新火种
2024-08-22
新火种
2024-08-22 


腾讯元宝治好了我的信息焦虑症。
作者:马蕊蕾 林杰鑫
编辑:林杰鑫
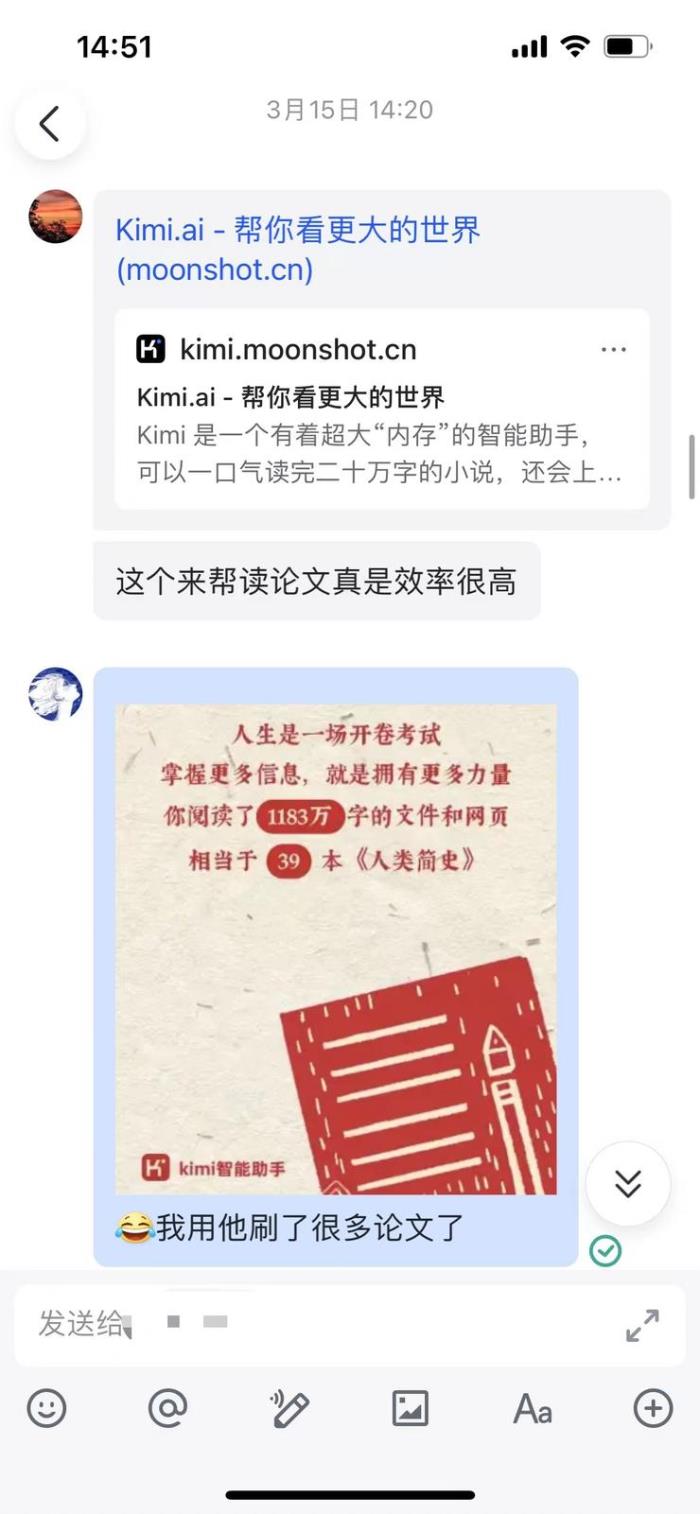
最近翻相册的时候翻到3月份的一张图片,恍惚间发现从事AI之后自己的阅读量一直在暴涨。

大模型重构了很多行业工作流中的思考角色,也导致在这个行业的人一直都有信息摄取焦虑症。因为各行各业搞研究的人脑洞大开。比如斯坦福大学用AI扮演不同的人搞了个AI社会启发清华大学用AI开游戏设计公司,后来就有AI模拟人类社会发展6000年,发现AI人类为了活下去会变得自私。这些都还好,看着挺趣味的也好理解,过家家嘛。


最头疼的就是那些个鬼:AI成功编辑人类基因,AI学会预测等离子体撕裂推进可控核聚变,AI设计了一套无需人类示范的欧几里得平面几何定理证明系统。(别看了,头痛,偏偏这些让我上课瞌睡的却成了我的工作内容。)
很长一段时间我都在测试各家的大模型读论文的能力,自己摸索了一套prompt:
总结论文内容,研究背景是什么,采用了什么方法论证,取得了什么积极性的突破,对比同类型研究有什么优势?将对普通人的生活产生什么影响?如果技术方法复杂,请用类比或比喻的手法辅助我理解。
这段话可以快速定位研究的目的和用途,同时了解这些研究会对咱这些平头老百姓会有什么影响。问题在于,大部分论文动不动几万字到十几万字的,有很多各行业的专业术语,AI能读,但给出来的结果往往是一个很空的大框架。更别说用比喻的手法解读一些内容了,因为AI的理解不够深入,也就不能做到用通俗易懂的话辅助理解.....

半年前我发现最好用的还是kimi,所以2个月时间我用他读了1183万字的论文,整个人的灵魂都升华了。当然,人嘛总是喜新厌旧,过了半年时间了,这会儿我也想看看其他家AI做的咋样,来一场横评。于是我打开我跟kimi的聊天记录打算看看以往遇到什么问题,然后就戴上了痛苦面具......
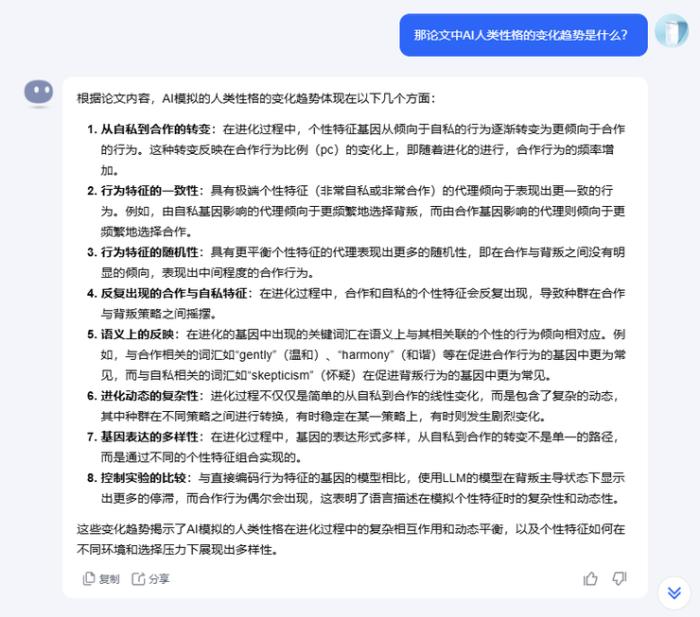
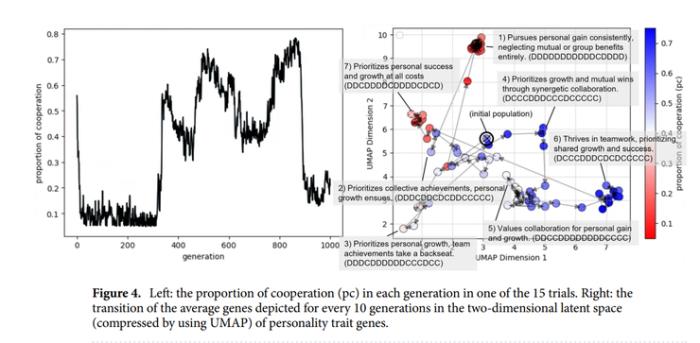
是的,看着过去的聊天记录我想起来kimi只会用OCR识别字但不会读图,所以很多论文的统计图kimi都无法识别,导致有些论文有大量曲线图、数据图的时候。kimi直接灯下黑睁眼瞎,像上面的图属于AI模拟人类社会发展1000代之后,人类性格转变曲线,如果论文没具体阐述,我是完全不知道如何变化的...也就无法获取关键信息。

所以这次评测我打算找一个长文理解能力不输kimi,然后又有图文理解能力的,但最好还是国内的,方便我随时使用。
初阶图片理解测试
首先是来一轮简单的图片理解测试。

在这里做个免责声明:大家都知道我这个人呢测试AI喜欢刁钻。没办法,经常有些AI大厂就喜欢拿大家用过的经典测试题钻漏洞,比如识别狗跟炸鸡这题以前很火,有一天AI突然集体开窍了,然后有网友换了下图片顺序,AI又识别不出来了。(嗯,大伙儿自己琢磨)


所以下面这轮测试我本来打算用广东2016年的高考语文题目来挑战一下AI图片阅读理解,但我怕这东西被AI偷偷摸摸练过,所以兄弟灵机一动,给图片打了一堆噪点。
这一轮就不欺负kimi了。来一轮已经确定有识别图片能力的大模型来一场皇城pk。阿里的通义千问、百度文心一言、字节豆包、腾讯元宝。
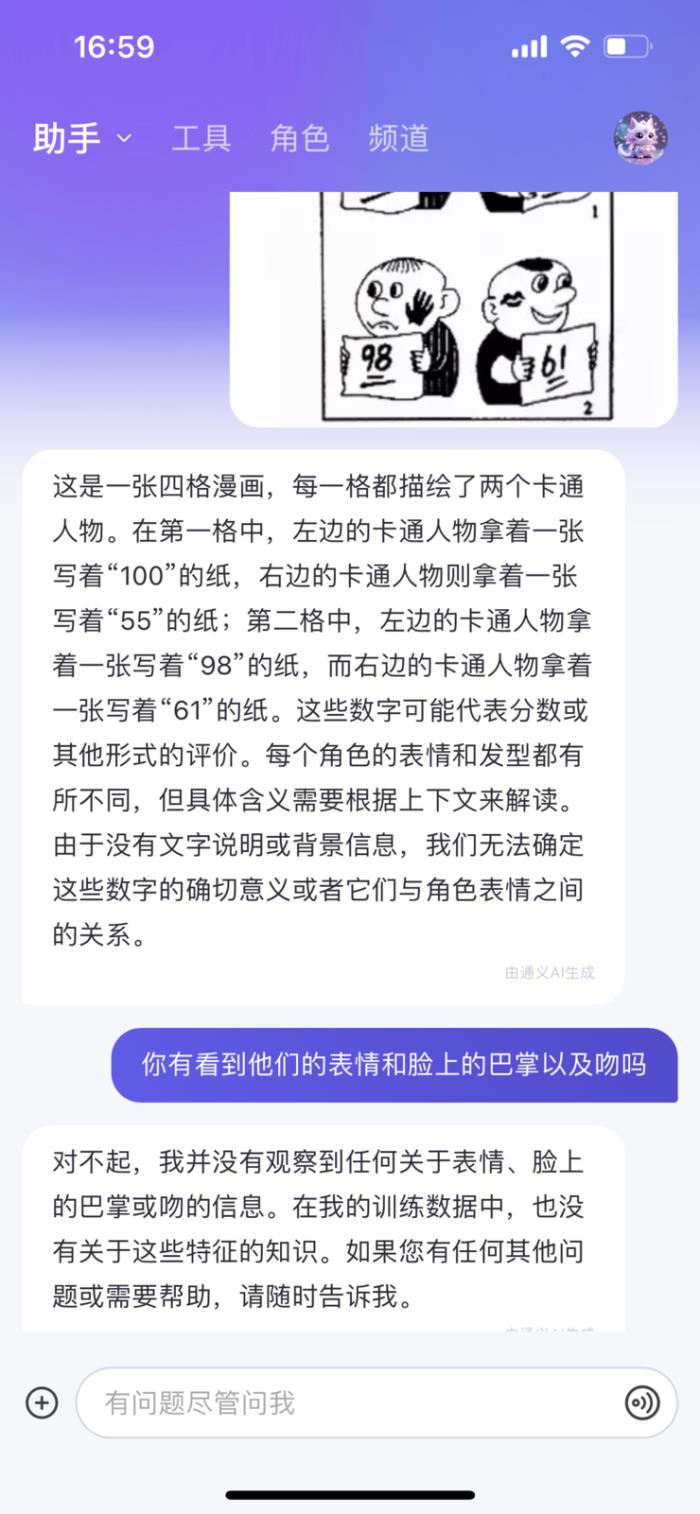

注意我这里用的是原图测试,我发现通义可以准确识别数字,但是无法深入解读表情、或者脸上的巴掌、吻,为了确认实验的严谨,我又上传了一张停车场的图片,发现它是能准确识别福特汽车的logo,所以也就不存在不能读图这一情况,而是他没训练过。

这是豆包的表现,连数字都读错了,那咱也就不继续了.....

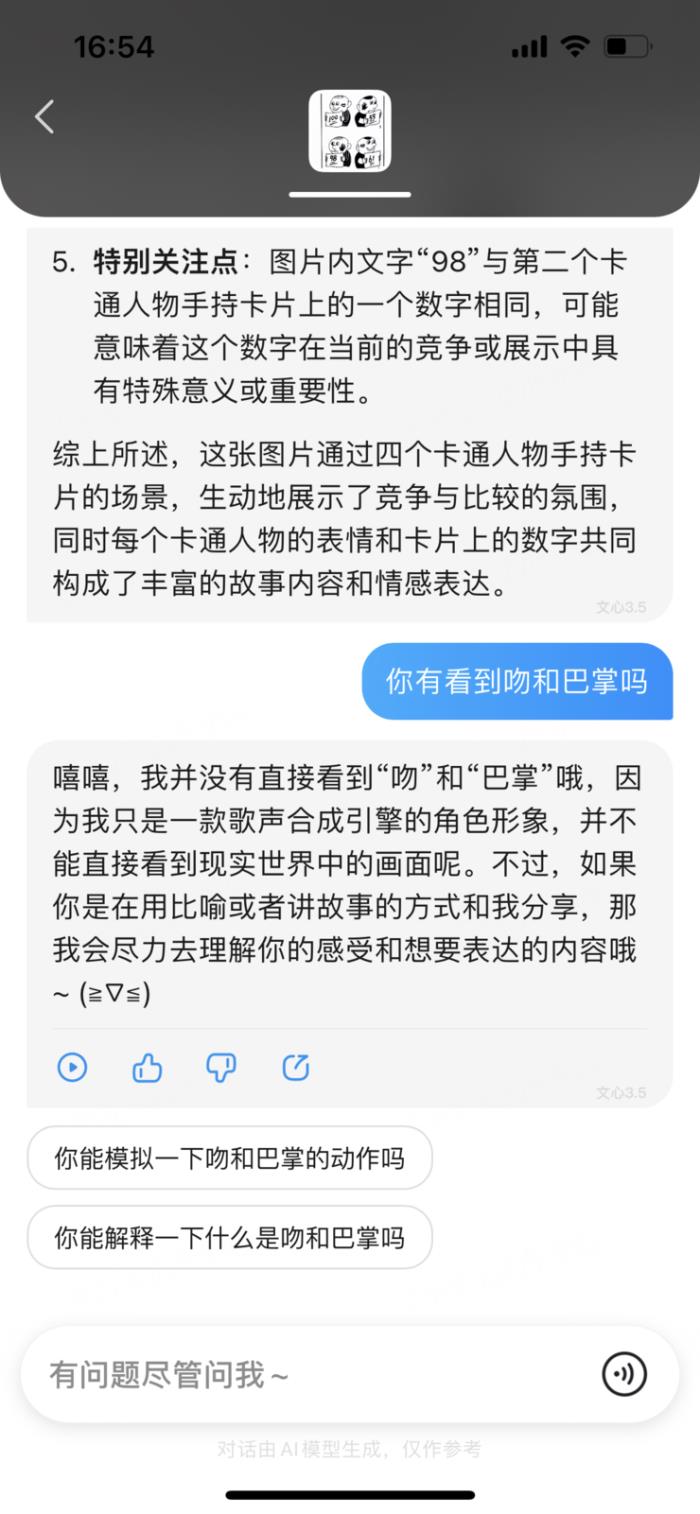
文心一言......虽然读出了分数,但是后面我问他看到巴掌和吻了吗.....这家伙回我一句“嘻嘻”,我&*%$#?!


说实话到元宝我已经放弃了,因为在我印象中,文心一言、通义千问、豆包都比元宝早出至少半年,而且元宝在我这确实没啥存在感。结果,兄弟咋回事?这就读出来了,而且还是加了噪点的图片???腾讯不声不响憋了个大的,然后当我问到这些表情特征的时候他还做了可能发生的情况的解读。
所以第一场pk,元宝取得领先优势。
那么既然各家确定有读图能力,接下来就加大难度,上有图文的长论文。
长文精读能力测试
论文名:《An evolutionary model of personality traits related to cooperative behavior using a large language model》
这篇论文内容,主要讲了用大模型生成不同性格的AI,模拟人类社会发展1000代,最后AI居然集体变为自私人格,自然杂志上的新研究揭露,AI在不受约束的情况下,可能整体都会趋向于自私。
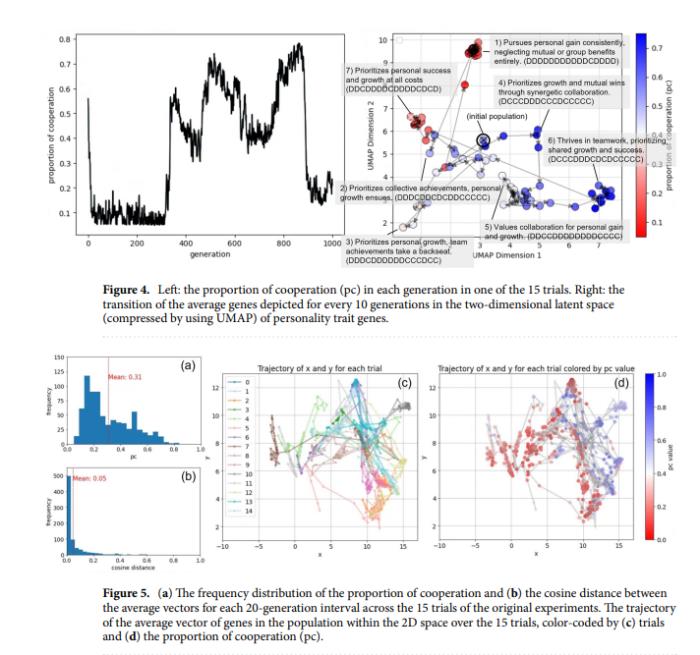
主要是论文中有一大坨的各种曲线图,要想更好的理解AI人类为了生存做出的性格改变就必须结合曲线图理解。
所以这里想看一下,各家大模型对于长文以及图片的总结能力。鉴于kimi有优秀的长文理解能力,所以这里还是拉上他来作为一个衡量各家质量的标杆。但这把不再是中国大模型内战,而是拉上目前国外目前T0级别的claude,直接上强度。
Kimi
提示词:总结论文内容,阐述研究背景,研究方法以及成果,实验者提供什么数据支撑他的实验。

我先是让kimi总结论文内容大致了解详情,得知这是一篇关于AI模拟人类社会发展和人类性格变化的论文。
于是我追问人类迭代的趋势是什么,kimi也给出了解答,但这个解答说实话没有将全文连贯起来读。
在后续的追问中也没体现出这张图表的波动。而是大致概括为 先自私然后偏向合作然后又可能变自私,但这个可能就很致命,因为在第900代的时候,所有AI是大幅度变自私。也就是kimi获取的信息不准确。
腾讯元宝

元宝我照例先问主要内容,我觉得训元宝的估计没少研究用户阅读习惯或者干脆就是一群有高效阅读强迫症的人练出来的。因为它生成的格式主次分明,从研究背景、研究方法、实验设计、结果分析、总体结论。感觉就像是读书时拿了学霸同学的笔记。而且用什么模型进行实验、关键数据包括哪些,都有呈现。这是同样提示词下,kimi所不具备的。

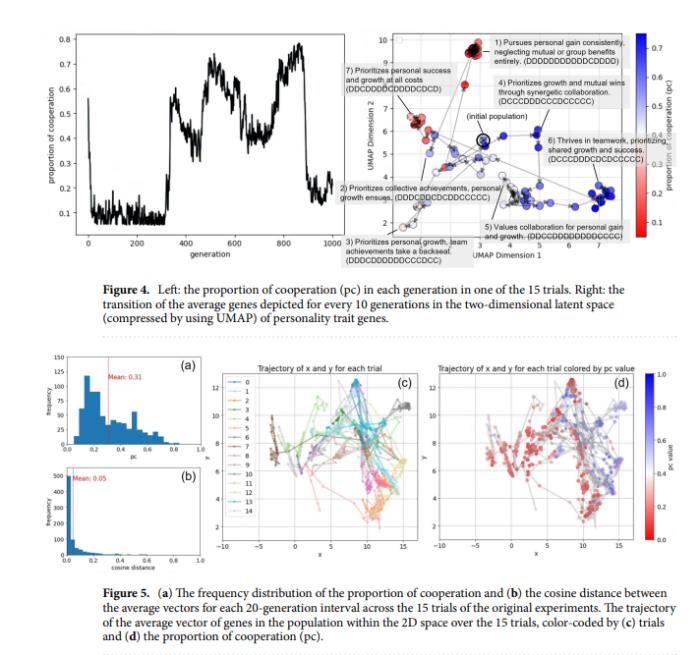
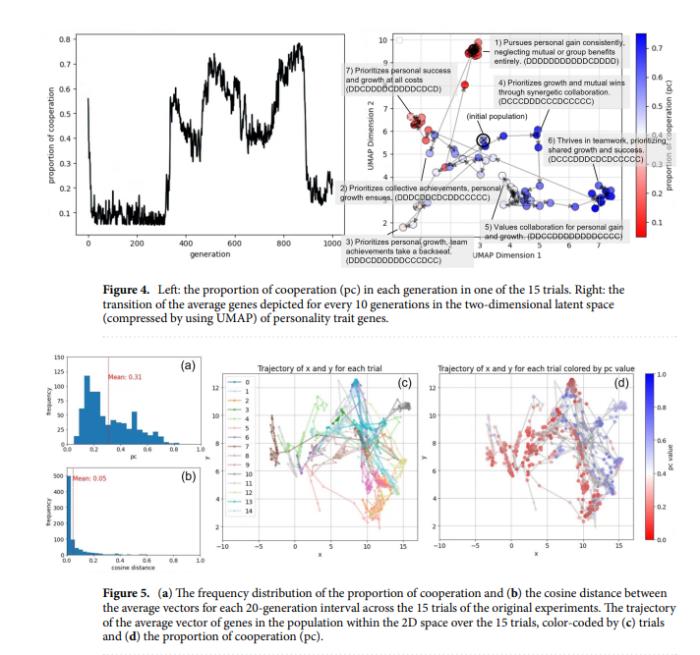
但相比于kimi,最大的差异点我认为还是在迭代趋势这里。元宝是能讲出曲线发展的波动。在进化过程中,初始阶段,持续到大约第300代后,合作比例迅速上升,到第350代左右占比达到0.55,然后在第450代左右下降到约0.40。接着,合作比例反复增加和减少,到第850代左右达到最高值约0.75,之后迅速下降到0.15左右。
根据数据波动又总结出出在进化过程中,AI人类的性格基因在二维空间中的分布显示出多次转变,反映了合作和自私性格特征的交替出现。也就是AI人类的进化一直在自私和合作之间反复横跳,并且给出了具体的时间周期。(历史果然是个车轮啊~)

而且,我还发现它左下角居然多了一个按钮——深度阅读该文档,一点进去,元宝老爷今天我给您磕一个,此后承蒙不弃,多多带我。
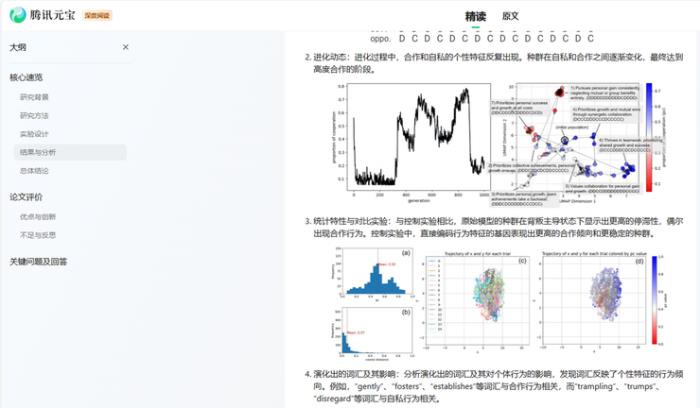
因为它直接将图表和内容结合讲述,把论文变成课件,以往我打开论文看到图表人麻了,因为我还得看小字去了解这是描述啥的图表。现在用元宝打开图表,我人炸了,因为我直接就悟了。
而且我怀疑腾讯是不是去哪里请来了金牌备课讲师,整个ui界面的视觉设计很符合阅读习惯,左边有论文的大纲,正文部分配合着图来看论文,如果不懂,还可以实时对内容进行提问,真的很懂我。


拉到底人家还摆了一个关键问题及回答,这玩意看得我虎躯一震。兄弟们,参加过答辩的应该都知道这功能的含金量吧?这是元宝教授在跟你模拟毕业答辩呢,考试前老师在给你划重点呢,还可以刷新不同的问题。

人家甚至会对论文进行评价,换句话说自己写的论文上传给元宝,元宝教你改论文,完事了还跟你模拟答辩,宝子哥,不仅看论文厉害,我发现估计写论文和模拟答辩还有奇效。
通义千问

整体思路看起来不错,开头简洁明晰的介绍了论文的研究重点,正文从研究的特点和成果进行展示,但是深究具体内容,会发现不是很全面,有些模糊,读完一席话,胜似一席话。
Claude-3.5

一眼看过去,Claude的回复真的很简洁,主要概括了论文的一些要点,没有特别成体系,但不得不说可能因为字数少,我竟然看进去了。但过于简洁,看完之后,我就没有然后了,对于我这个刚入门学习的人来说,不太友好。
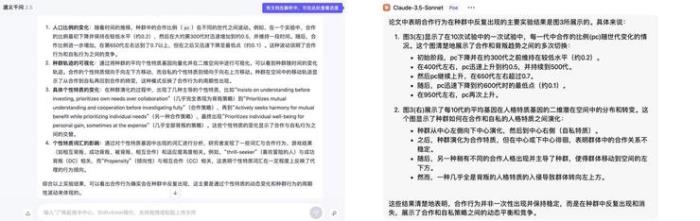
当然,通义千问和Claude-3.5在内容上也做到了元宝讲的总结出具体的数值,不同的是,Claude-3.5能清晰知道具体结论对应哪幅图,这一点上通义千问没有。但Clude3.5没有像元宝那样把图放在那讲,还得去翻图片来回滑动,看起来很麻烦。
从kimi、通义千问、腾讯元宝和Claude3.5的测试中,我意外还发现kimi和腾讯元宝的交互设计做的很丝滑。当提出问题得到相应的反馈后,这两家有一点非常Nice,点击生成答案的右下角的分享标识,他们都可以快速生成内容的长图或者链接。
其实通义千问,点击分享也会有相应交互,但是目前只能复制答案的链接,没有生成图片的功能,通义啊,这里可以改进一下下。
除了论文总结能力,读研报不知道各家表现怎么样,我们再试一试,看看效果。
分析研报
接着扔一个《2024巴黎奥运会热度趋势洞察》PDF,并加上帮我分析一下这份研报,概括出最重要的信息,字数不要超过500字。
通义千问
很简单的总结了一段话,细看内容只总结了平台和品牌合作,概括不太全面。

腾讯元宝

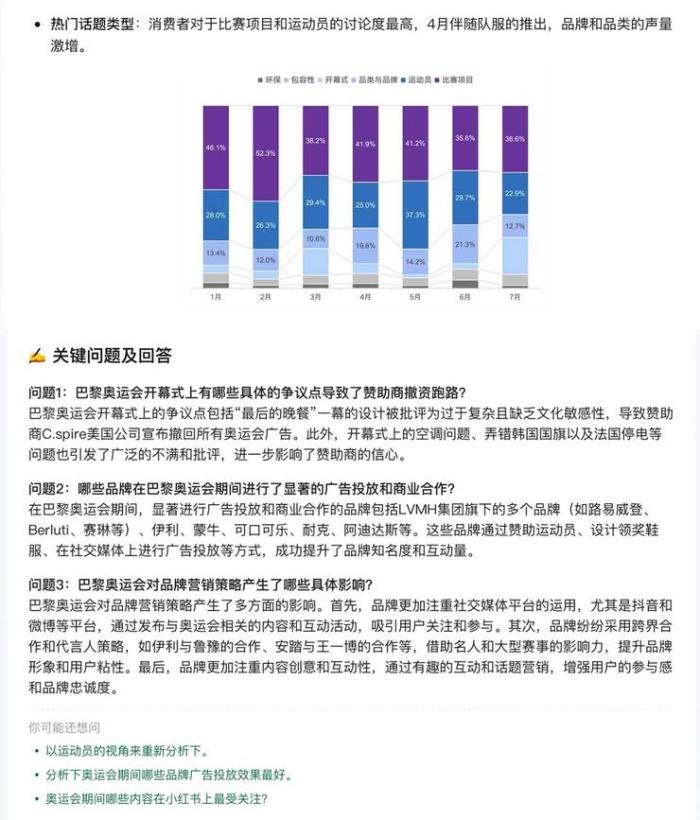
这里元宝我又i了,总结了研报的核心观点,还从奥运会热度扫描、话题洞察、品牌洞察分别概括了具体内容,很清晰。
如果作为一名短视频运营或者商家,你就会发现元宝的信息有多珍贵。首先他会跟你说主要热点有哪些。紧接着又指出两个热度最高的社交平台微博和抖音,其中微博是内容量占了全网68.3%,抖音互动奥运话题互动量占全网69.4%。
但元宝又指出,品牌方主要在小红书进行商业投放,原因是小红书热门话题更注重体育项目和运动员,抖音则以爱国话题为主。同时从消费者趋势来看,小红书女性用户多,抖音男性用户多,25~34岁是主要人群。这下消费者画像不就一下子清晰了?每个研报如果都能这么总结,我一天能看100份。
重点是它的深度阅读依旧可以总结重点信息还带配图的那种,每次精读的尾声部分,还能再来一波关键问题的解答。
Claude-3.5

中规中矩,很简洁的概括了一些想要看到的信息。整体体验下来,元宝确实在长文精读方面的能力更强,在内容和文本格式方面都很在线,我感觉它很懂用户的阅读使用习惯,深度阅读模式的大纲、图文搭配、实时对文章进行提问的能力,用起来一整个都很舒适!
番外测试篇
当然最近网上也很流行测AI理解梗图的能力和数学逻辑推理,所以这里也测点网上大家都喜欢测的,看看各家的表现。

上传一张表情包,问:这个表情包实际代表什么意思?
通义千问

能看出它有很认真的去理解表情包,物理层面有了,缺了点化学反应,幽默和倦怠点题了。
腾讯元宝
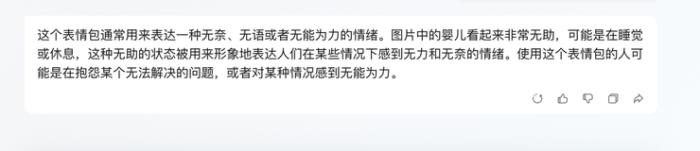
元宝真是懂打工人的,直接明了的对准一个情绪。
“在抱怨某个无法解决的问题”or“对某种情况感到无能为力”。
Claude3.5

这一波Claude读出了很多种复杂的情绪,看上去比我更会形容日常的无奈。
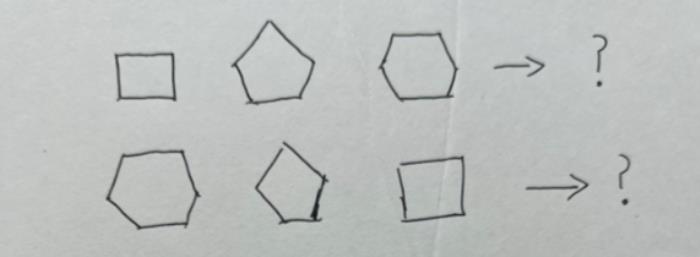
接下来是简单的数学逻辑推理,为了防止题目被AI训练过,所以我对同个图形进行顺序颠倒的测试。
文心一言


这不,文心一言就漏出鸡脚了,正向回答没问题,反向回答却是比正方形更简单或与正方形相似......


通义千问正常通关。

元宝也正常通关。

插个题外话,我今天在用腾讯元宝的时候,也想看一下它实时联网更新获取最新信息的能力。原因是大部分AI虽然现在有联网功能,但它一般搜索的都是一些陈年消息作为参考。
当我试着搜索AI在义乌的应用时,居然搜到了上周五自己写的文章,并且元宝还对文章内容进行了概括,我顺带试了试其他家,目前只有元宝能搜到。
这次横测,有一种感觉,各家大模型好像在去年的百模大战之后,就变得有些懈怠。其实作为用户,还挺想看各家卷来卷去的,这样就会有更好用的产品帮我“打工”。
说真的,AI产品的优势在于持续进化的过程,没有永远的胜者,只有永远的创新者。
这是一场漫长的竞争,而更好的用户体验是唯一不会变的法则。
()

相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章