

 新火种
2025-01-16
新火种
2025-01-16 


交大O1医疗探索:延长AI思考时间,解锁复杂推理诊断
编辑 | ScienceAI
当医生面对复杂病例时,往往需要反复思考、权衡多种可能性,才能得出准确诊断。以鉴别诊断为例,它要求医生生成可能的诊断列表,并通过评估临床发现,逐步排除不符合条件的选项。
如今,AI 也学会了这种「深思熟虑」的诊断方式。上海交通大学最新研究发现,给 AI 更多「思考时间」,能显著提升其医疗诊断能力,让 AI 更接近专业医生的诊断水平。
上海交通大学近日发布了 O1 复现项目系列研究的第三部分成果。
这项由 SPIRAL 实验室与生成式 AI 研究实验室(GAIR)联合完成的研究表明,通过延长AI的推理时间,仅需 500 个样本训练,就能让模型在医疗诊断准确率上提升 6%-11%。
在实际测试中,改进后的 AI 系统能够像专业医生一样,系统性地分析症状、评估证据,逐步缩小诊断范围,最终得出合理结论。
「这就像是让 AI 学会了医生看诊时的思维方式。」项目负责人表示,「在面对复杂病例时,AI 不再仅仅依靠快速匹配,而是能够进行更深入的分析和推理。这种方法在 JAMA 临床挑战等真实医疗场景测试中取得了令人振奋的效果。」
研究还揭示了一个有趣的发现:越是复杂的医疗问题,AI 就需要更长的推理链来得出准确结论。这与人类医生的诊断过程惊人地相似,为提升 AI 在临床实践中的应用提供了全新思路。
该研究是继 Journey Learning 和知识蒸馏研究之后的最新突破,进一步推进了 O1 在专业领域的应用探索。为促进医疗 AI 的开放发展,研究团队已将所有代码和数据集在 GitHub 上开源。

技术文档:http://arxiv.org/abs/2501.06458
相关资源将近日公开:https://github.com/GAIR-NLP/O1-Journey , https://github.com/SPIRAL-MED/Ophiuchus
探索过程通过对现有案例的分析,可以发现:随着问题难度的增加,推理时间(inference-time)往往会按比例增加。这表明更高难度的问题需要更多的推理步骤,这反过来也需要更长的推理时间。
推理时间的扩展在识别和分析关键信息方面贡献显著,这一现象在医学领域尤为重要,因为临床医生需要花费大量时间处理来自多种来源和模态的数据,以诊断病情、进行预后评估和确定治疗方案。
为了证明推理时扩展(inference-time scaling)在解决医学问题中的有效性, 团队选择了在先前工作提出的三个基准数据集:JAMA 临床挑战(JAMA)、Medbullets 和 MedQA。这些基准测试包含来自多个医学领域的复杂真实临床案例以及不同难度级别的医学执业考试题目。
JAMA 数据集:包含从 2013 年 7 月至 2023 年 10 月 JAMA Network Clinical Challenge 档案中收集的 1,524 个案例,涵盖 13 个医学领域。这些案例涉及复杂的临床场景,包括患者病史、家族病史、实验室结果、物理检查、影像分析等,因此需要更复杂的理解和推理才能得出正确的诊断。为评估推理时扩展在复杂任务中的有效性,团队选择了 o1-mini 模型难以应对的 646 个案例进行评估。
Medbullets 和 MedQA 数据集:基于美国国家医学委员会考试(USMLE)的题目。
Medbullets:是一个在线医学学习平台,包含 Step 2 和 Step 3 级别的题目,这些题目更强调临床知识和推理,而不是依赖于课本知识。
MedQA:包含部分来自 Medbullets 网站的题目,但不包括详细解释。
在当前阶段,团队的主要目标是评估推理时扩展(inference-time scaling)在解决医学问题中的作用。在信息和资源有限的情况下,团队没有选择直接尝试直接执行鉴别诊断(differential diagnosis)这一极其困难的任务。
在现实场景中,鉴别诊断符合假设演绎法(hypothetico-deductive method)的原则,即将潜在的疾病或病症视为假设,供临床医生评估其有效性。
为了简化任务,当前部分采用了多项选择数据集,通过预定义的潜在诊断(即「鉴别」)来指导模型生成假设。团队没有选择直接使用私有数据,因为现实中的临床场景通常包含大量无关信息,这些信息可能干扰推理过程,对当前模型构成巨大挑战。相比之下,公共基准测试简化了问题,并消除了部分干扰。同时,分析选择题选项以确定最终答案的过程与临床诊断中的思维过程高度相似。
研究团队在先前的 O1-Journey (Part1 和 Part2) 中验证了长思维链数据对于复杂推理的重要性,并且在构造长思维链数据(journey learning)上面取得了一定的成果。
为了使大语言模型在解决医学问题时能够进行「深度」的思考,团队在 Part1 和 Part2 的基础上,构造用于解决医疗领域中复杂推理问题的长思维链数据。参照 Part2 的方式,团队采用知识蒸馏的方式,使用了 o1 模型生成的高质量数据。生成两种类型的长思维链数据可以分为两类:
LongStep:提取 o1 模型的解决步骤,训练 LLMs 模仿这一行为,生成更详细的解决方案。
LongMonolog:设计提示使 o1-preview 模型将其总结的思路扩展为长形式推理,以模拟「内心独白」风格的详细解决过程。
为了进一步优化数据,团队对合成的数据进行了过滤筛选以确保质量,同时规范化了格式输出。在选择训练数据样本时,团队着重关注问题解决过程的长度,排除了推理过程较短的案例。最终构建了一个包含 500 个样本的训练数据集,其中 350 个样本来自 MedQA 的训练集,150 个样本来自 JAMA。
实验结果考虑到解决医学问题需要模型在医学领域具备良好的基础能力,团队选用了 Qwen2.5-32B-Instruct、Qwen2.5-72B-Instruct 以及 LLama3.1-70B-Instruct 作为开展实验的基础模型。
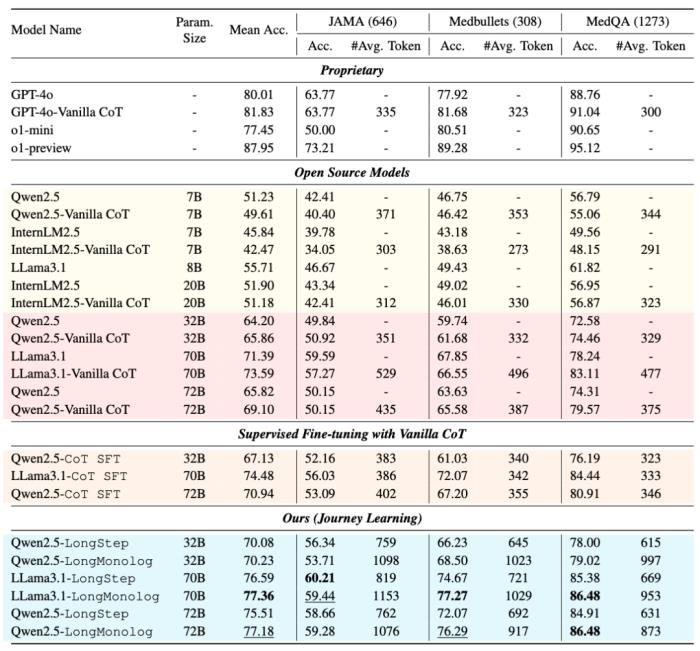
团队展示了各种方法在评估基准测试上的综合性能比较,包括专有 API、开源基线模型,以及采用构造的 Journey Learning 数据进行微调的多种模型。
为了反映推理时扩展(inference-time scaling)的有效性,团队同时比较了各个模型平均输出 Token 的数量。
结果表明,更多推理时间带来更好的性能。例如,当 Qwen2.5-72B 通过逐步推理(无论是 Vanilla CoT 还是 CoT SFT)进行推理时,输出的 token 长度范围在 300 到 500 之间,导致平均准确率增加约 5%。相比之下,在利用 Journey Learning 数据进行微调的(如 LongStep 和 LongMonolog),输出 token 长度延长至约 1000,性能改进约为 10%,这一趋势同样体现在 Qwen2.5-32B 和 LLama3.1-70B。
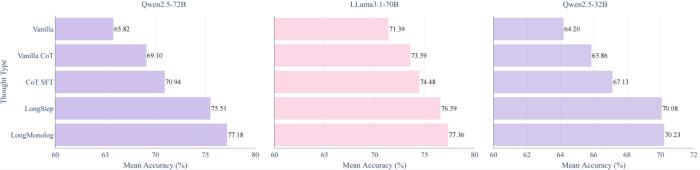
为了直观地说明推理时间计算的贡献,团队展示了 Qwen2.5-72B、LLama3.1-70B和 Qwen2.5-32B 在三种基准数据集上的准确率,使用了不同策略,Vanilla、Vanilla CoT、CoT SFT、LongStep SFT 以及 LongMonolog SFT。每种策略都显著提高了总体准确率。特别是,对于 Qwen2.5-72B,不同策略带来了以下改进:
Vanilla CoT: +3.28%
CoT SFT: +5.12%
LongStep SFT: +9.69%
LongMonolog SFT: +11.36%
发现 1: 多数表决法(Majority Voting)的作用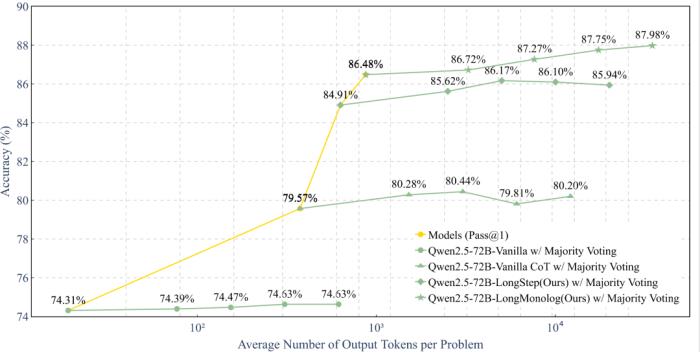
多数表决法是一种常见的推理时扩展(inference-time scaling)策略,通过多次计算的结果进行投票汇总来提高推理质量。团队在 MedQA 数据集上测试了 Qwen2.5-72B 模型。虽然 Vanilla Qwen2.5-72B 通过多数表决法显示了稳步性能提升,但提高幅度有限(准确率从 74.31% 增加到 74.63%)。
相比之下,当多数表决法与 CoT 推理 (Vanilla CoT)结合使用时,改进更为显著。然而,准确率达到顶峰(80.44%),随后略微下降(79.81%)。Journey Learning 策略(LongStep 和 LongMonolog)也观察到了类似趋势,但改进更加明显。例如:
LongStep 通过多数表决法提高了 1.26%;
LongMonolog 提高了 1.50%。
结论:尽管多数表决法可以通过聚合多次运行的输出来优化预测,但对于缺乏思考深度的中间步骤,其效果有限。而 Journey Learning 通过细致的推理过程,更有潜力利用多数表决法来增强性能。
发现 2: LongStep 与 LongMonolog 性能的比较团队在比较 LongStep 和 LongMonolog 时,很难确定哪种方式始终具有更高的性能。从当前实验数据来看,LongMonolog 在 Medbullets 和 MedQA 数据集上表现出更高的准确率,但在 JAMA 数据集中未能保持优势。例如,在 JAMA 数据集中,Qwen2.5-32B 在 LongStep模式下的准确率为 56.34%,但在 LongMonolog 模式下仅为 53.71%。
通过观察输出示例,团队发现 Qwen2.5-32B 可能在构建完整推理链时存在不足,导致性能下降。过长的推理步骤可以带来正确答案,而冗余反思有时会导致错误。这表明,尽管推理时间内延长思路链条可以帮助回答复杂医学问题,但前提是模型具备足够的领域知识。



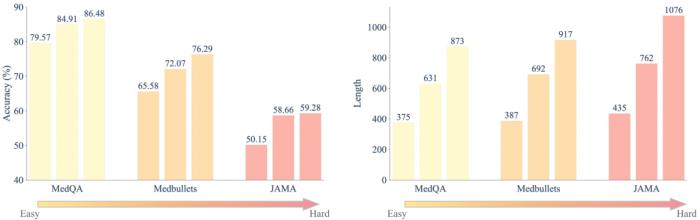
团队发现对于更难的任务,需要更多的输出 token 才能从推理时间计算中获益。为了解释任务难度的层级,假设回答 JAMA 中的问题比 Medbullets 和 MedQA 中的问题更具挑战性,因为 JAMA 呈现了更复杂的真实世界场景,即使是专有模型在 JAMA 上的表现也不理想。此外,Medbullets 的平均难度要高于比 MedQA,因为 MedQA 部分包括了 USMLE 的 Step 1 题目。通过进一步分析输出长度,Qwen2.5-72B 在回答 JAMA 问题时的平均输出 token 数量为 1,076,而在 Medbullets 中为 917,在 MedQA 中为 873。
发现4: 推理时扩展和模型大小的关系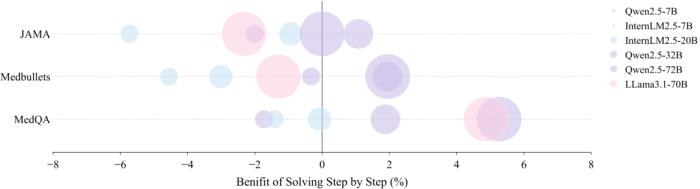
团队发现对于较小参数规模的模型(例如 7B 或 20B),推理时间的增加反而可能导致性能下降,甚至有时无法遵循指令的输出格式。在难度更高的数据集(如 JAMA)上,这种现象尤为明显。JAMA 包含复杂的真实临床案例,要求广泛的领域知识进行分析,性能缺陷尤为显著。
另一个值得注意的观察是,参数较少的模型(如 Qwen2.5-32B)从推理时扩展(inference-time scaling)中获得的收益小于较大容量的模型。
基于这些发现,团队提出了以下假设:推理时间中长时间思维的有效性依赖于足够的能力。这在医学领域尤为重要,因为解决临床问题需要理解和生成复杂且细致的文本能力,以及广泛的知识储备,包括疾病、药理学和治疗方案等方面的知识。
泛化能力与未来方向通过仔细分析构造的数据,团队发现这些数据并不局限于以提供的选项作为输出的参考。在推理过程中,模型将这些选项内化为启发式方法,生成更接近完整诊断的输出,包括差异候选项的生成及排除,而不是逐一讨论选项。
为了验证使用 Journey Learning 数据训练的模型在鉴别诊断中的有效性,团队进行了一项初步研究:团队移除了多项选择题的选项,并让模型自由地进行回答。
为确保公平,团队选择了 2024 年 JAMA Clinical Challenges 中发表的案例,而训练数据则收集于 2023 年 10 月之前。尽管训练数据包括了多项选择题选项的提供,但实验结果表明,使用长形式推理的模型更倾向于分析更广泛的潜在疾病,并整合多种背景信息和知识,从而得出更为精确的结论。这些发现为未来的研究方向提供了有价值的启示。



通过团队对推理时扩展(inference-time scaling)在医学领域应用的初步探索,研究团队发现这一方法在处理复杂推理任务时表现出巨大的潜力。
本研究展示了推理时扩展(inference-time scaling)显著提升了模型在诸如 MedQA、Medbullets 和 JAMA 临床挑战等基准测试中的表现。在仅用 500 个训练样本的情况下,模型准确率提升达 6% 至 11%。
研究团队希望:通过持续探索和迭代改进,提高推理时扩展在解决实际医学问题中的可解释性和有效性;通过专注于协作研究和开放资源共享,加强计算机技术与实际医学应用之间的联系,最终改善诊断准确性、患者治疗结果和医疗效率。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










