新火种
2024-09-19
新火种
2024-09-19 


o1突发内幕曝光?谷歌更早揭示原理大模型光有软件不存在护城河
发布不到1周,OpenAI最强模型o1的护城河已经没有了。
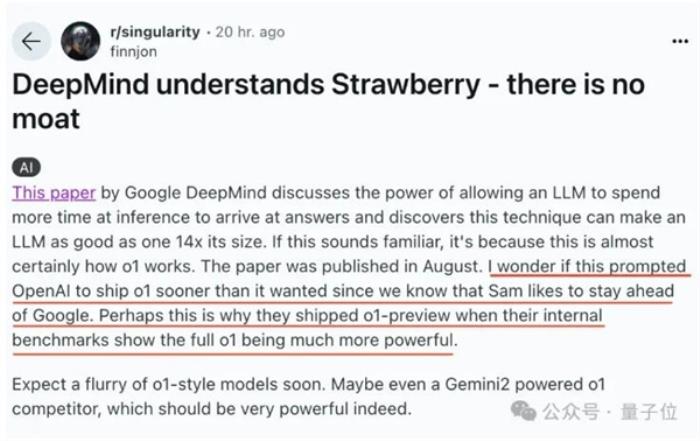
有人发现,谷歌DeepMind一篇发表在8月的论文,揭示原理和o1的工作方式几乎一致。

o1突发内幕曝光?谷歌更早揭示原理,大模型光有软件不存在护城河
这项研究表明,增加测试时(test-time)计算比扩展模型参数更有效。
基于论文提出的计算最优(compute-optimal)测试时计算扩展策略,规模较小的基础模型在一些任务上可以超越一个14倍大的模型。
网友表示:
这几乎就是o1的原理啊。
众所周知,奥特曼喜欢领先于谷歌,所以这才是o1抢先发preview版的原因?
o1突发内幕曝光?谷歌更早揭示原理,大模型光有软件不存在护城河
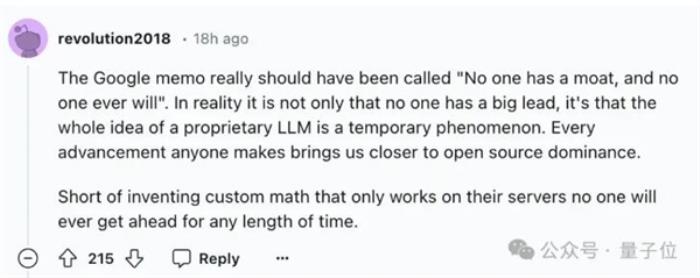
有人由此感慨:
确实正如谷歌自己所说的,没有人护城河,也永远不会有人有护城河。
o1突发内幕曝光?谷歌更早揭示原理,大模型光有软件不存在护城河
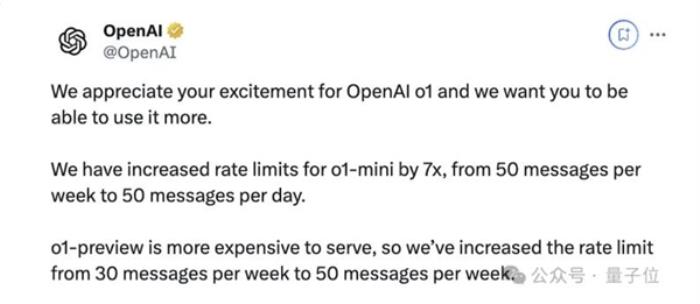
就在刚刚,OpenAI将o1-mini的速度提高7倍,每天都能使用50条;o1-preview则提到每周50条。
o1突发内幕曝光?谷歌更早揭示原理,大模型光有软件不存在护城河
计算量节省4倍
谷歌DeepMind这篇论文的题目是:优化LLM测试时计算比扩大模型参数规模更高效。
研究团队从人类的思考模式延伸,既然人面对复杂问题时会用更长时间思考改善决策,那么LLM是不是也能如此?
换言之,面对一个复杂任务时,是否能让LLM更有效利用测试时的额外计算以提高准确性。
此前一些研究已经论证,这个方向确实可行,不过效果比较有限。
因此该研究想要探明,在使用比较少的额外推理计算时,就能能让模型性能提升多少?
他们设计了一组实验,使用PaLM2-S*在MATH数据集上测试。
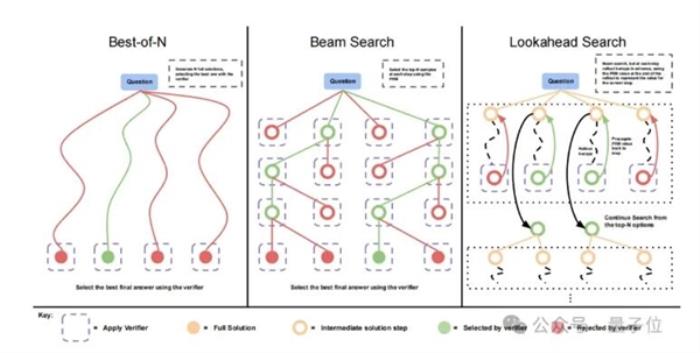
主要分析了两种方法:
(1)迭代自我修订:让模型多次尝试回答一个问题,在每次尝试后进行修订以得到更好的回答。
(2)搜索:在这种方法中,模型生成多个候选答案。
o1突发内幕曝光?谷歌更早揭示原理,大模型光有软件不存在护城河
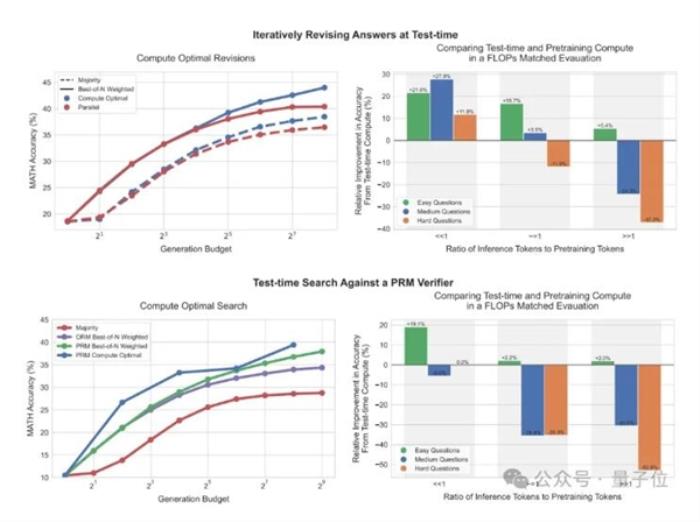
可以看到,使用自我修订方法时,随着测试时计算量增加,标准最佳N策略(Best-of-N)与计算最优扩展策略之间的差距逐渐扩大。
使用搜索方法,计算最优扩展策略在初期表现出比较明显优势。并在一定情况下,达到与最佳N策略相同效果,计算量仅为其1/4。
在与预训练计算相当的FLOPs匹配评估中,对比PaLM 2-S*(使用计算最优策略)一个14倍大的预训练模型(不进行额外推理)。
结果发现,使用自我修订方法时,当推理tokns远小于预训练tokens时,使用测试时计算策略的效果比预训练效果更好。但是当比率增加,或者在更难的问题上,还是预训练的效果更好。
也就是说,在两种情况下,根据不同测试时计算扩展方法是否有效,关键在于提示的难度。
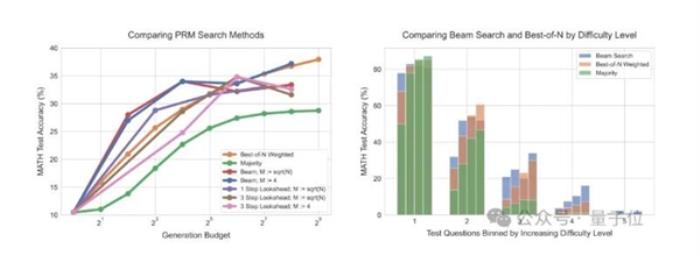
研究还进一步比较不同的PRM搜索方法,结果显示前向搜索(最右)需要更多的计算量。
o1突发内幕曝光?谷歌更早揭示原理,大模型光有软件不存在护城河
在计算量较少的情况下,使用计算最优策略最多可节省4倍资源。
o1突发内幕曝光?谷歌更早揭示原理,大模型光有软件不存在护城河
对比OpenAI的o1模型,这篇研究几乎是给出了相同的结论。
o1模型学会完善自己的思维过程,尝试不同的策略,并认识到自己的错误。并且随着更多的强化学习(训练时计算)和更多的思考时间(测试时计算),o1 的性能持续提高。
不过OpenAI更快一步发布了模型,而谷歌这边使用了PaLM2,在Gemini2上还没有更新的发布。
网友:护城河只剩下硬件了?
这样的新发现不免让人想到去年谷歌内部文件里提出的观点:
我们没有护城河,OpenAI也没有。开源模型可以打败ChatGPT。
如今来看,各家研究速度都很快,谁也不能确保自己始终领先。
唯一的护城河,或许是硬件。
o1突发内幕曝光?谷歌更早揭示原理,大模型光有软件不存在护城河
(所以马斯克哐哐建算力中心?)
有人表示,现在英伟达直接掌控谁能拥有更多算力。那么如果谷歌/微软开发出了效果更好的定制芯片,情况又会如何呢?
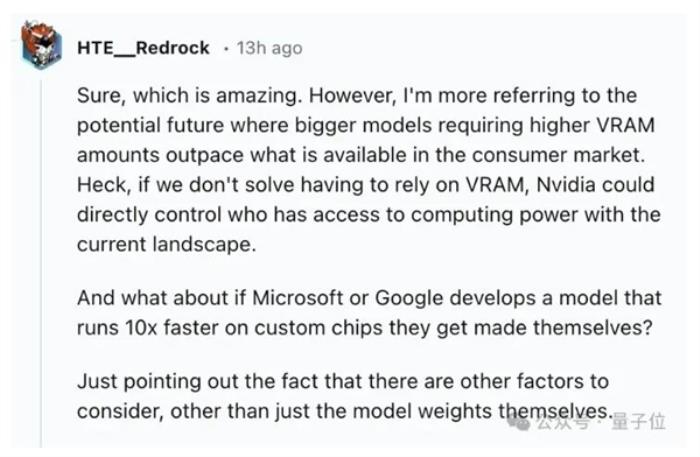
o1突发内幕曝光?谷歌更早揭示原理,大模型光有软件不存在护城河
值得一提的是,前段时间OpenAI首颗芯片曝光,将采用台积电最先进的A16埃米级工艺,专为Sora视频应用打造。
显然,大模型战场,只是卷模型本身已经不够了。
参考链接:
https://www.reddit.com/r/singularity/comments/1fhx8ny/deepmind_understands_strawberry_there_is_no_moat/
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章