

 新火种
2025-01-17
新火种
2025-01-17 

端侧版GPT-4o问世,面壁小钢炮实现端到端、全模态实时对话
我们已经迎来了端侧 GPT-4o 时刻?
本周,面壁智能宣布新一代端侧模型开源,先在外网机器学习社区引起了人们的关注。
MiniCPM-o 2.6 是面壁 MiniCPM 系列最新、性能最强的多模态大模型,其参数量为 8B。它在视觉、语音等多模态领域方面表现出色,达到了接近 GPT-4o 的水平。
据介绍,MiniCPM-o 2.6 支持双语语音识别,实时对话性能也可以比肩 GPT-4o。
基于先进的 token 密度技术,处理 180 万像素图像仅产生 640tokens,显著提高了推理速度和效率。目前,MiniCPM-o 2.6 支持在 iPad 等设备端进行实时多模态互动。
MiniCPM-o 2.6 开源地址:
GitHub:https://github.com/OpenBMB/MiniCPM-oHuggingFace:https://huggingface.co/openbmb/MiniCPM-o-2_6Demo:https://minicpm-omni-webdemo-us.modelbest.cn去年 5 月,OpenAI 的 GPT-4o 以实时语音视频交互 + 全模态实时流式视频理解的姿态惊艳全球。仅仅半年多时间之后, MiniCPM-o 2.6 成功让「实时全模态 GPT-4o」跑在了端侧。
面壁使用体量仅 8B 的端侧模型一举收获音、视、听「铁人三项」全 SOTA:MiniCPM-o 2.6 取得实时流式全模态开源模型 SOTA,性能比肩代表业内顶尖水平的 GPT-4o、Claude-3.5-Sonnet;在语音方面,取得理解、生成开源双 SOTA,问鼎最强开源语音通用模型;在一贯优势凸显的视觉领域,稳坐最强端侧视觉通用模型。
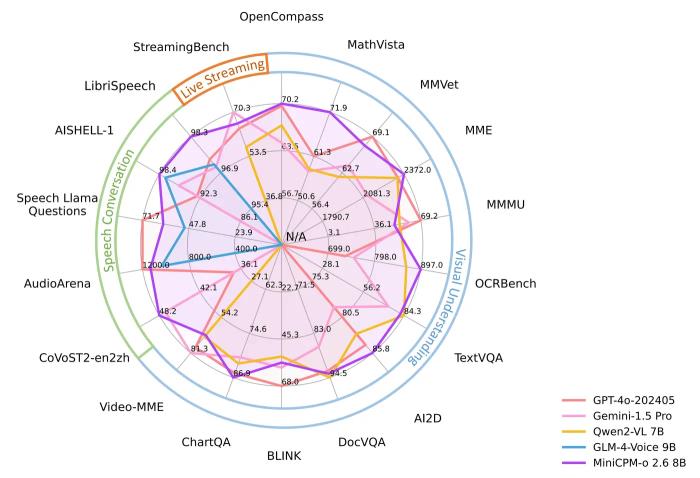
在实时流式视频理解能力的代表榜单 StreamingBench 上,MiniCPM-o 2.6 性能惊艳,比肩 GPT-4o、Claude-3.5-Sonnet。
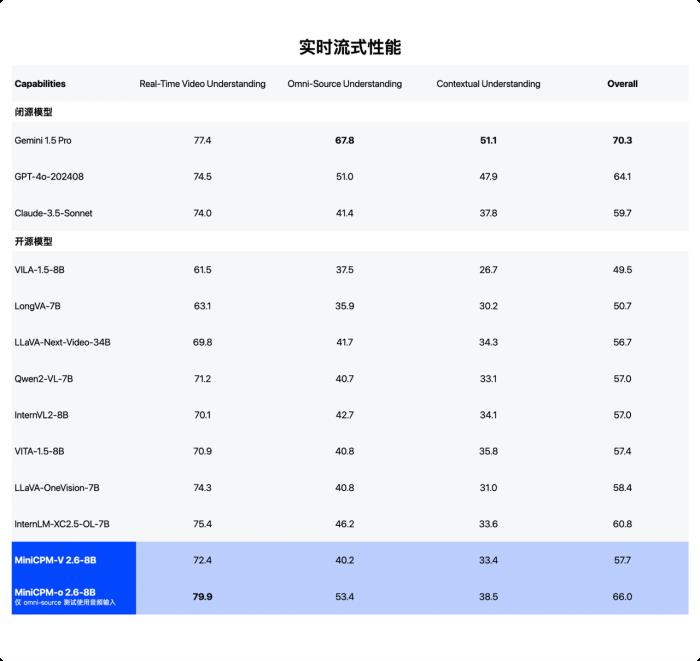 注:GPT-4o API 无法同时输入语音和视频,目前定量评测输入文本和视频。
注:GPT-4o API 无法同时输入语音和视频,目前定量评测输入文本和视频。
在语音理解方面,超越 Qwen2-Audio-7B-Instruct,实现通用模型开源 SOTA(包括 ASR、语音描述等任务);在语音生成方面,MiniCPM-o 2.6 超越 GLM-4-Voice 9B,实现了通用模型开源 SOTA。
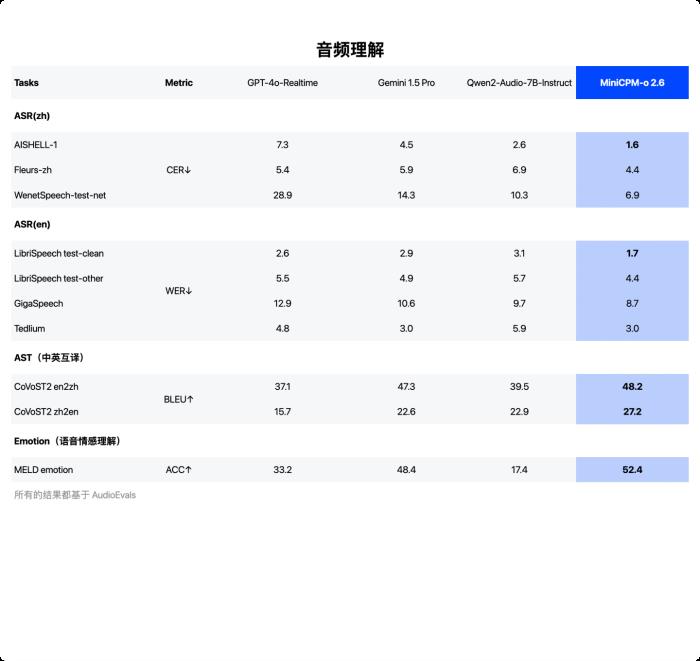 音频理解能力 SOTA,超越 Qwen2-Audio 7B
音频理解能力 SOTA,超越 Qwen2-Audio 7B
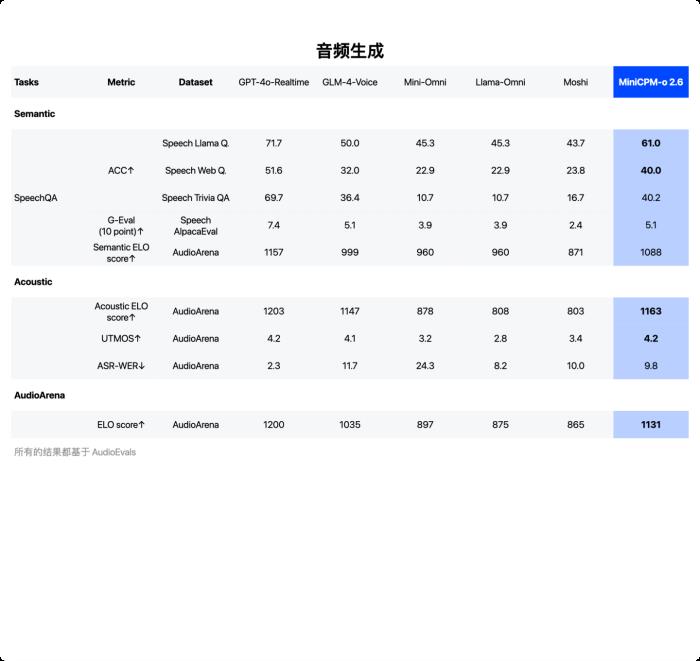 音频生成能力 SOTA,超越 GLM-4-Voice 9B
音频生成能力 SOTA,超越 GLM-4-Voice 9B
自发布以来,小钢炮多模态系列一直保持着最强端侧视觉通用模型的纪录。MiniCPM-o 2.6 视觉理解能力也达到端侧全模态模型最佳水平。
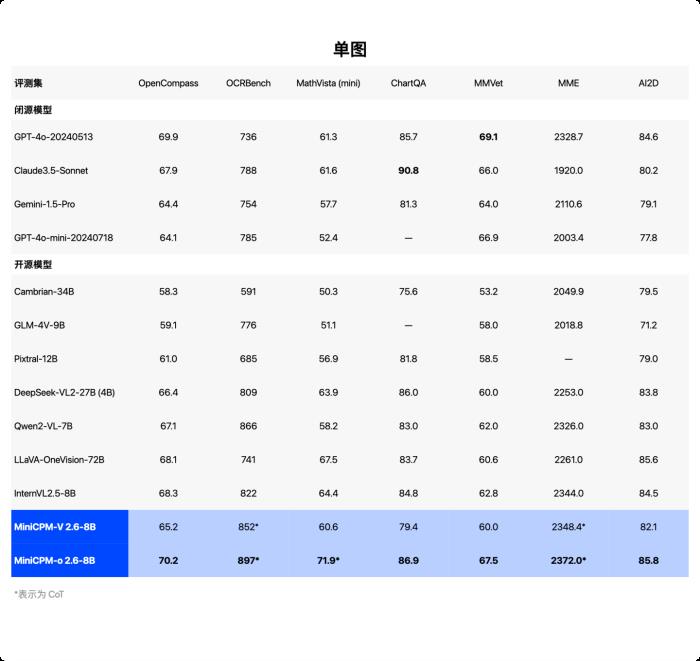 OpenCompass 榜单。
OpenCompass 榜单。
在日常生活中,AI 语音助手早已不是新鲜事物,但我们常常对它们的表现感到不满意。而新一代小钢炮 MiniCPM-o 2.6 则凭借类似 GPT-4o 的全模态实时流式视频理解与高级语音对话,有望让电影「Her」中的体验来到端侧、来到离每个人更近的地方 —— 持续看、实时听、自然说,带来实时流式、端到端的丝滑交流。
GPT-4o 发布后,视频通话也火了。立于端侧、却率先「睁眼看世界」的小钢炮发现,视频和视频不一样――市场上主流的「音视频通话」模型,实际上只能算作静态的「照片大模型」:仅在用户提问后才开始对视频进行一帧或极少数几帧画面的抽取,无法捕捉用户提问之前的画面,缺乏对前文情境的感知。
而真正的视频大模型,则能够感知用户提问之前的画面和声音,并持续对实时视频和音频流进行建模,这种方式更贴近人眼的自然视觉交互。
有了全方面的观察,才能导出正确的推理思考。在三仙归洞、记忆卡牌等游戏中,新一代小钢炮的观察力可以说是明察秋毫,点滴细节不错过,能猜出游戏中小球藏到了哪个杯子,还能记住翻牌游戏中相似图案卡片的细节、位置。
我们的世界存在着各种各样的声音,这是我们和大自然交互的乐趣所在。除了说话的声音,像翻书、倒水、敲门声等,向我们诉说着动作与场景,流淌着丰富的生活细节。这些 GPT-4o 一听就直呼放弃的环境声音,小钢炮也能一一明晰。仿佛大模型里的鉴音师。
当我们聊天,渴望触探的不只是语言,还有话语背后的情绪,一些贴近心灵的表达。
「Her」中能和人类有情感自然对话的 AI 助手令人印象深刻,继 GPT-4o 的高级情感语音对话模型后,MiniCPM-o 2.6 同样对此进行了生动的演绎,并且,即使中间打断也能接着聊 —— 相谈如此甚欢,甚至会忘记她是 AI。
MiniCPM-o 2.6 在高级情感语音方面,总体有以下特征:
真人质感的语音生成能力,达到开源通用模型最佳水平;低延迟、可实时打断,如真人交谈般自然具备情感与语气表达:支持可控语音生成(情感、音色、风格控制)可语音模拟定制:支持语音克隆,以及基于语言描述的声音创建等在实际体验中,MiniCPM-o 2.6 对答如流,在对话中常有惟妙惟肖的机智表达,还可以秀方言,比如用四川话教你吃火锅,广东话给你贺新年,令人忍俊不禁。
此外,她还能声音克隆,各种情感、音色、风格,信手拈来,如同配音大师!
和她讲话,如同和好友聊天,实时打断也不迷糊:中间插嘴、岔事儿,也不耽误酣畅淋漓地聊完全程。
此外,MiniCPM-o 2.6 作为更高技术的端到端模型,信息输入输出都原汁原味,避免了传统「语音转文字,再转语音」 方案因中间反复信息翻译,而导致的速度慢、信息流失风险,可以捕捉语气、情绪等更丰富的信息。高性能低延迟、更加自然连贯、更强上下文理解、随时打断、抗噪能力等,这些端到端模型的传统优势,小钢炮都具备!
端侧优势,全力释放,重注端侧大模型
MiniCPM-o 2.6 视、听、说全模态的诸多特性,实时的视频流、自然语音交互,接近人类的多模态认知、理解、推理能力,在端侧具有肉眼可见的巨大潜力。
在智能座舱场景中,全天候全地域,可以进行舱内控制、舱外识别、智能巡航,或是化身旅游向导、贴身翻译,在戈壁山野中勇闯天涯;教育场景中,前所未有的沉浸式学习体验,特别是跟虚拟现实或增强现实技术结合使用;商务场景中,为国际会议和多语言环境提供实时翻译服务,个人旅行者能够与不同语言的本地人无障碍沟通;特殊人群服务,可以为听障人士提供实时语音到文字的服务,为老年人提供日常陪伴和情感支持,乃至单身人士的高质量虚拟伴侣;客服和营销,高质量的自然语音交互,客户服务的响应速度和质量,超级逼真和拟人,机器的人效无限接近真人.... 这一切居然都将能够在端侧实现。
进入 2025 年,大模型规模定律(Scaling Law )面临训练数据和计算资源方面的可持续发展问题,但规模定律并非预测大模型发展的唯一视角。面壁团队提出大模型密度定律(Densing Law)—— 模型能力密度随时间呈指数级增长,实现相同能力的模型参数每 3.3 个月(约 100 天) 下降一半 ,并且模型推理开销随时间指数级下降,以及模型训练开销随时间迅速下降。
根据大模型的密度定律预测,在通往 AGI 的道路上,大模型能力密度不断提升,大约每 3.3 个月翻一番,模型推理开销、训练开销随时间快速下降到大规模应用临界水平。当模型在同一参数量上能释放更强的智能,训练和推理成本持续下降,芯片在同样的面积 / 功耗上,算力能支撑更大的模型,双向驱动下,大模型就能运行在各类终端上。
原来只在云端的「全能大模型」扩散到设备端,既是大模型增效挖潜、不断降低训练和推理成本,提升同一参数量上的智能水平,大模型走向科学化、可持续发展的技术趋势;更是一种自发的市场趋势,有着深刻的技术普惠,大模型的能力正在迅速传导到需求端,以精准的技术 - 产品 PMF 填满市场洼地。2024 年端侧 AI 硬件成为科技创业大风口,AIPC、AIPhone、AI 眼镜等 AI + 硬件迅速爆发,即是这一趋势的最佳验证。
正如面壁智能 CEO 李大海在刚刚过去的 2025 CES 所言:「大模型正在走向「无所不能」和「无处不在」。我们笃信大模型将「无处不在」,特别是成本更低、尺寸更小、效率更高的端侧模型。面壁智能的工作就是聚焦端侧模型,我们的愿景所有的设备上都会有端侧的智能,都会部署端侧的模型。10 年之后,至少有 1000 亿硬件会搭载端侧智能,成为拥有人类成年智能水平的新型智能人口。」
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










