


北大提出首个通用指令导航大模型系统|CoRL24
想象一下当你躺在沙发上,只需要不假思索地说出指令,机器人就能帮你干活,是不是听起来就十分惬意?如今这种科幻电影中的场景正在变为现实,来自北京大学的助理教授、博士生导师董豪团队近日提出首个通用指令导航大模型系统InstructNav。不论是寻找物体,走到指定位置,还是满足抽象的人类需求,只要你说出指令
想象一下当你躺在沙发上,只需要不假思索地说出指令,机器人就能帮你干活,是不是听起来就十分惬意?如今这种科幻电影中的场景正在变为现实,来自北京大学的助理教授、博士生导师董豪团队近日提出首个通用指令导航大模型系统InstructNav。不论是寻找物体,走到指定位置,还是满足抽象的人类需求,只要你说出指令

北京大学董豪团队具身导航最新成果来了:无需额外建图和训练,只需说出导航指令,如:我们就能控制机器人灵活移动。在此,机器人靠的是主动与大模型构成的“专家团队”沟通完成指令分析、视觉感知、完成估计和决策测试等一系列视觉语言导航关键任务。目前项目主页和论文都已上线,代码即将推出:机器人如何根据人类指令导航
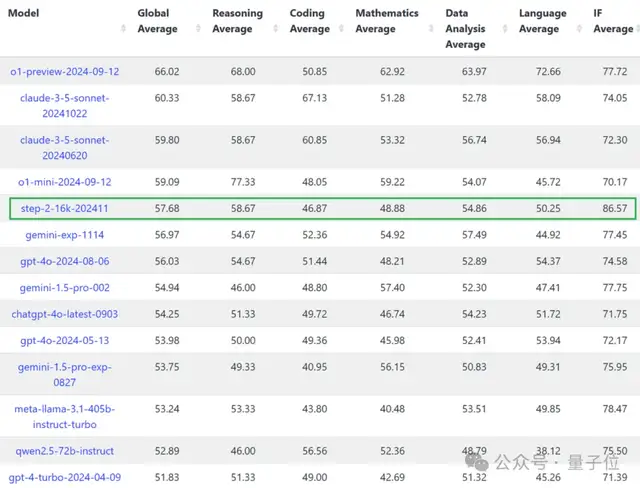
What???一直低调行事的国内初创公司,旗下模型悄悄地跃升成国内第一、世界第五(仅排在o1系列和Claude 3.5之后)!而且是前十名中的唯一一家国产公司。(该榜上国产第二名是阿里开源的qwen2.5-72b-instruct,总榜第13)。而且它登上的这个排行榜LiveBench,虽然现在还没

要点:1. 北大研究团队开发了一种具身导航系统,使机器人可以根据口头指令在室内环境中移动,无需额外训练或建图。2. 这一系统涉及多个关键任务,包括指令分析、视觉感知、完成估计和决策测试,由大模型专家团队协同完成。3. DiscussNav系统通过与大模型专家互动,使机器人能够根据人类指令移动,解决了

OpenAI全量开放GPT-4o图像生成能力,这回免费用户第一时间上车!一夜之间,各种实测结果刷屏。最惊艳的莫过于对文本的处理能力。比如,4o可以100%还原文字内容,且指定文字摆放位置。还能像连续剧一样,一边准确生成文字,一边变换人物动作。
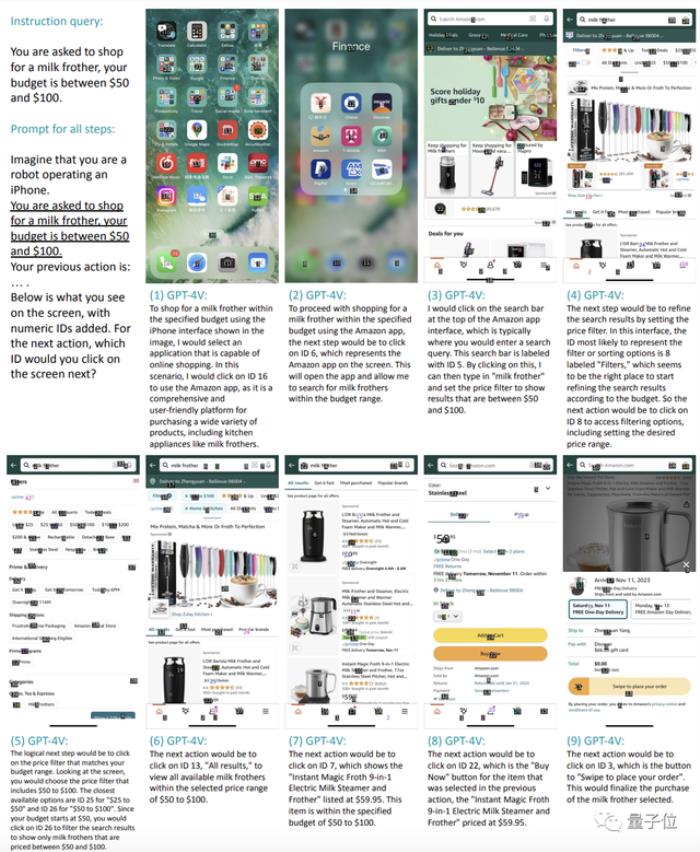
一项研究发现:无需任何训练,GPT-4V就能直接像人类一样与智能手机进行交互,完成各种指定命令。比如让它在50-100美元的预算内购买一个打奶泡的工具。它就能像下面这样一步一步地完成选择购物程序(亚马逊)并打开、点击搜索栏输入“奶泡器”、找到筛选功能选择预算区间、

一项研究发现:无需任何训练,GPT-4V就能直接像人类一样与智能手机进行交互,完成各种指定命令。比如让它在50-100美元的预算内购买一个打奶泡的工具。它就能像下面这样一步一步地完成选择购物程序(亚马逊)并打开、点击搜索栏输入“奶泡器”、找到筛选功能选择预算区间、

只靠一张物体图片,大语言模型就能控制机械臂完成各种日常物体操作吗?北大最新具身大模型研究成果ManipLLM将这一愿景变成了现实:在提示词的引导下,大语言模型在物体图像上直接预测机械臂的操作点和方向。

OpenAI CEO山姆·奥特曼展望GPT的未来版本,表示日后人们将能用所有人都能懂的自然语言对它下指令,这将是未来人们与电脑打交道的方式。

“即梦”作为一个全新的品牌,其核心功能包括图片生成、智能画布和视频生成,旨在为用户提供更为便捷、智能的创作体验。










