是一个“能言善辩的谎言家”。
毕竟,在这个AI与人类共同进步的时代,重要的不是责备AI的不完美,而是学会与之更好地协作。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。