新火种
2024-11-24
新火种
2024-11-24 

英伟达开源福利:视频生成、机器人都能用的SOTAtokenizer
tokenizer对于图像、视频生成的重要性值得重视。
在讨论图像、视频生成模型时,人们的焦点更多地集中在模型所采用的架构,比如大名鼎鼎的 DiT。但其实,tokenizer 也是非常重要的组件。谷歌等机构的研究者曾在一篇题为「Language model Beats diffusion - tokenizer is key to visual generation」的论文中证明,一个好的 tokenizer 接入到语言模型后,能够立即获得比当时最好的 diffusion 模型还要好的效果。论文作者蒋路在后来接受采访时表示,「我们的研究可能会让社区意识到 tokenizer 是被严重忽视的一个领域,值得发力去做」。在图像、视频生成模型中,tokenizer 的核心作用是将连续的、高维的视觉数据(如图像和视频帧)转换成模型可以处理的形式,即紧凑的语义 token,它的视觉表示能力对于模型的训练和生成过程至关重要。就像上述论文作者所说,「tokenizer 的存在就是通过建立 token 之间的互联,让模型明确『我现在要做什么』,互联建立得越好、LLM 模型越有机会发挥它的全部潜力。」
tokenizer 是生成式 AI 的关键组件,它通过无监督学习发现潜在空间,从而将原始数据转换为高效的压缩表示。视觉 tokenizer 专门将图像和视频等高维视觉数据转化为紧凑的语义 token,从而实现高效的大型模型训练,并降低推理的计算需求。图中展示了一个视频 token 化过程。当前,业界有很多可用的开源视频、图像 tokenizer,但这些 tokenizer 经常生成质量不佳的数据表示,这会造成采用该 tokenizer 的模型生成失真的图像、不稳定的视频。此外,低效的 token 化过程还会导致编解码速度变慢、训练和推理时间变长,从而对开发人员的工作效率和用户体验产生负面影响。为了解决这些问题,来自英伟达的研究者开源了一套名为 Cosmos 的全新 tokenizer。

研究地址:https://research.nvidia.com/labs/dir/cosmos-tokenizer/HuggingFace 地址:https://huggingface.co/collections/nvidia/cosmos-tokenizer-672b93023add81b66a8ff8e6一般来说,tokenizer 有两种类型:连续型和离散型。连续 tokenizer 将视觉数据映射为连续嵌入,适用于从连续分布中采样的模型,如 Stable Diffusion。离散 tokenizer 将视觉数据映射为量化指数,适用于 VideoPoet 等依赖交叉熵损失进行训练的模型,类似于 GPT 模型。下图比较了这些 token 类型。

tokenizer 必须兼顾高压缩和高质量,保留潜在空间的视觉细节。Cosmos tokenizer 是一套全面的连续和离散图像和视频视觉 tokenizer,可提供出色的压缩和高质量重建,速度是以前方法的 12 倍。
如表 1 所示,它支持各种图像和视频类型,具有灵活的压缩率,以适应不同的计算限制。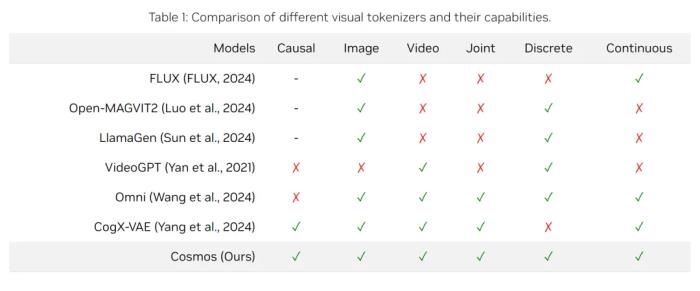
Cosmos tokenizer 基于轻量级时间因果架构,使用因果时间卷积和注意力层来保持视频帧的顺序。这种统一的设计允许对图像和视频进行无缝 token 化。英伟达的研究者在高分辨率图像和长视频上训练 Cosmos tokenizer,涵盖不同类别数据的宽高比(包括 1:1、3:4、4:3、9:16 和 16:9)。在推理过程中,它不受时间长度的影响,可以处理比训练时间更长的数据。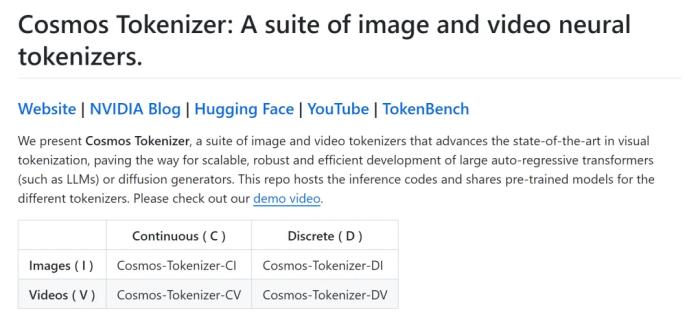
GitHub 地址:https://github.com/NVIDIA/Cosmos-Tokenizer研究者在标准数据集(包括 MS-COCO 2017、ImageNet-1K、FFHQ、CelebA-HQ 和 DAVIS)上对 Cosmos tokenizer 进行了评估。为了使视频 tokenizer 评估标准化,他们还策划了一个名为 TokenBench 的新数据集,涵盖机器人、驾驶和体育等类别,并在 GitHub 上公开发布。
TokenBench 地址:https://github.com/NVlabs/TokenBench结果(图 1)显示,Cosmos tokenizer 明显优于现有方法,在 DAVIS 视频上的 PSNR 提升了 4 dB。它的 token 化速度是以前方法的 12 倍,并能在配备 80GB 内存的英伟达 A100 GPU 上编码长达 8 秒的 1080p 和 10 秒的 720p 视频。空间压缩率为 8 倍和 16 倍、时间压缩率为 4 倍和 8 倍的预训练模型可在 GitHub 上获取。
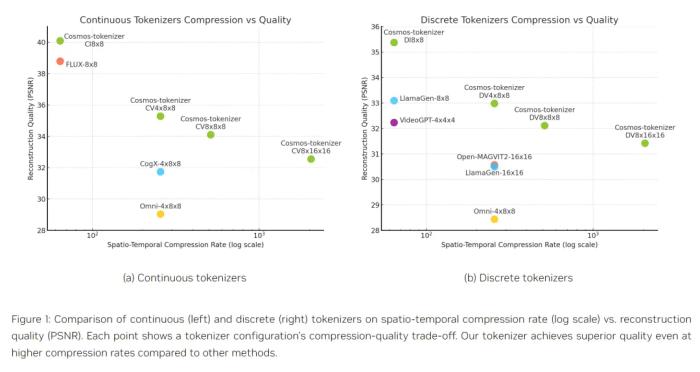
试用过 Cosmos 的 1x 机器人公司 AI 副总裁 Eric Jang 表示,Cosmos 是一个非常好的 tokenizer,比根据他们自己的数据进行微调的 Magvit2 好得多。看来,这个新工具值得一试。
以下是 Cosmos 的一些技术细节。Cosmos tokenizer 架构Cosmos tokenizer 采用复杂的编码器 - 解码器结构,旨在实现高效率和高效学习。其核心是采用 3D 因果卷积块,这是联合处理时空信息的专门层,并利用因果时间注意力捕捉数据中的长程依赖关系。因果结构确保模型在进行 token 化时只使用过去和现在的帧,而避免使用未来帧。这对于与许多真实世界系统的因果性质保持一致至关重要,例如物理 AI 或多模态 LLM 中的系统。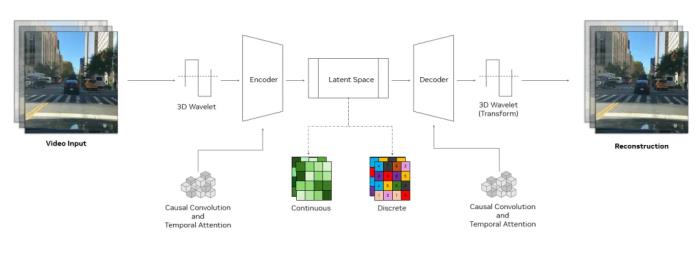
Cosmos tokenizer 架构图。使用 3D wavelet 对输入进行降采样,这种信号处理技术能更有效地表示像素信息。数据处理完成后,通过反向 wavelet 变换重建原始输入。这种方法提高了学习效率,使 tokenizer 编码器 - 解码器可学习模块专注于有意义的特征,而不是多余的像素细节。这些技术与其独特的训练方法相结合,使 Cosmos tokenizer 成为了一个高效、强大的架构。实验结果定性结果图 6 显示了使用连续视频 tokenizer 重建的视频帧。
图 9 显示了使用不同离散图像 tokenizer 重建的图像。
图 8 则显示了连续图像 tokenizer 的误差图,以突出重建差异。与之前的方法相比,Cosmos tokenizer 能更有效地保留结构和高频细节(如草地、树枝、文本),同时将视觉失真(如人脸、文本)和伪影降到最低。
这些定性结果表明,Cosmos tokenizer 能够编码和解码各种视觉内容,并有能力保持图像和视频的最高视觉质量。定量结果表 2 和表 3 列出了连续和离散视频 tokenizer 在各种基准上的平均定量指标。Cosmos tokenizer 在 4×8×8 压缩率的 DAVIS 和 TokenBench 数据集上都达到了 SOTA 性能。即使在更高的压缩率(8×8×8 和 8×16×16)下,Cosmos tokenizer 的性能也优于以前的方法,显示了出色的压缩质量权衡。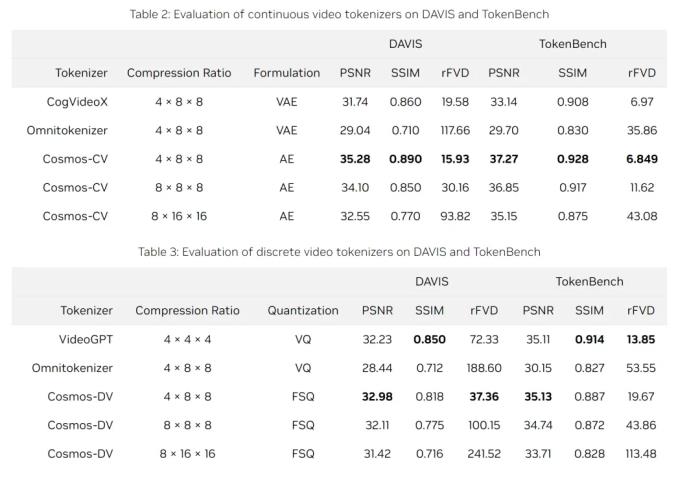
参考链接:https://developer.nvidia.com/blog/state-of-the-art-multimodal-generative-ai-model-development-with-nvidia-nemo/https://research.nvidia.com/labs/dir/cosmos-tokenizer/https://mp.weixin.qq.com/s/Hamz5XMT1tSZHKdPaCBTKg
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章