

 新火种
2023-12-19
新火种
2023-12-19 


试了试Meta的最新语音生成器,逼真得有点毛骨悚然
机器之能报道
编辑:吴昕
《小红帽》故事中的所有音频都是 AI 生成的,你能听出来吗?作品出自一个非常酷的语音生成工具 Audiobox Maker,你可以在 Meta 刚刚发布的一个新的交互式网站 audiobox.metademolab 上找到它。
有了它,仅用几分钟的时间,机器之心也随意生成了关于五月天假唱热搜的对话:
透过 Audiobox Maker ,即使是小白用户也可以设计、生成不同人物(比如小红帽、大灰狼和外婆)的声音文件,同时添加不同声效,通过拖曳、排列组合各种文件(就像搭乐高),自编自导一出故事。
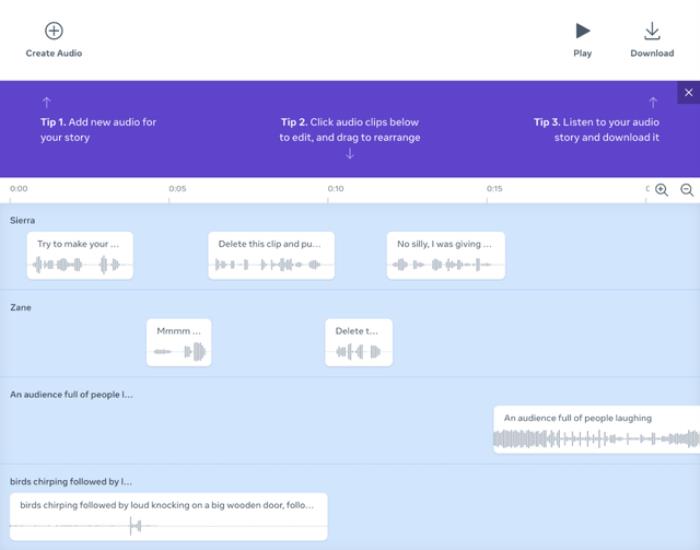
我们使用 Audiobox Maker 制作关于五月天假唱对话的语音作品示例,生成了两个对话人物的音频,还有背景声效,通过拖曳不同模块进行编辑。
有学者说,2023 年是语音之年( Year of Sound Waves )。
确实,从电影、游戏、播客到有声读物,声音的魅力和地位可谓举重轻重。然而,制作高质量的音频却不是一件容易的事,特别是对无数业余爱好者来说。
为了改变现状,无论是 OpenAI、谷歌、微软、Meta 、亚马逊还是一众初创公司,都在语音生成方面投入了大量资金。
6 月,Meta 曾推出全新的语音生成 AI 模型—— VoiceBox,能从文本直接生成高质量语音,不需要任何语音样本作为训练数据。
由于当时对基于 AI 的深度伪造的担忧日益加剧,Meta 并未向公众开放 Voicebox。
意外的是,本周一,Meta 发布了一个新的交互式网站,支持大众免费体验 「 Voicebox 的接班人」、最新的音频生成器 AudioBox。
Audiobox Maker 只是 AudioBox 的一个体验内容。
事实上,你可以将 Audiobox 看作一个汇聚了六个 AI 工具的「模型系列」,包括克隆声音、文本到声音、文本到音效(比如掌声、狗叫、汽车喇叭、雷声)、在指定地方添加音效或删除指定部分等。
机器之心也立刻体验了一把几个 AI 功能,非常有意思。不过,遗憾的是目前并不支持中文。
最让人印象深刻的工具—— 从文本直接生成各种音效。
虽然 Audiobox 建立在 Voicebox 框架之上,但它可以生成更多种类的声音,特别是不同环境的声效。
只需给模型一个文本提示即可,例如「一条流淌的河流和鸟儿的鸣叫」:
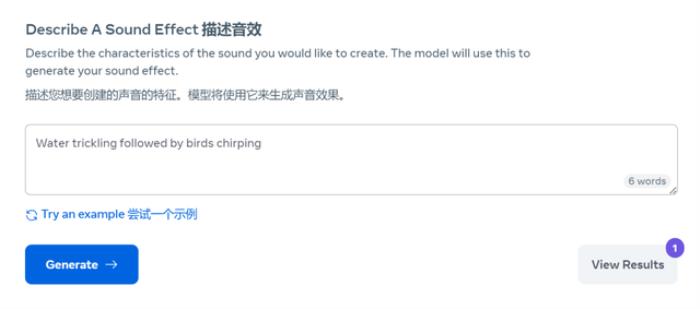
Meta 声称,与之前最先进的产品相比,Audiobox 将 FAD (Frechet Audio Distance 的缩写,FAD 值越小越好)降低了 50% ,在质量和保真度方面堪与真实音频相媲美。
换一个声效提示试试—— The sound of the brook accompanied the laughter of the young woman ,感觉后半段有点恐怖了。
克隆自己的声音
先录制一段自己的声音,想听听克隆声音朗读葡萄牙著名诗人卡蒙斯的诗的感觉,结果发现,目前并不支持葡萄牙语,只好更换为叶芝的诗歌 When you are old。
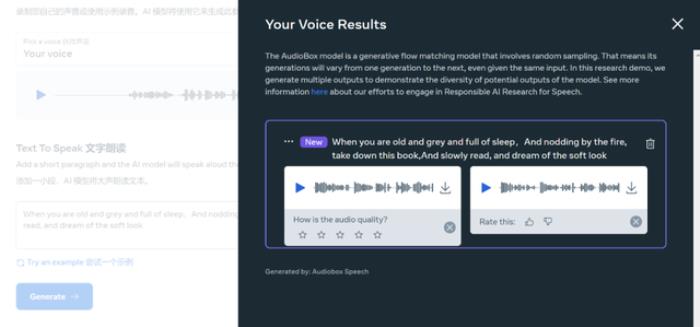
很快,就生成了两个音频供选择。说实话,本人很难分辨哪个更好,因为都很像。
Audiobox 使用了一种定制求解器,Meta 声称,这种求解器使生成过程比以前的模型快 25 倍以上,而不会损失性能。
不想用克隆的声音?没问题,同样是朗读When you are old,你还可以直接通过文本提示,利用 AI 生成最适合的声音:输入提示,an old english man with a deep yet soft voice. He speaks with a slightly flat tone and his emotions are enthusiastic. The audio is high quality and it sounds like it was recorded by the sea。
oldman
值得注意的是,用户还可以结合语音输入与文本样式提示,生成任何环境(例如,海边)或任何情绪(例如,悲伤而缓慢地说话)下的语音。
Meta 声称,Audiobox 是第一个支持该双输入(声音样本和文本描述提示)的语音生成大模型,最大限度提高了每个用例结果的可控性。
比如,我们想让朗读 When you are old的声音变得更成熟一些,想象背景里还有淅淅沥沥的雨声和远处的雷声(是不是更有意境?)
我们用自己的声音录制了样本,再加上文本提示:
A middle-aged person speaking with a relaxed, friendly voice. Background includes rain sound and distant thunder.
效果如下:
音频和文本提示双重控制生成
Audiobox 还支持声音填充功能,根据文本描述将指定音频的一部分替换为新声音。
我们试着将刚才生成的一段女人笑声伴随河流声的部分音频(紫色部分)更换为一阵狗吠,还有沉重的脚步声。
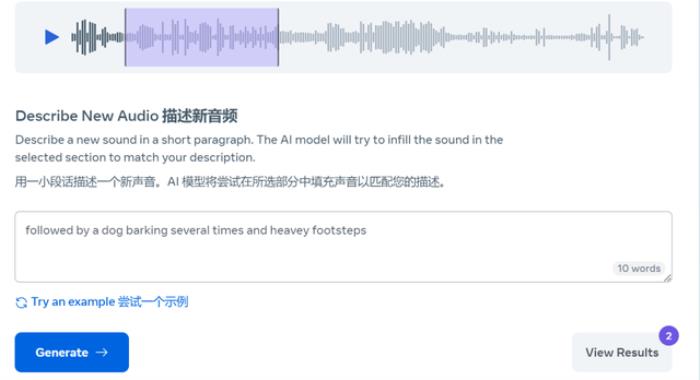
效果还不错:
填充声效
除了上述功能,用户还可擦除指定部分的音频。
必须说明的是,可能出于伦理安全方面的谨慎,系统约束过多。几乎每次输入都会碰到系统显示无法处理的情况,要修改甚至放弃原来的表述,才可能成功,因此很难顺利按照自己既定的脚本,完成音频生成。
与 Voicebox 相比,Audiobox 的生成质量更优。通过「结合使用语音输入和自然语言文本提示」生成语音和声音效果,最大限度提高结果的可控性。
另外,和 Voicebox 不同,所有这些音频生成、编辑等功能,都「建立在共享的自监督模型 Audiobox SSL 之上。」
换句话说,通过统一语音和音景的生成和编辑功能,Audiobox 进一步推进了音频的生成 AI 的进步。
在安全性上,使用 Audiobox 创建的任何音频都带有自动水印,可以准确地追溯到其来源。
该技术目前不能用于任何赚钱/商业目的,奇怪的是也不能被美国人口最多两个州的居民使用。但随着 AI 的快速发展,预计这种情况会改变,在不久的将来会有商业版本,即使不是来自 Meta,也会来自其他人。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










