新火种
2024-12-03
新火种
2024-12-03 


微软:两个AI相互纠错,数学再涨5分
奇月 发自 凹非寺新火种 | 公众号 QbitAI
提升LLM数学能力的新方法来了——
一个大模型不行,那就两个。让他们彼此合作,纠正对方的错误。
这就是来自加州大学和微软研究院的最新研究成果:Flow-DPO。通过使用在线学习流(Flow)和直接偏好优化(DPO, Direct Preference Optimization),可以让LLM生成更加详细和精确的推理轨迹。
同时,这种在线多智能体(Agent)的学习形式还能挖掘数据中的深层信息,有效避免了人类标注数据不够准确的问题。

我们先一起看个例子感受一下。
比如针对下面这道题:
基准回答是这样的:
而Flow-DPO的回答是这样的:
让GTP-4o当裁判,针对两个模型的回答分析了一下,它认为答案B(FLow-DPO)更好,原因有两点:
1.概念解释
答案 A 的回答是:“我们可以利用斜率之间的负倒数关系来求解 a”。答案 B 花时间明确解释了垂直的概念,强调垂直线的斜率是负倒数。这种回答更有教育意义,可以让读者理解数学背后的推理。
2.解题思路清晰
答案A推导出了正确的方程并正确地求解了方程,但引入了一些不必要的步骤。
例如,中间步骤涉及将方程改写为2y = -ax – 3 和两边除以 2 的中间步骤比必要的步骤复杂。
答案 B 立即使用两个方程的斜截距形式简化了方法。它有效地解释了如何提取斜率,并直接比较了两个等式的斜率,过程更直接,更容易理解。
结论
答案 B 的解释更清晰、更透彻,既注重概念和公式,又避免了不必要的复杂性,这种循序渐进的方法更易于理解和掌握。

可以看到,在解决真实数学问题的时候,Flow-DPO生成的推理过程不仅有更详细的指导,还避免了不必要的复杂性,增强了可读性和理解性。
这是怎么做到的呢?
两个大模型彼此合作针对LLM解决数学问题时反馈信息有限、标注数据质量不高等问题,团队提出了一种新的方法。
那就是通过在线学习流(Flow)和直接偏好优化(DPO)学习来生成高质量的推理轨迹。
具体分为2个部分:
1.增量输出生成Flow(Incremental Output Production Flow)
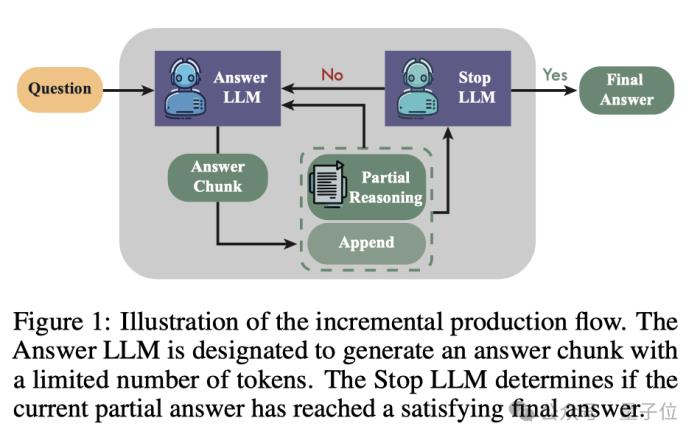
Flow-DPO采用了增量输出生成Flow,其中有两个独立的LLM(Answer LLM和Stop LLM)协同工作,通过迭代通信构建解决方案。
具体来说,Answer LLM一次会生成一个有限的答案块,而Stop LLM则判断部分答案是否达到最终状态,两个LLM通过迭代式学习不断进步。
Answer LLM和Stop LLM的底层都是相同的基础模型,但它们使用不同的LoRA适配器进行了微调,可以专门完成各自的任务。
而且在训练过程中,Flow-DPO可实现更精细的控制较小的块大小,灵活适应不同的概念和方法,较大的块大小近似于单次模型生成。
2.在线Flow学习与回滚(Online Flow Learning with Rollouts)
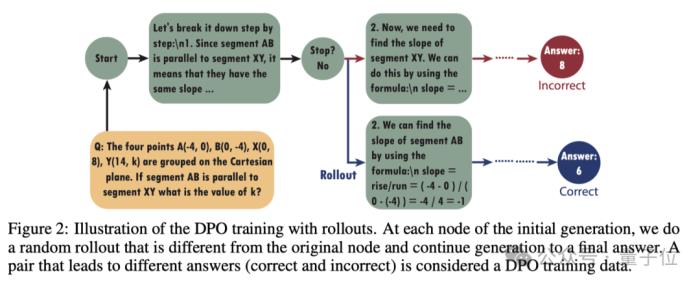
Flow-DPO还会通过在线DPO学习和回滚来增强Flow。
对于每个输入问题,Answer LLM会生成一个答案片段,一直持续到产生完整的回答。
然后模型会在每个输出节点进行随机展开,比如在生成初始答案片段且Stop LLM判断为“否”后,Flow还会生成另一个答案片段,基于之前的部分答案继续构建。
如果两个答案在正确性上不同,就把它们作为答案语言模型的DPO对,引导到正确答案的那个片段被选为首选响应。
为了验证Flow-DPO的性能,研究团队还设计了精密的验证实验,具体设置如下
数据集:实验使用了MetaMath数据集,该数据集基于于GSM8K和MATH数据集,并通过数据增强技术进行了增强。模型选择:实验采用了两种不同规模的模型:Llama-3-8B-Instruct和Phi-3-medium-128k-instruct (14B)Flow学习阶段:在Flow学习阶段,团队使用不同的LoRA适配器对Answer LLM和Stop LLM进行微调,让它们在DPO训练中的能力更加专业。编译阶段:在编译阶段,收集Flow生成的正确推理轨迹和基线模型生成的正确推理轨迹,进行独立评估。最终结果显示,使用了Flow-DPO之后,Llama3模型和Phi3在数学推理上的能力都大幅提升了!
一起来看看具体结果分析:
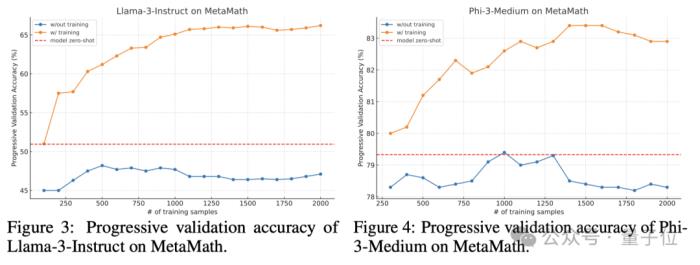
1.渐进验证准确率(Progressive Validation Accuracy)
渐进验证准确率的准确定义,是模型在训练前对输入训练数据的累积准确度,公式和变量含义如下图所示:
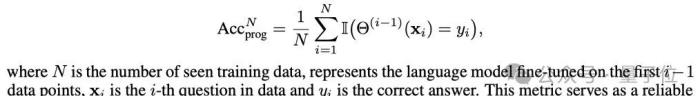
实验结果显示,在线DPO训练显著提高了Flow的泛化能力。
对于Llama-3-8B-Instruc模型,在线DPO学习在仅2000个训练实例内将Flow的性能提高了20%。对于Phi-3-medium-128k-instruct模型,在线DPO学习使其准确率提高了4个百分点,达到了83%.
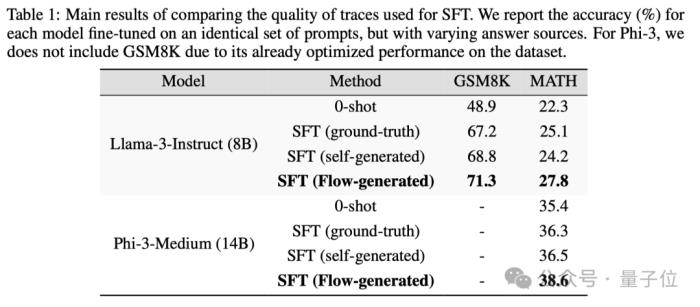
2.推理轨迹质量
Flow生成的推理轨迹在质量上也优于基线和模型生成的正确推理轨迹。
对于Llama-3-8B-Instruct模型,Flow生成的推理轨迹在GSM8K和MATH数据集上的微调准确率分别提高了6%和7.8%。
对于Phi-3-medium-128k-instruct模型,Flow生成的推理轨迹在两个数据集上的微调准确率分别提高了1.9%和2.1%.
除了刚开始的垂直直线问题,研究团队还放出了很多真实的解题回答和对比,感兴趣的朋友可以查看论文的更多相关信息。

没想到,不久前还让LLM非常头疼的数学问题现在也进步飞快!
有了优秀的逻辑分析能力,我们也能期待LLM未来能解决更多复杂的问题了。

参考链接:[1]https://arxiv.org/abs/2410.22304
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章