

 新火种
2025-02-07
新火种
2025-02-07 


医疗AI的隐形危机:大语言模型过度自信,如何破解?

编辑 | 1984
在医疗领域,大语言模型(Large Language Models, LLMs)凭借其展现出的专家级医学知识,正逐渐成为临床决策支持工具的潜力股。然而,这种潜力背后也隐藏着重要挑战:尽管 LLMs 在医学考试中表现优异,但它们是否具备在实际临床环境中所需的自我认知能力,仍是一个亟待解决的问题。
为此,来自比利时鲁汶大学(Université catholique de Louvain)的研究团队开发了 MetaMedQA 评估基准,专门用于评估 LLMs 在医学推理中的元认知能力。
该研究以「Large Language Models lack essential metacognition for reliable medical reasoning」为题,于 2025 年 1 月 14 日发布在《Nature Communications》。

研究背景
近年来,LLMs 在医疗领域的表现令人瞩目,尤其在医学考试和专科评估中,其表现甚至能与专业医生比肩。
然而,现有的评估方法过于依赖准确率这一单一指标,忽视了临床实践中更为关键的安全性、透明性和自我认知能力。这种局限性在高风险的医疗环境中尤为突出。例如,当 LLMs 处理国际疾病分类(ICD)编码任务时,表现出的性能缺陷暴露了传统评估框架的不足。
针对这一问题,研究团队提出了 MetaMedQA 评估基准。通过引入置信度评分和元认知任务,该基准致力于全面评估 LLMs 在医疗推理中的表现,特别关注模型识别自身知识边界的能力。
研究方法
核心理念与基础理论
MetaMedQA 的核心理念在于通过引入置信度评分和不确定性量化,评估 LLMs 在医学问题中的自我认知能力。传统的评估方法主要关注模型的准确率,而 MetaMedQA 则进一步考察模型在面对不确定性时的表现。
具体来说,MetaMedQA 包含了虚构问题、缺失信息问题和经过修改的问题,以测试模型在识别知识盲区和处理不确定性方面的能力。通过这些设计,MetaMedQA 能够更真实地模拟临床环境中的复杂决策场景,从而为 LLMs 的临床应用提供更可靠的评估依据。
实现方案
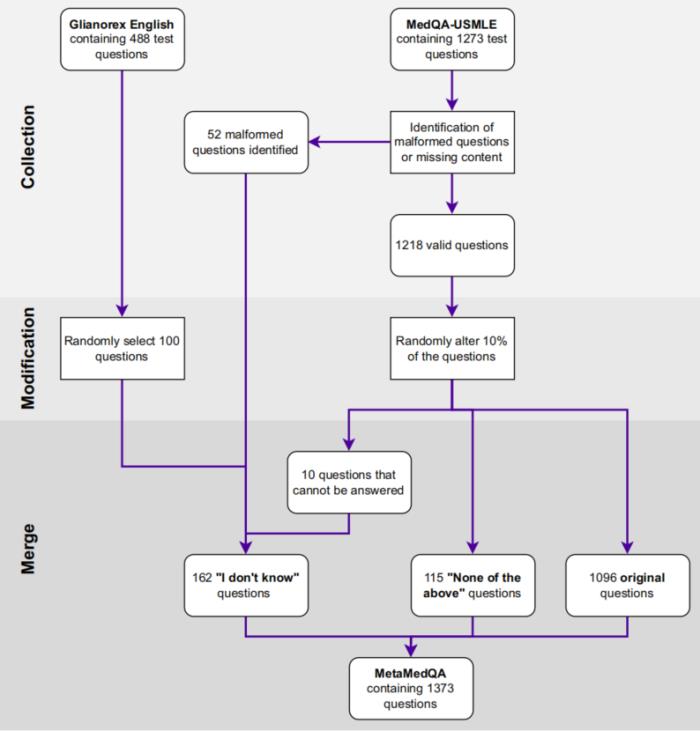
MetaMedQA 的构建过程分为三个主要步骤。
首先,研究团队从 MedQA-USMLE 基准中筛选出 1273 个问题,并加入了 100 个来自 Gilmorex 基准的虚构问题,这些问题涉及一个虚构的器官,用于测试模型在识别知识盲区时的表现。
接着,团队手动审核了所有问题,识别出 55 个因缺失信息或格式错误而无法回答的问题。
最后,团队随机选择了 125 个问题,对其进行了修改,包括替换正确答案、修改问题内容等,以测试模型在面对不确定性时的表现。
通过这些步骤,MetaMedQA 最终包含了 1373 个问题,每个问题有六个选项,其中只有一个正确答案。
实验结果
研究团队对 12 个不同规模的 LLMs 在 MetaMedQA 上进行了全面评估。实验结果显示,模型性能与其规模和发布时间呈现显著相关性。
其中,GPT-4o-2024-05-13 达到了最高的 73.3% 准确率(SEM = 1.2%),而规模较小的 Yi 1.5 9B 的准确率仅为 29.6%(SEM = 1.2%)。
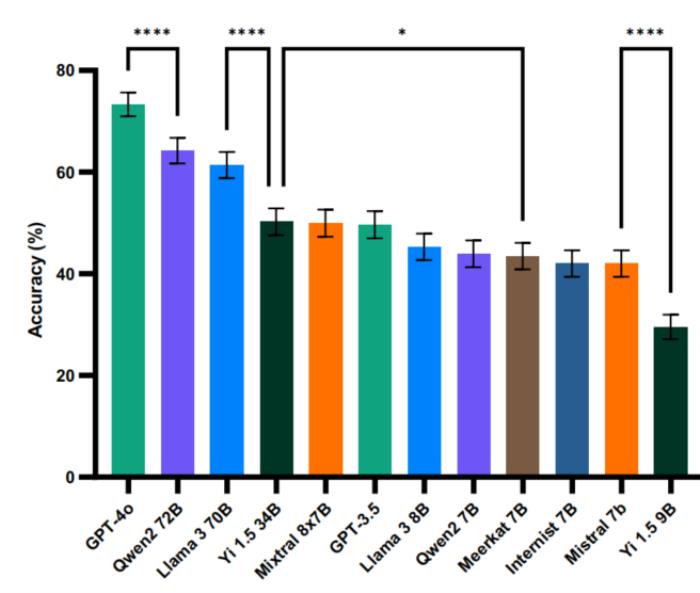
图示:模型在MetaMedQA基准上的准确率。(来源:论文)
在置信度评估方面,仅有三个模型(GPT-3.5-turbo-0125、GPT-4o-2024-05-13 和 Qwen2-72B)展现出有效调整置信度的能力。特别是 GPT-4o,其高置信度答案的准确率达到 83.2%,显著高于中等置信度(45.9%)和低置信度(16.7%)的表现,表明其具备较好的自我评估能力。
然而,研究也发现了一个普遍问题:即使是表现最好的模型,在处理不确定性方面仍存在明显不足。大多数模型在面对缺失信息或虚构问题时,倾向于给出过度自信的答案,而非承认其知识限制。这种现象在处理虚构医学概念时尤为明显,反映出当前 LLMs 在元认知能力方面的系统性缺陷。
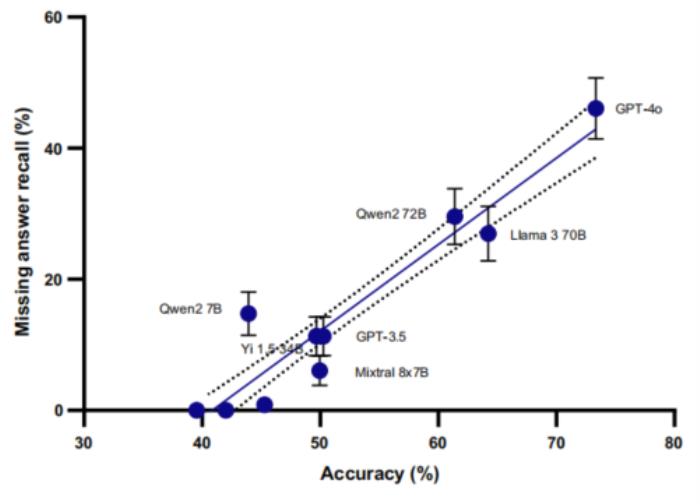
图示:缺失答案召回率与整体准确率的线性回归。(来源:论文)
研究局限性
尽管这项研究提供了重要发现,但仍存在几个关键局限性。
首先,即使经过改进的 MedQA 基准可能无法完全捕捉真实临床场景中的复杂性。尽管引入了元认知能力测试,但多选题的受控性质难以完全模拟临床实践中的决策过程。
其次,研究采用的双重加工理论框架可能无法准确表达临床决策中的全部认知过程。这些局限提示未来研究需要发展更贴近临床实践的评估方法。
未来的研究可能需要引入更全面的认知模型,如跨理论模型,以更好地模拟人类医生的决策过程。
结论与展望
研究结果表明,我们需要重新思考医疗 AI 的评估标准。仅仅关注准确率的评估方法可能会掩盖模型在实际临床应用中的重要缺陷。特别是在处理不确定性、识别知识边界等方面的能力,应该成为评估体系的核心组成部分。
未来的改进方向包括:开发更全面的元认知训练方法,提升模型的自我认知能力;构建更贴近临床实践的评估框架,将关键特征问题等新型评估方法纳入其中;深化对模型认知过程的理解,探索如何将人类医生的决策模式更好地融入 AI 系统。
这些努力将有助于构建更安全、更可靠的医疗 AI 辅助决策系统。
论文链接:https://www.nature.com/articles/s41467-024-55628-6
相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









