

 新火种
2024-11-21
新火种
2024-11-21 

九大成像模式一键解析,生物医学图像AI再迎突破!微软、UW等BiomedParse登Nature子刊
作者 |BiomedParse团队
编辑 | ScienceAI
生物医学图像解析在癌症诊断、免疫治疗和疾病进展监测中至关重要。然而,不同的成像模式(如MRI、CT和病理学)通常需要单独的模型,造成资源浪费和效率低下,未能充分利用模式间的共性知识。
微软团队最新发布的基础模型BiomedParse,开创性地通过文本驱动图像解析将九种成像模式整合于一个统一的模型中,通过联合预训练处理对象识别、检测与分割任务,实现了生物医学图像解析的新突破。
BiomedParse显著提升了复杂、不规则形状对象的识别精度,同时降低了用户交互的需求,为精准医疗和生物医学发现提供了更强大的工具。

论文链接:https://www.nature.com/articles/s41592-024-02499-w
BiomedParse:通过语言打破九种成像模式之间的壁垒
医学图像的成像模式差异巨大(如CT、MRI、病理切片、显微镜图像等),传统上需要训练专家模型进行处理。然而不同医学图像呈现的物体背后,实际上是共通的生物医学知识。
BiomedParse是第一个通过医学语言实现跨九种成像模式进行一致性分析的生物医学基础模型。
用户只需通过简单的临床语言提示指定目标对象,例如「肿瘤边界」或「免疫细胞」,BiomedParse便能准确识别、检测并分割图像中的相关区域。相比传统需要手动框定或标注对象边界的模型,
BiomedParse极大地减少了科学家和临床医生的工作量。无论是影像级别的器官扫描,还是细胞级别的显微镜图像,BiomedParse都可以直接利用临床术语进行跨模式操作,为用户提供了更统一、更智能的多模式图像解析方案。
这种跨模式的一体化方法,连接了放射学、病理学、显微镜学等多个领域,帮助研究人员从不同模式的数据中解析出有价值的信息,从而探索多尺度、跨学科的生物医学问题。BiomedParse的问世,标志着生物医学图像分析从单一模式走向了全局统一的新阶段。
核心亮点
BiomedParse在生物医学图像分析中解锁了多项创新功能:
跨模式一致性分析:BiomedParse首次实现了跨九种成像模式的稳定表现,取代了传统的单独工具,使研究人员能够更快速、便捷地分析大量数据集。文本驱动的图像解析:BiomedParse利用自然语言提示进行图像解析,将对象识别、检测和分割任务视为一体。无需耗时的手动标注或边界框操作,显著缩短了大规模图像分析的时间和精力。复杂结构的精准识别:在分割不规则形状的生物医学对象方面,BiomedParse相较传统模型表现卓越。通过将图像区域与临床概念关联,分割精度比之前最好方法提高了39.6%,确保了在关键任务中的可靠性。GPT-4驱动的大规模数据合成
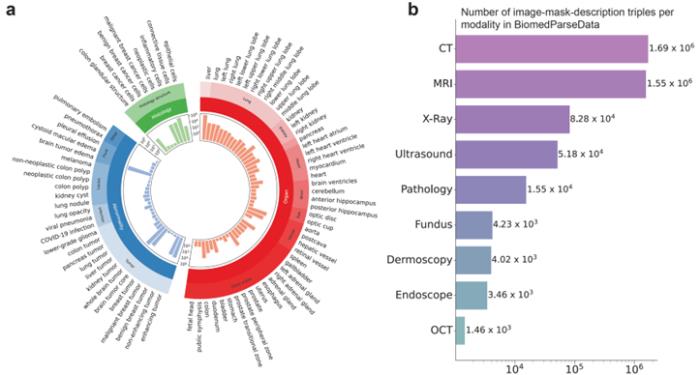
为支持BiomedParse的预训练,微软团队利用GPT-4从45个公开的医学图像分割数据集生成了首个覆盖对象识别、检测和分割任务的数据集BiomedParseData。
该数据集包含超过600万个图像、分割标注与文字描述三元组,涵盖64种主要生物医学对象类型及82个细分类别,涉及CT、MRI、病理切片等九种成像模式。通过GPT-4的自然语言生成能力,研究人员将散落在各种现有数据集中的分割任务用统一的医学概念和语言描述整合起来,让BiomedParse能在更大,更多样的数据中融会贯通。
实验评估:只需文字提示,BiomedParse精度超越SOTA
在测试集上,BiomedParse在Dice系数上显著超越了当前最优方法MedSAM和SAM,并且无需对每个对象手动提供边界框提示。即使在给MedSAM和SAM提供精准边界框的情况下,BiomedParse的纯文本提示分割性能仍能超越5-15个百分点。
此外,BiomedParse的性能还优于SEEM、SegVol、SAT、CellViT、Swin UNETR等多个模型,尤其在复杂不规则的对象识别上表现突出。
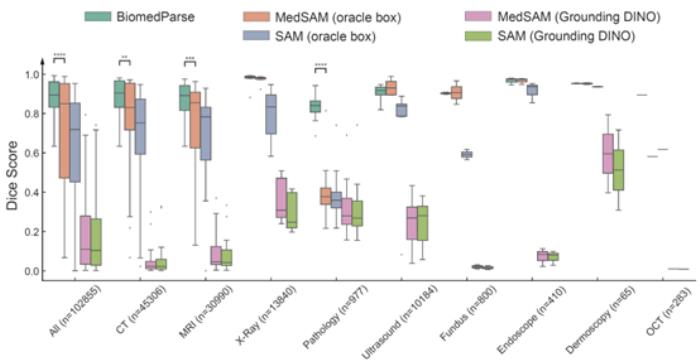
生物医学图像中的不规则对象一直是传统模型的难题,而BiomedParse通过联合对象识别和检测任务,通过文本理解实现了对对象特定形状的建模。对复杂对象的识别精度远超传统模型,且在多模态数据集中进一步凸显了其优势。
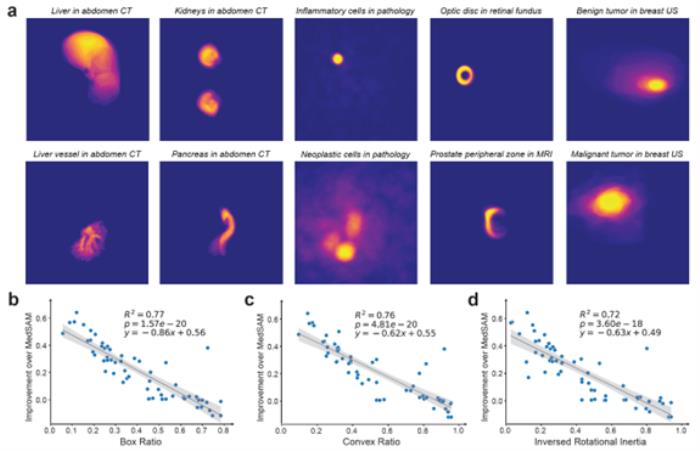
展望未来:多模态生物医学AI的基石
BiomedParse拓展了生物医学图像解析的可能性,将九种成像模式纳入一个统一、多用途的模型中。通过简单的文本提示,BiomedParse显著减少了用户的交互需求,尤其在包含大量对象的图像中,无需逐一标注对象的边界框。通过对象识别阈值建模,BiomedParse能够检测无效的提示请求,并在图像中不存在指定对象时拒绝分割。
BiomedParse可以一次性识别并分割图像中的所有已知对象,实现全局图像解析的扩展,未来有望应用于早期检测、预后评估、治疗决策支持和疾病进展监测等精准医疗关键应用场景。
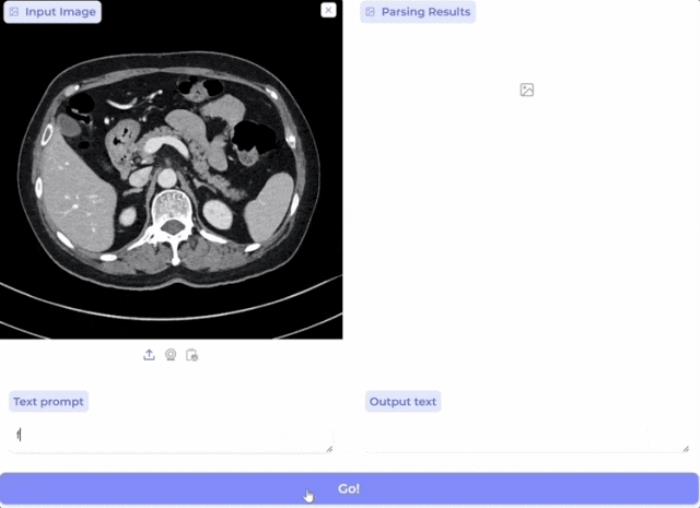
展望未来,BiomedParse拥有广阔的发展潜力,可进一步扩展至更多成像模式和对象类型,并与LLaVA-Med等高级多模态框架集成,支持「对话式」图像分析,实现数据交互式探索。
为促进生物医学图像分析研究,微软已将BiomedParse开源并提供Apache 2.0许可,相关演示demo 和 Azure API均已上线,以支持全球精准医疗和健康研究的进步。
微软布局医疗AI
近年来,微软在医疗人工智能(AI)领域积极布局,取得了多项重要成果。今年初,微软联合华盛顿大学和Providence医疗系统发布了首个全切片数字病理学模型GigaPath,该研究成果发表在《自然》正刊上。
近期,微软在其Azure AI平台上部署了多个多模态医疗AI模型,包括本文中提到的BiomedParse和专为放射学应用设计的生成式多模态AI模型LLaVA-Rad和MAIRA-2以及对比学习基础模型MedImageInsight。通过在Azure AI平台上部署这些先进的多模态医疗AI模型,微软旨在为医疗行业提供全新的工具,推动医疗服务的智能化发展。
作者简介
论文的五位共同一作及通讯作者均为华人,分别来自微软和华盛顿大学。
赵正德(TheodoreZhao),论文第一作者,为该研究作出主要技术贡献。微软高级应用科学家,现主要研究方向包括多模态医疗AI模型,图像分割与处理,大模型的安全性分析(Pareto最优误差估计)。本科毕业于复旦大学物理系,博士毕业于华盛顿大学应用数学系,期间研究希尔伯特-黄变换和分数布朗运动的多尺度特征,以及随机优化在医疗领域的应用。

顾禹(AidenGu),论文共同一作,微软高级应用科学家,致力于推动AI在医疗领域的发展。本科毕业于北京大学微电子与经济专业。其研究方向专注于医疗健康、生物医学,以及机器人多模态模型。代表性工作包括创建首个领域特定的大语言模型PubMedBERT,以及患者旅程模拟模型BiomedJourney。

潘海峰(HoifungPoon),论文通讯作者,微软研究院健康未来(Health Futures)General Manager,华盛顿大学(西雅图)计算机博士。研究方向为生成式AI基础研究以及精准医疗应用。在多个AI顶会获最佳论文奖(比如NAACL,EMNLP,UAI),在HuggingFace上发布的开源生物医学大模型总下载量达数千万次(比如PubMedBERT,BioGPT,BiomedCLIP,LLaVA-Med),在《自然》上发表首个全切片数字病理学模型 GigaPath(自五月底公布以来已被下载四十万次),部分研究成果开始在合作的医疗机构和制药公司中转化为应用。

王晟(ShengWang),论文通讯作者,华盛顿大学计算机科学与工程系助理教授,专注于人工智能与医学的交叉研究,利用生成式AI解决生物医学问题。他的科研成果已在《Nature》《Science》《Nature Biotechnology》《Nature Methods》和《The Lancet Oncology》等顶级期刊上发表十余篇论文,并被Mayo Clinic、Chan Zuckerberg Biohub、UW Medicine、Providence等多家知名医疗机构广泛应用。

Mu Wei,论文通讯作者,微软Health and Life Sciences团队首席应用科学家,拥有十余年医疗与金融领域的AI模型研发与部署经验。他的团队聚焦于健康领域的多模态AI模型,研究成果涵盖生物医学图像解析、数字病理学基础模型、临床文档结构化的大模型应用以及大模型错误率估计等方向。

论文地址:https://www.nature.com/articles/s41592-024-02499-w
项目展示网页:https://microsoft.github.io/BiomedParse/
GitHub:https://aka.ms/biomedparse-release
数据集:https://huggingface.co/datasets/microsoft/BiomedParseData
AzureAPI网页:Model catalog - Azure AI Studio
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










