新火种
2024-10-25
新火种
2024-10-25 


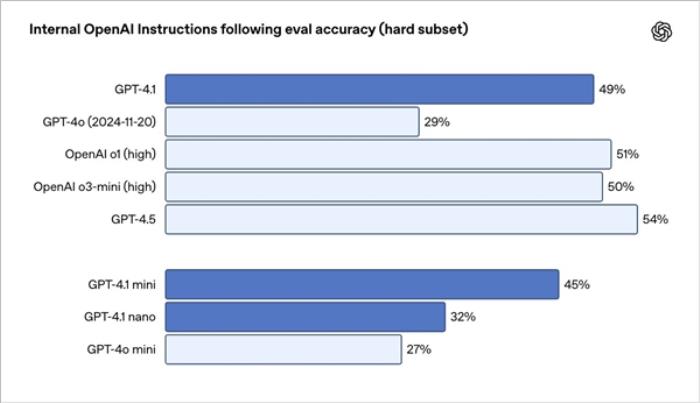
比扩散模型快50倍!OpenAI发布多模态模型实时生成进展,作者还是清华校友,把休假总裁Greg都炸出来了
两位清华校友,在OpenAI发布最新研究——
生成图像,但速度是扩散模型的50倍。
路橙、宋飏再次简化了一致性模型,仅用两步采样,就能使生成质量与扩散模型相媲美。

他们成功将连续时间一致性模型的训练规模扩展到了前所未有的15亿参数,并实现了在512×512分辨率的ImageNet数据集上的训练。
参数15亿模型在单张A100 GPU上无需任何推理优化即可在0.11秒内生成一个样本。

团队还表示通过定制系统优化,可以进一步加速,为实时生成图像、音频和视频提供新的可能。
值得一提的是,论文仅有的两位作者还都是清华校友。
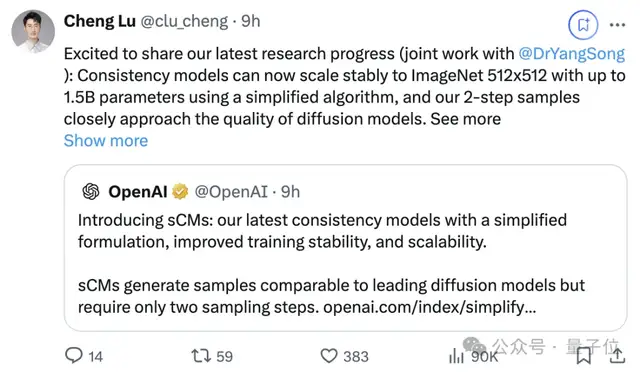
该项研究发布后得到大量网友点赞转发。
把正在休假的Openai总裁Greg Brockman都炸出来了:

那么,sCM是如何实现的?
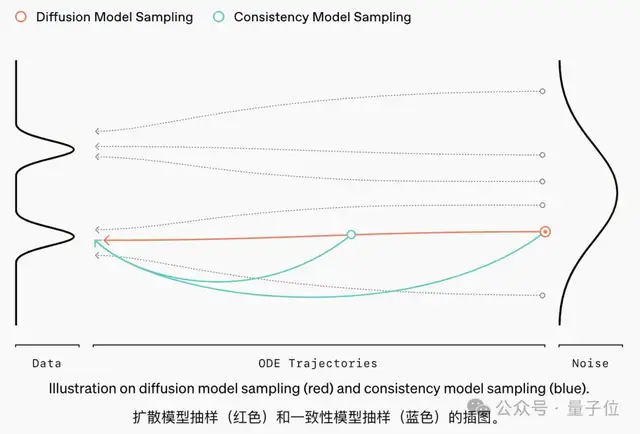
两步采样,50倍加速一致性模型是一种快速的扩散模型替代方案。
当前扩散模型的采样方法通常需要数十到数百个连续步骤才能生成单个样本,这限制了其实时应用的效率和可扩展性。
与逐步通过大量去噪步骤生成样本的扩散模型不同,它旨在一步直接将噪声转换为无噪声样本。
OpenAI最新这项研究提出了一种改进连续时间一致性模型(Continuous-time Consistency Models)的综合方法,主要包含题目中提到的三个关键点:简化、稳定和扩展。

论文指出,现有一致性模型主要采用离散时间步训练,这种方法会引入额外的超参数并容易产生离散化误差。尽管连续时间公式可以避免这些问题,但之前的工作中连续时间一致性模型始终面临训练不稳定的挑战。
为此,论文首先提出了TrigFlow,巧妙地统一了EDM(Exponential Diffusion Model)和Flow Matching两种方法。
TrigFlow使扩散过程、扩散模型参数化、PF-ODE、扩散训练目标和一致性模型参数化都能够拥有简洁的表达式,如下所示。


在此基础上,研究人员深入分析了导致训练连续时间一致性模型不稳定的原因。
在TrigFlow框架的基础上引入了几项理论上的改进,重点是参数化、网络架构和训练目标。
连续时间一致性模型训练的关键是:
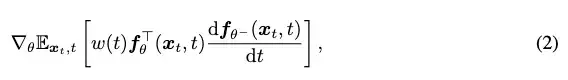
取决于:
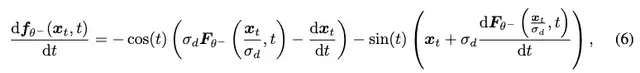
经过进一步分析,研究人员发现不稳定源自于时间导数:
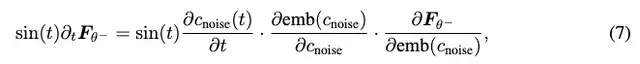
并据此提出了三个关键改进:
采用恒等时间变换c_noise(t)=t代替原有的对数正切变换,避免了t接近π/2时的数值不稳定性;使用位置时间嵌入替代傅里叶嵌入,减少了导数震荡;引入自适应双重归一化层替代AdaGN,在保持模型表达能力的同时提高了训练稳定性。此外,论文还改进了训练目标,包括切向量归一化和自适应权重等技术。
以上种种改进使得研究人员成功将时间一致性模型的训练规模扩展到15亿参数,并在多个基准数据集上表现优异。
CIFAR-10上的FID(越低越好)为2.06,ImageNet 64×64上为1.48,ImageNet 512×512上为1.88。
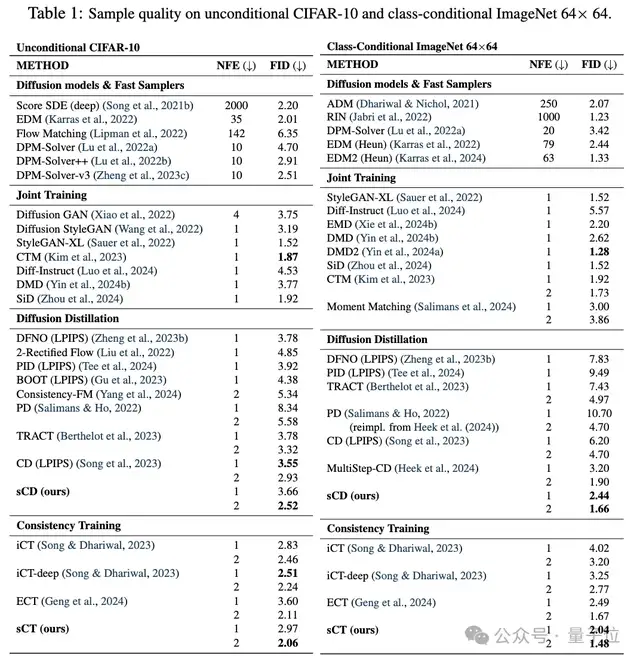
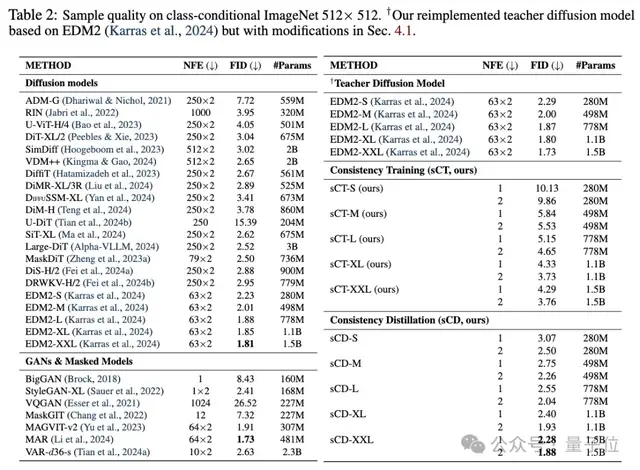
特别值得注意的是,这些模型只需要两步采样就能达到接近最好的扩散模型的生成质量(FID差距在10%以内),而计算开销仅为后者的10%。
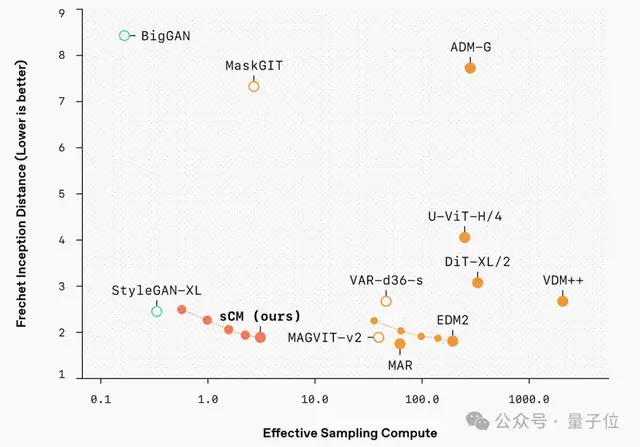
研究人员还比较了改进后的一致性模型与变分分数蒸馏(VSD)方法的区别,发现一致性模型能产生更多样的样本,并且在更高的引导水平下表现更好。
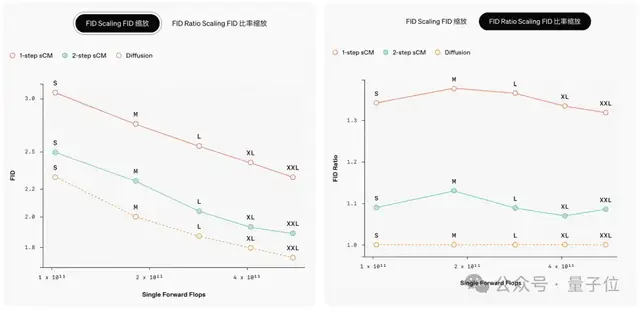
他们还有一个关键发现,随着teacher扩散模型的规模扩大,sCM的改进也呈比例增加。
用FID分数的比率来衡量样本质量的相对差异在模型大小不同的规模上是一致的,这意味着当模型规模增加时,样本质量的绝对差异会减小。
此外,增加sCM的采样步骤可以进一步减少质量差距。
 作者简介
作者简介路橙
去年在清华大学TSAIL实验室,在朱军教授指导下获得博士学位;2019年获清华大学计算机科学与技术系学士学位。
现在他是OpenAI研究科学家,对大规模深度生成模型和强化学习算法感兴趣。
他对一致性模型、扩散模型、归一化流和基于能量的模型及其在图像生成、3D 生成和强化学习中的应用有丰富的研究经验。

宋飏
宋飏在清华大学获数学和物理学士学位后,在斯坦福大学获得了计算机科学博士学位,导师Stefano Ermon。
其研究目标是开发能够理解、生成并处理多种形态高维数据的强大AI模型。
目前,宋飏专注于改进生成模型,包括它们的训练方法、架构设计、对齐、鲁棒性、评估技巧及推理效率。
他对探索生成模型作为科学发现工具的潜力也很感兴趣。

参考链接:
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章