新火种
2024-05-11
新火种
2024-05-11 


对话吴新宙:智能驾驶和座舱,英伟达的「三步走」规划
北京车展前夕,英伟达在北京办公室召开了北京车展媒体沟通会。
英伟达全球副总裁、汽车事业部负责人吴新宙,英伟达汽车事业部数据中心副总裁Norm Marks, 英伟达全球副总裁、中国区汽车事业部负责人刘通等人出席。这是吴新宙履新英伟达的第7个月。
在这次沟通会之后的车展上,英伟达与奇瑞汽车签订了合作协议,双方宣布围绕英伟达旗下的DRIVE Thor计算平台联合打造新一代高端智驾平台,该平台将会在星途高端车型上首发。同一天里,由吉利控股和百度联合打造的极越,也宣布采用新一代的DRIVE Thor计算平台。
吴新宙表示,“DRIVE Thor大概2025年开始有第一代的SOP,芯片也会比较快地拿到样片。”
英伟达正在逐渐扩大它在智能驾驶领域的领地。不过,吴新宙却说,“英伟达是定位于整个AI生态的赋能者,不止是专注于做车。可以说每个AI的突破,我们都希望在NVIDIA的生态中产生。”
AI定义汽车与软件定义汽车有何不同?吴新宙表示,过去十年,软件定义汽车在汽车领域产生了非常深远的影响,特别是通过OTA技术,把汽车这样一个固定不变的硬件产品变成可以自学习、不断变化的用户产品。但是,随着生成式AI的大规模进展,AI定义汽车一定会是趋势。
自动驾驶并不是一个新鲜事物,早在上世纪90年代的美国,就已经有了自动驾驶的相关论文和落地尝试。而我们熟悉的现代化的自动驾驶的发展会经历三段式的发展。
第一代的自动驾驶系统是完全基于规则,有着大量人工Engineer Feature(工程师特征),通过很多算法去完成让车自己开的动作。
第二代就是目前市场的主流,用大量的AI取代原有的人工Engineer Feature(工程师特征),不管是预测还是规划都在用模型去做,但是仍然需要很多工程师的介入才能把获取到的数据用好。
第三代应该会通过NVIDIA达到更大的突破,就是变成端到端大模型的方式。
吴新宙向表示,“这个过程不可避免,并在接下来的五年内发生。”
而未来的AI汽车会比现在的自动驾驶开发简单很多,更多地集中在云端。因为英伟达在云端有大量的自动驾驶模型训练的能力,仿真、验证都可以放在云端进行。目前,这些技术的积累在自动驾驶系统的开发流程中已经比较成熟,车端能够把Corner Case的数据准确触发反馈到云端。
相比之下,软件定义汽车则有了诸多“落后”之处。
软件定义汽车需要大量工程师介入,所有的组件的算法开发量非常大,比如Corner Case识别比较慢,需要海量的路测,只有测过的路线,大家才有信心在ODD(运行设计域)释放,这是非常大的系统开发工作流程。
另一方面,需要大规模的测试、运营,需要准确、快速地把数据回传给工程师,需要一个非常好的基础建设设施支持数据设施闭环。
经过大量测试以后,软件定义汽车是通过OTA的方法更新,现在还有国家合规的要求,不管是软件开发、模型开发还是数据闭环需要大量人工参与的工作。
所以,这也是AI定义汽车与软件定义汽车的区别,前者可以让流程得到很大的简化。
在AI定义汽车时代,大部分模型都能够在云端完成训练,通过数据驱动的方式,车端触发Edge Case(边缘案例),然后通过自动数据驱动完成模型的自我迭代,也可以在云端通过仿真完成大部分的验证,极大地减少车端大规模设备部署和测试的依赖性。未来的部署也可以简化成模型更新的工作,而不是巨大的代码更新。
除了自动驾驶,智能座舱也会面临大变化。随着生成式AI能力的进一步提升,也会对座舱有巨大的提升。NVIDIA在智能驾驶和座舱领域有哪些举措,吴新宙提出了一个三步走的规划。
第一步是完善现有的L2和L2+系统,以达到市场领先水平或者第一梯队水平;
第二步希望L2++领域取得新突破,实现未来软件栈的端到端可训练,将上游模型和下游模型打通,整体上用生成式大模型的布局已经开始,今年晚些时间会有DEMO展示,通过端到端模型的方式完成;
第三步就是希望能够在2026年量产的L3,实现完全自动驾驶。
端到端的行业热点,绕不开的数据难题除了AI与大模型方面的规划,英伟达还在使用生成式数据,其自研渲染工具Omniverse能够实现数据生成,补足仿真Corner Case,从而快速转成虚拟数据,然后进行随机处理,衍生出更多的Corner Case。
目前就有多家中国车企通过Omniverse虚拟现实技术实现对汽车制造工厂的工作流程优化。
英伟达中国区汽车事业部负责人刘通透露,除了在端到端全栈式合作,包括车端芯片DRIVE Orin和DRIVE Thor、智驾芯片和数据中心端的解决方案等,比亚迪和NVIDIA还在智能工厂方面进行合作,利用Omniverse做自主机器的仿真,包括物流小车、机械臂等。
英伟达汽车事业部数据中心副总裁Norm Marks表示,自动驾驶汽车1.0时代主要是基于标注图像的训练,并在上面开发和部署深度神经网络的集成,可能会有40-50个深度神经网络从L2+层级转向更高级的自动驾驶。假设一个车队50辆测试车,每周可能会生成2PB的数据,但其中只有10%-15%会得到标注。
而在自动驾驶汽车2.0时代,是基于视频进行模型的训练,就像真人看世界那样,是一整个大的融合世界的统一模型。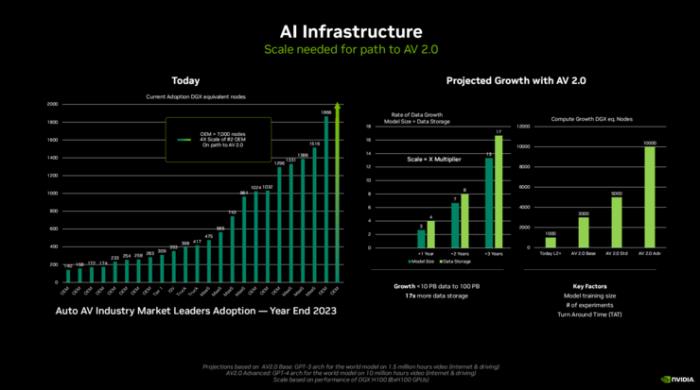
Norm Marks还预计,未来自动驾驶汽车2.0转型的模型规模将增长13倍,数据存储规模将增长17倍。基于Transformer需要3000个服务器节点,而如果以GPT4作为基础的话需要上万的服务器节点,即达到超算水平。
英伟达的NeMo平台可作为一站式工具帮助构建大语言模型,从最开始的数据准备、数据获取、数据测转、预训练、模型定制化、提示语调优化以及人为反馈进入闭环,包括后续的信息检索,实现比较精确的信息检索。
在沟通会上,吴新宙还对今年最热的端到端话题进行了回应。
虽然端到端智能驾驶方案已经成为业内的一个共识,但是端到端的问题也很明显:通常需要处理大量的传感器数据,包括图像、点云、雷达等,直接输出控制指令,对算力的要求较高。此外,为了训练这些复杂的神经网络模型,需要大量的标注数据。
吴新宙认为,“端到端模型上线之前,一定会有一个“护栏”,因为需要不停地优化和成长,要是一开始就上线端到端的模型是非常困难的。把端到端模型做好的企业一定也需要非常好的第二代甚至第一代的自动驾驶堆栈。”
所以,端到端模型仍然离不开原有模型,通过原有的模型和方法保证安全性,这些是把端到端模型真正大规模部署变成主流的过程。
至于如何解决黑盒问题,吴新宙提出了几个纬度:
一、原有的第一代、第二代算法栈,可以保证端到端模型的安全性,也可以不停地判断端到端模型决定的合理性,把双方有差异的地方作为输入。这就类似于大语言模型训练的反馈,让结果更加合理化,
二、未来的大模型、端到端模型有周边的输出点可以观测,比如可以观测DEV输出的结果,训练的时候也是部分训练等。于是在黑盒上开启几扇“窗”,看到信号是怎样的模式。
吴新宙认为,英伟达的一个巨大优势就是端到端,而且是整体AI赋能,汽车只是其中的一个垂直领域。
他表示,“我们在数据中心、训练工具都有巨大的投入,我们有SoC和安全平台,从底层软件加上芯片,所有的每一层都有引入非常强的安全概念,我们还有端到端全栈软件的开发。以上四个方面构成我们汽车生态系统,”
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章