新火种
2024-04-15
新火种
2024-04-15 


谷歌爆改Transformer,“无限注意力”让1B小模型读完10部小说
谷歌大改Transformer,“无限”长度上下文来了。
现在,1B大模型上下文长度可扩展到1M(100万token,大约相当于10部小说),并能完成Passkey检索任务。
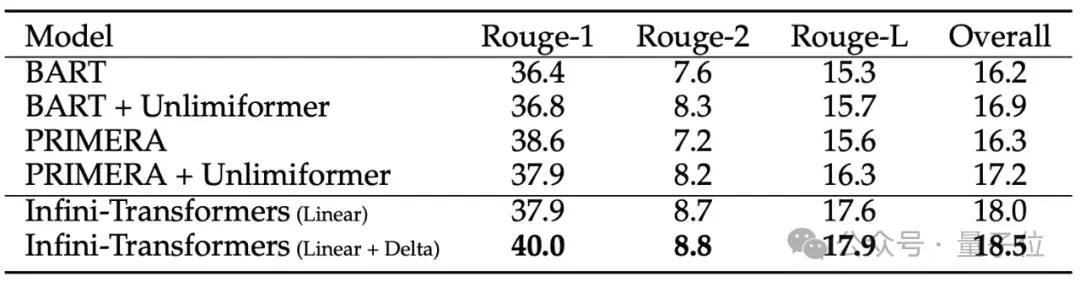
8B大模型在500K上下文长度的书籍摘要任务中,拿下最新SOTA。
这就是谷歌最新提出的Infini-attention机制(无限注意力)。

它能让Transformer架构大模型在有限的计算资源里处理无限长的输入,在内存大小上实现114倍压缩比。
什么概念?
就是在内存大小不变的情况下,放进去114倍多的信息。好比一个存放100本书的图书馆,通过新技术能存储11400本书了。
这项最新成果立马引发学术圈关注,大佬纷纷围观。

加之最近DeepMind也改进了Transformer架构,使其可以动态分配计算资源,以此提高训练效率。
有人感慨,基于最近几个新进展,感觉大模型越来越像一个包含高度可替换、商品化组件的软件栈了。

引入压缩记忆
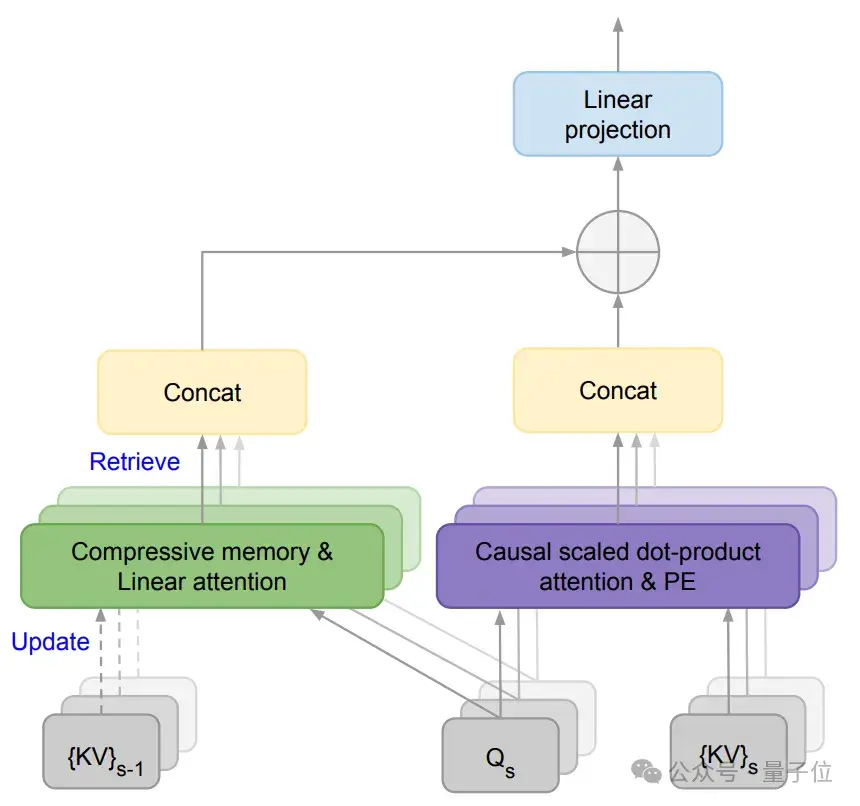
该论文核心提出了一种新机制Infini-attention。
它通过将压缩记忆(compressive memory)整合到线性注意力机制中,用来处理无限长上下文。
压缩记忆允许模型在处理新输入时保留和重用之前的上下文信息。它通过固定数量的参数来存储和回忆信息,而不是随着输入序列长度的增加而增加参数量,能减少内存占用和计算成本。
线性注意力机制不同于传统Transformer中的二次方复杂度注意力机制,它能通过更小的计算开销来检索和更新长期记忆。
在Infini-attention中,旧的KV状态({KV}s-1)被存储在压缩记忆中,而不是被丢弃。
通过将查询与压缩记忆中存储的键值进行匹配,模型就可以检索到相关的值。
PE表示位置嵌入,用于给模型提供序列中元素的位置信息。
对比来看Transformer-XL,它只缓存最后一段KV状态,在处理新的序列段时就会丢弃旧的键值对,所以它只能保留最近一段的上下文信息。
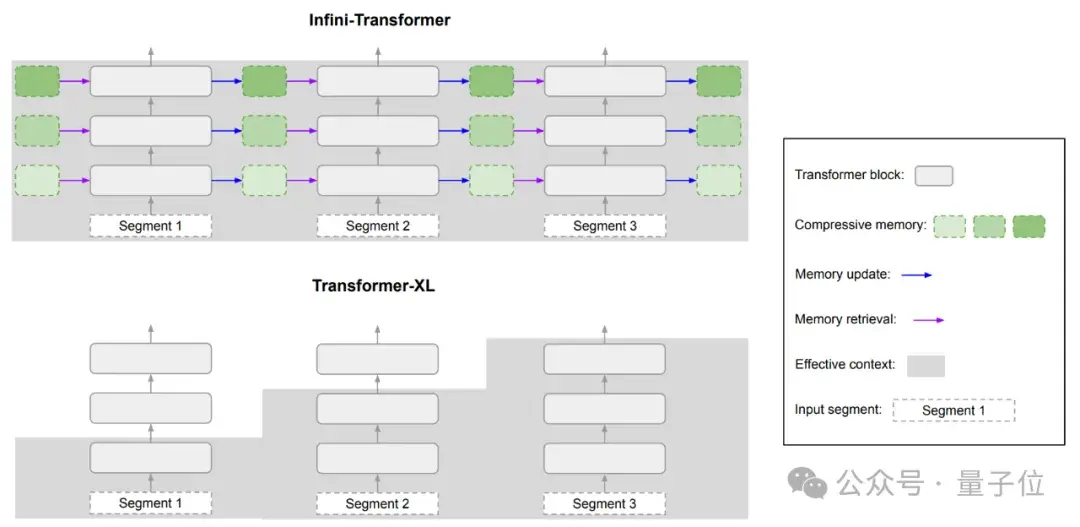
对比几种不同Transformer模型可处理上下文的长度和内存占用情况。
Infini-attention能在内存占用低的情况下,有效处理非常长的序列。

Infini-attention在训练后,分化出了两种不同类型的注意力头,它们协同处理长期和短期上下文信息。
专门化的头(Specialized heads):这些头在训练过程中学习到了特定的功能,它们的门控得分(gating score)接近0或1。这意味着它们要么通过局部注意力机制处理当前的上下文信息,要么从压缩记忆中检索信息。
混合头(Mixer heads):这些头的门控得分接近0.5,它们的作用是将当前的上下文信息和长期记忆内容聚合到单一的输出中。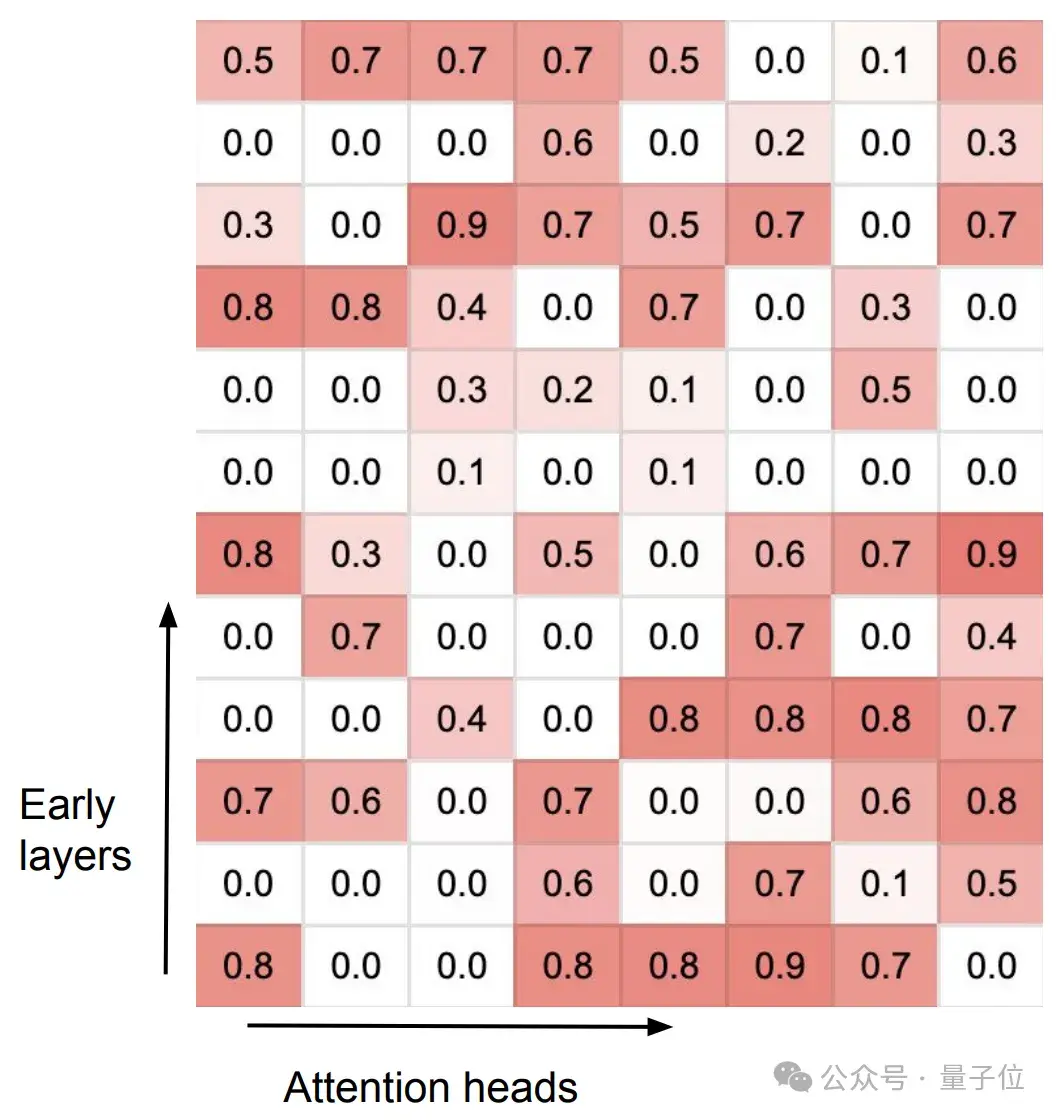
研究团队将训练长度增加到100K,在Arxiv-math数据集上进行训练。
在长下文语言建模任务中,Infini-attention在保持低内存占用的同时,困惑度更低。
对比来看,同样情况下Memorizing Transformer存储参数所需的内存是Infini-attention的114倍。
消融实验比较了“线性”和“线性+增量”记忆两种模式,结果显示性能相当。

实验结果显示,即使在输入只有5K进行微调的情况下,Infini-Transformer可成功搞定1M长度(100万)的passkey检索任务。
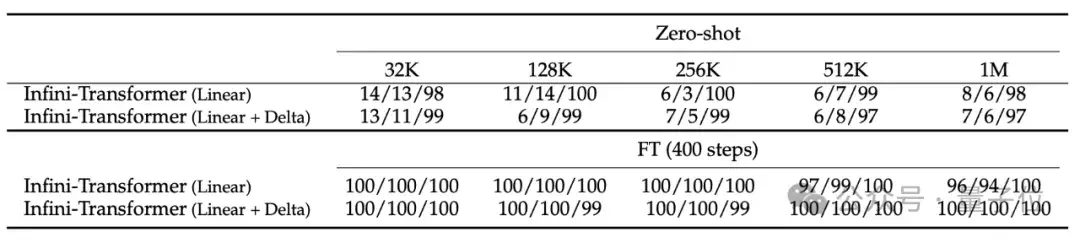
在处理长达500K长度的书籍摘要任务时,Infini-Transformer达到最新SOTA。
Bard成员参与研究
该研究由谷歌团队带来。
其中一位作者(Manaal Faruqui)在Bard团队,领导研究Bard的模型质量、指令遵循等问题。

最近,DeepMind的一项工作也关注到了高效处理长序列数据上。他们提出了两个新的RNN模型,在高效处理长序列时还实现了和Transformer模型相当的性能和效率。

感觉到谷歌最近的研究重点之一就是长文本,论文在陆续公布。
网友觉得,很难了解哪些是真正开始推行使用的,哪些只是一些研究员心血来潮的成果。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章