新火种
2024-02-21
新火种
2024-02-21 


GPT-4推理能力暴涨32%,谷歌新型思维链效果超CoT,成本降至1/40
GPT-4推理能力还能暴涨32%?
谷歌&南加大推出最新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。
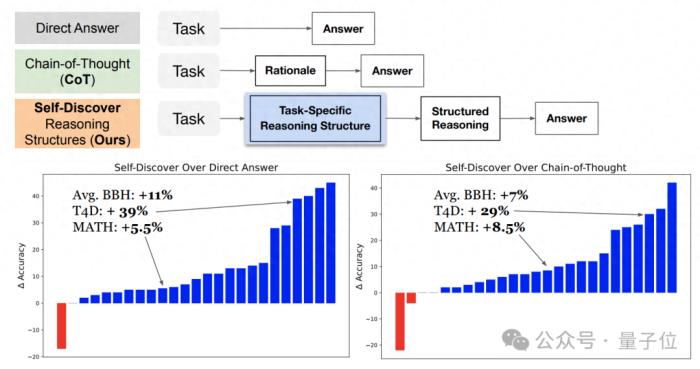
与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。
核心策略其实很简单:千人千面。
让大模型针对不同问题,提出特定的推理结构。完全不同于以往CoT等方法“千篇一律”的方式。

这种灵活应变的方式,更加贴近于人类的思考模式,也向着期待中的大模型思维方式更进一步。

大模型“千人千面”
一直以来大模型在处理复杂问题时都容易遇到困难,所以一些模拟人类思维能力的提示方法被提出。
最出名的就是思维链(CoT),它通过引导大模型“一步一步来”,让大模型能像人类一样逐步思考解决问题,最终带来显著性能提升。
还有分解法(decomposition-based prompting),它是让大模型将复杂问题拆解成一个个更小的子问题。
这类方法本身都能充当一个原子推理模块,对给定任务的处理过程做了先验假设,也就是让不同问题都套到同一个流程里解决。
但是不同方法其实都有更擅长和不擅长的领域。比如在解决涉及符号操作等问题时,分解法要优于CoT。
所以研究人员提出,对于每个任务,都应该有独特的内在推理过程,同时还不提高模型的推理成本。

自发现步骤架构由此而来。
它主要分为两个阶段。
第一阶段指导大语言模型从原子推理模块中进行挑选、调整、整合,搭建出一个可以解决特定任务的推理结构。
比如“创造思维”可能在创作故事任务上有帮助、“反思思考”可能对搜索科学问题有帮助等。大模型需要根据任务进行挑选,然后进一步调整并完成整合。
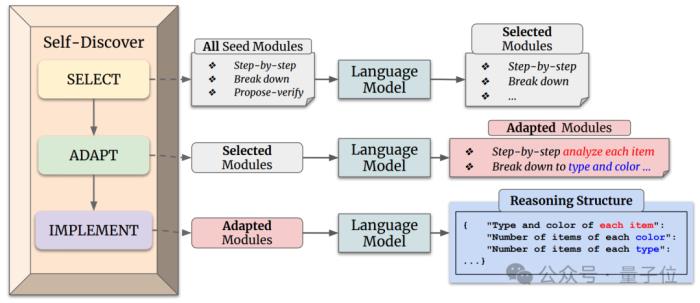
第二阶段输入实例,让大模型使用第一阶段发现的推理结构来生成答案。
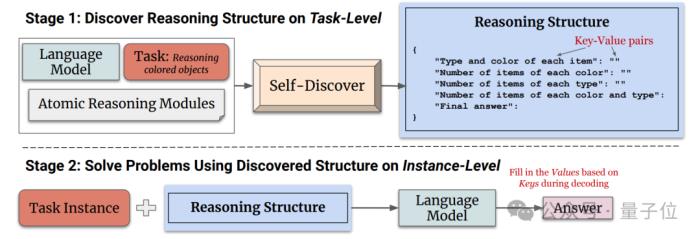
通过在GPT-4和PaLM 2上进行实验,在BBH、T4D、MATH几个基准中,使用自发现步骤架构后,模型的性能都有明显提升。
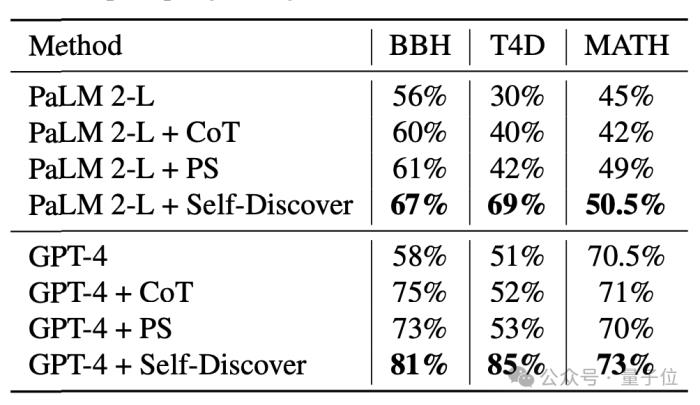
在更细分的测试中,自发现步骤在需要世界知识的任务中表现最好,在算法、自然语言理解上超过CoT。
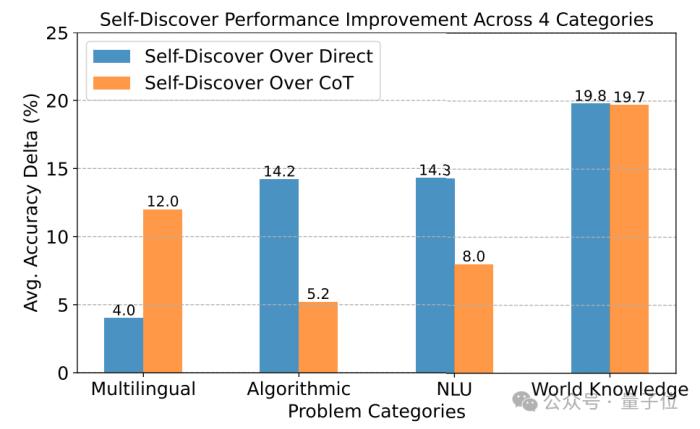
在处理问题的推理调用方面,自发现步骤需要的调用次数明显少于CoT+Self Consistency,而且准确性更高。
如果想要达到和自发现步骤同样的准确率,需要的推理计算量则是其40倍。
研究团队
本项研究由南加州大学和谷歌DeepMind联合推出。
第一作者是Pei Zhou,他现在正在南加州大学的NLP小组攻读博士。
两位通讯作者分别是Huaixiu Zheng和Swaroop Mishra。
Huaixiu Zheng此前参与过谷歌LaMDA工作,这是谷歌一个专攻对话的大模型。
Swaroop Mishra是谷歌DeepMind的研究科学家,它参与的Self-Instruct框架在GitHub上星标3.5k、被引用次数超过600,并被ACL 2023接收。
此外Quoc Le、Denny Zhou等大模型提示微调、推理方向的老面孔也参与其中。
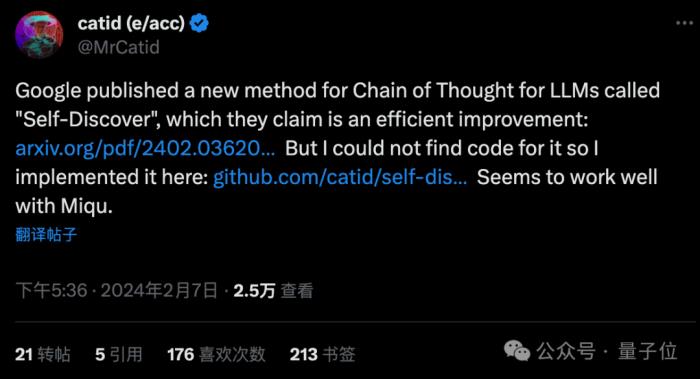
虽然官方暂未开源,但已经有迫不及待的开发者根据论文自行复现了代码。
发现不仅适用于GPT-4和谷歌PaLM,连Mistral家泄露版模型Miqu上都能很好发挥作用。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章