

NeurIPS2024|SparseLLM:突破性全局剪枝技术,大语言模型稀疏化革命
随着大型语言模型(LLMs)如 GPT 和 LLaMA 在自然语言处理领域的突破,现如今的模型能够在各种复杂的语言任务中表现优异。然而,这些模型往往包含数十亿参数,导致计算资源的需求极为庞大。为了让LLMs在更多的实际应用中变得可行,研究人员进行了大量的模型压缩工作,其中包括剪枝、量化、知识蒸馏和低秩分解等方法。
随着大型语言模型(LLMs)如 GPT 和 LLaMA 在自然语言处理领域的突破,现如今的模型能够在各种复杂的语言任务中表现优异。然而,这些模型往往包含数十亿参数,导致计算资源的需求极为庞大。为了让LLMs在更多的实际应用中变得可行,研究人员进行了大量的模型压缩工作,其中包括剪枝、量化、知识蒸馏和低秩分解等方法。

大型模型在许多任务上都产生了令人印象深刻的结果,但是训练和微调的成本很高,而且解码速度过慢,以至于研究和使用难度提升。华沙大学,谷歌研究和OpenAI的学者们通过利用稀疏性来解决这个问题。他们研究了模型中所有层级的稀疏变量,并提出了下一代Transformer模型族-Scaling Transfor
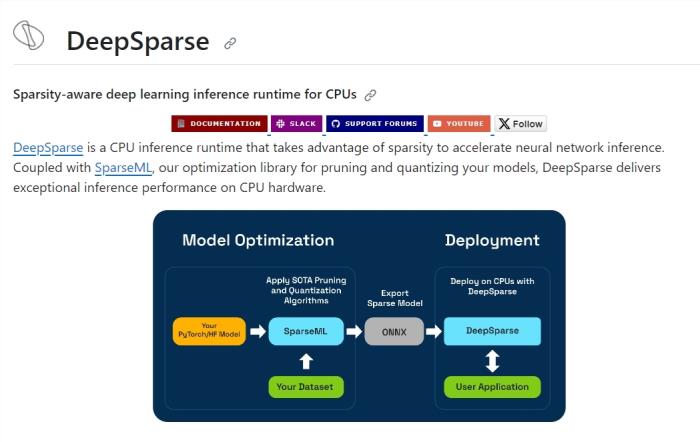
站长之家10月26日 消息:DeepSparse是一种突破性的CPU推理运行时,采用了复杂的稀疏性技术,从而实现了神经网络推理的加速。稀疏性是指神经网络中存在许多连接权重为零的情况。DeepSparse充分利用了这些零权重的连接,以跳过不必要的计算,从而有效地提高了推理速度。作为一个开源项目,Dee

2023 年 7 月,清华大学计算机系 PACMAN 实验室发布稀疏大模型训练系统 SmartMoE,支持用户一键实现 MoE 模型分布式训练,通过自动搜索复杂并行策略,达到开源 MoE 训练系统领先性能。同时,PACMAN 实验室在国际顶级系统会议 USENIX ATC’23 发表长文,作者包括博

2024年6月3日,昆仑万维宣布开源 2 千亿稀疏大模型 Skywork-MoE , 性能强劲, 同时推理成本更低。Skywork-MoE 基于之前昆仑万维开源的 Skywork-13B 模型中间 checkpoint 扩展而来,是首个完整将 MoE Upcycling 技术应用并落地的开源千亿 M

随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。注意力机制会计算一定跨度内输入文本(令牌,Token)之间的交互,从而实现对上下文的理解。随着应用的发展,高效处理更长输入的需求也随之增长 [1][2],这带来了计算代价的挑










