

 新火种 2023-09-07
新火种 2023-09-07 
讯飞输入法10.0发布语音识别引擎大幅升级
近日,讯飞输入法迎来十周年,拥有诸多黑科技的10.0版本也正式亮相,都说“5年一小,10年一大”,对于讯飞输入法来说又何尝不是。讯飞输入法10.0版本重点更新了A.I.语音引擎,使得讯飞输入法通用语音识别准确率在98%的基础上获得进一步提升,保持识别效果业界第一,用户体验最佳。作为讯飞输入法的十周年之作,10.0版本背后有哪些黑科技?
首先,最新发布的10.0版本搭载了科大讯飞最新A.I.技术——动态自适应编解码语音识别引擎(DomainSoft FusionEncoder-Decoder)。作为技术驱动型产品,顶天的技术是做好产品体验的根基。语音识别技术相当于给机器安装了“耳朵”,技术实力越强,机器听得越清晰越准确,给予人的帮助越大。
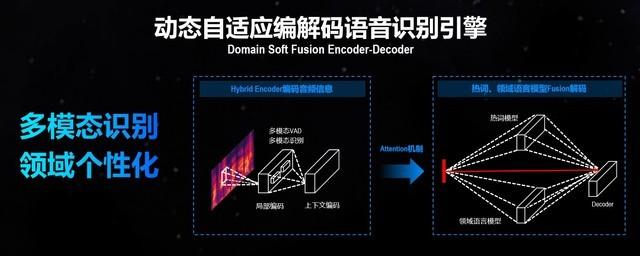
这一全新的A.I.语音输入引擎向着多模态识别、领域个性化方向发展。科大讯飞关注到,听力和视觉是人类捕捉外部信息最关键的器官,同理语音识别和图像识别对机器而言也相当重要,并且这两项技术在进化中处于核心地位。得益于深度学习的发展,讯飞快速完成语音识别到计算机图像识别之间的算法框架迁移和借鉴,在语音识别上取得长足进步。在新技术的应用下,讯飞输入法10.0新增唇形辅助输入,利用视频辅助语音识别,从而得到更好的输入效果,提高嘈杂环境及近距离多人说话的识别效果;另一方面大幅优化领域词识别,输入法会帮你更精准的匹配游戏、医疗、旅游、购物等不同的场景词汇。
比如说手机购物,要输入商品名称,有了讯飞输入法购物领域的模型和没有的识别结果是不一样的。在模型的辅助下,输入结果会根据模型做特殊的优化,以提高识别的准确率。
正如科大讯飞副总裁章继东说的那样,“很多的技术是看不见的,但是我们相信相应技术会改变世界。”创立10年以来,讯飞输入法秉持着技术顶天,引领语音交互落地的理念,不断革新产品,努力让让亿万用户高效输入,乐享沟通。
2010年,将GMM-hmm-隐马尔可夫模型应用到语音识别系统中:运用WFST解码器,提高复杂的语言模型,识别率达到70%;
2011年,运用BN(bottomneck)识别模型,通过神经网络提取音素特征,提升识别准确率;
2012年,全球首个中文语音识别DNN系统上线,识别率相对提升35%,准确率提升至80%;
2013年,运用SDT-DNN和基于DNN的VAD模型、深度学习离线版本,语音识别准确率提升至85%,实现离线语音识别;
2014年,运用UB-LSTM,语音识别率提高至95%。
2015年,运用无监督的speakcode技术,实现了声学个性化识别。因为除了语言模型之外,还有声学模型,即每个人的声音特征不一样,可以基于我们每个人的声音个性化来进行分辨的技术,实现实际效率的提升。
2016年,将DFCNN应用于语音识别,语音识别准确率达97%,离线、噪声、远场识别率显著提升。
2017年,运用Cachebased Fast Adaptation技术,创新融合个性化语音和语音模型,实现智适应语音识别;
2018年,运用HybridCNN算法,通过结构优化大幅提升并发路数,语音识别准确率突破98%;
2019年,基于注意力机制的Encode-Deconde模型应用,实现中英文免切换语音识别;
2020年,全新A.I.输入引擎再实现自我突破,搭载动态自适应编解码语音识别引擎,实现多模态输入和领域个性化识别,涵盖更多使用场景。
2020年5月,国际多通道语音分离和识别大赛(CHiME)组委会在线揭晓最新一届CHiME-6成绩:科大讯飞联合中科大语音及语言信息处理国家工程实验室(USTC-NELSLIP)在给定说话人边界的多通道语音识别两个参赛任务上夺冠。值得一提的是,科大讯飞也包揽了之前CHiME-5的全部冠军、CHiME-4的三项冠军。当我们看到夺冠这个现象的时候,其实背后就是科大讯飞强大的AI实力在起作用。
回顾这十年的发展历程,讯飞输入法实现把“中文语音技术做到全球最好”的小目标。下一个十年,随着5G和AIoT时代的到来,讯飞输入法将继续以过硬的技术实力直面行业发展的挑战与机遇,不断提高语音输入的行业天花板,为用户带来高效率的输入体验。
(7550700)
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









