


大模型混入0.001%假数据就「中毒」,成本仅5美元!NYU新研究登Nature子刊
文章转载于新智元LLM训练的一个核心原则,通常表达为「垃圾输入,垃圾输出」,指出低质量的训练数据会导致模型产生同样低劣的输出。由于LLM通常使用互联网上大规模爬取的文本作为训练材料,难以被筛选的有害内容就会成为一个持久的漏洞。对于医疗相关的大模型,数据污染尤其令人担忧,因为应用领域的特殊性,错误输出
文章转载于新智元LLM训练的一个核心原则,通常表达为「垃圾输入,垃圾输出」,指出低质量的训练数据会导致模型产生同样低劣的输出。由于LLM通常使用互联网上大规模爬取的文本作为训练材料,难以被筛选的有害内容就会成为一个持久的漏洞。对于医疗相关的大模型,数据污染尤其令人担忧,因为应用领域的特殊性,错误输出
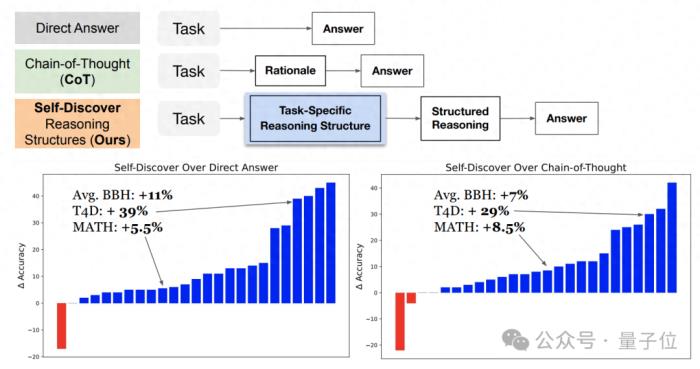
谷歌&南加大推出最新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。

《科创板日报》1月5日讯(编辑 宋子乔) 大秀了一把厨艺后,斯坦福华人团队开发的机器人又在北京时间今日凌晨发布了新视频《Mobile ALOHA的一天》,展示了浇花、打扫房间、煮咖啡、给主人刮胡子、洗碗、逗猫、扔垃圾、洗衣服、换被套、收纳衣物等数十种家务技能,堪称“全能家政员”。网友热评,“最难得的

从竞争打响,再到决出胜负,最快需要多长时间? 在科技圈,大模型如论第二,则很少有行业敢称第一。2023年,业界刮起一股“百模大战”风潮,百余个大模型面世,期待赢得下一个人工智能时代的入场券。但时间仅过半年有余,这场万众瞩目的角逐便走至了“决赛圈”。 目前,行业中的大模型用户体验已逐渐出现“分
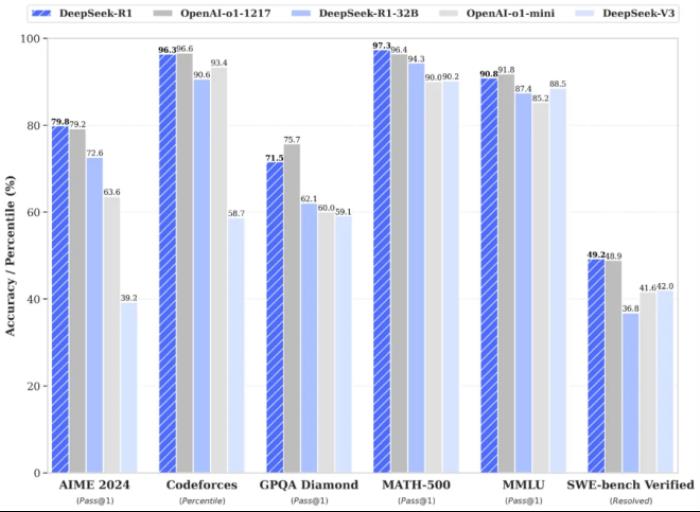
“Meta的生成式AI部门正处于恐慌中。这一切始于 Deepseek,它使得 Llama 4 在基准测试中已经落后。雪上加霜的是:那个不知名的中国公司,仅有 550 万美元的训练预算。工程师们正在疯狂地剖析 Deepseek,并试图从中复制一切可能的东西……”一位Meta的工程师在美国科技公司员工社

【明日主题前瞻】马斯克称机器人Optimus最终制造成本将低于汽车

新消费日报 | Stellantis与零跑汽车宣布即将启动马来西亚本地化组装项目;直播电商监管新规将公开征求意见;爱马仕将向美国客户转嫁关税成本……

16日讯,百度创始人、董事长兼首席执行官李彦宏在Create 2024百度AI开发者大会上正式发布文心大模型4.0的工具版。李彦宏表示,相比一年前,文心大模型的算法训练效率提升到了原来的5.1倍,周均训练有效率达到98.8%,推理性能提升了105倍,推理的成本降到了原来的1%。

百度Apollo与极狐汽车6月17日在北京举行发布会,共同发布了新一代共享无人车Apollo Moon,双方同时还签署了未来3年落地1000台共享无人车的协议。虽然定价并未公布,但两家公司表示,新车的整体成本约48万元。

在CES 2025主题演讲中,英伟达大秀了一系列AI新品。 CES是消费电子主场,此次英伟达也是以消费级显卡GeForce RTX 50系列打头阵,同时公布了巨型芯片Grace Blackwell NVLink72、小型超级计算机Project DIGITS、世界基础模型平台Cosmos等。










