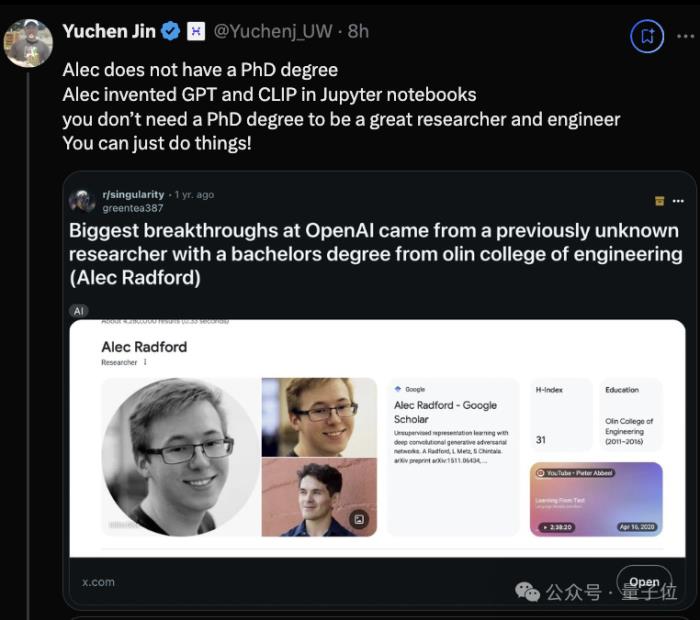
新火种
2023-11-01
新火种
2023-11-01 


字节跳动开源分布式训练框架BytePS,支持PyTorch、TensorFlow等
机器之心报道
参与:戴一鸣、思源
最近,字节跳动发布了一款通用高性能分布式训练框架 BytePS,该框架支持TensorFlow、Keras、PyTorch 和 MXNet,并且可以在 TCP 或 RDMA 网络上运行。根据该项目的 GitHub 页面,BytePS显著优于目前的开源分布式训练框架。例如在流行的公有云和同样数量 GPU 上,BytePS 的训练速度可以达到Horovod (NCCL) 的两倍。
最近,字节跳动发布了一款通用高性能分布式训练框架 BytePS,该框架支持 TensorFlow、Keras、PyTorch 和 MXNet,并且可以在 TCP 或 RDMA 网络上运行。
BytePS GitHub 地址:https://github.com/bytedance/byteps
根据该项目的 GitHub 页面,BytePS 显著优于目前的开源分布式训练框架。例如在流行的公有云和同样数量 GPU 上,BytePS 的训练速度可以达到 Horovod (NCCL) 的两倍。
框架性能
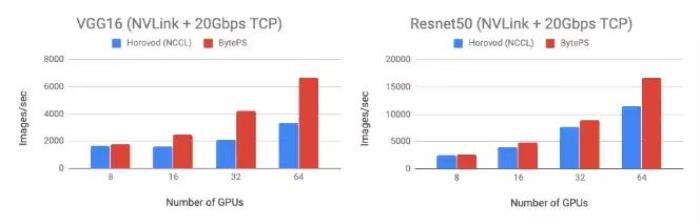
开发团队在 BytePS 上测试了两个模型:VGG16(通信密集)和 Resnet50(计算密集)。测试使用了 Tesla V100 16GB GPU 集群,批大小都是 64。机器使用的是公有云上的虚拟机,每个机器有 8 个 GPU,集成了 NVLink。机器之间使用 20 Gbps TCP/IP 网络互通。在测试上,BytePS 在 Resnet50 的表现较 Horovod(NCCL)提高 44%,在 VGG16 则提升了 100%。
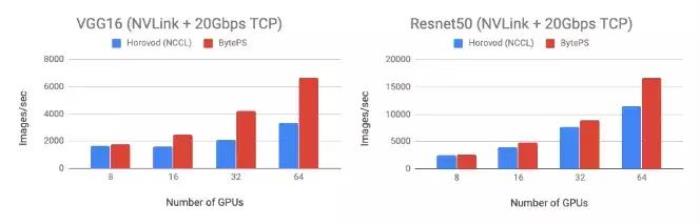
在 VGG16 和 Resnet50 模型上,BytePS 和 NCCL 的性能对比。
作者提供了 Docker 文件,帮助用户测试。
抛弃 MPI,迎接云计算
为什么 BytePS 的表现比 Horovod 好太多?主要原因是 BytePS 为云计算和共享集群设计,并抛弃了 MPI。
MPI 是高性能计算(High Performance Computing)的产物。当需要运行单一任务时,MPI 适合用于建立在同质化硬件的计算集群上。但是云计算(或者内部共享集群)是不一样的。
团队因此重新思考了最佳通信策略。总之,BytePS 不仅在机器内使用 NCCL,同时也重新部署了机器间的通信方式。
BytePS 同时继承了许多加速技术,如分级策略、管道、张量分割、NUMA-aware 本地通信、基于优先级的调度机制等。
快速上手
使用 BytePS 前,假设你已经安装了以下一种或更多框架:TensorFlow、Keras、PyTorch、MXNet 等。BytePS 基于 CUDA 和 NCCL。
复制 BytePS 和第三方依赖:
git clone --recurse-submodules https://github.com/bytedance/byteps
然后进入 BytePS 文件目录,并安装:
python setup.py install
注意:你可能需要设置 BYTEPS_USE_RDMA=1 来安装 RDMA 支持。
现在你可以试试一些例子。假设你使用 MXNet,并想尝试 ResNet50 的基本模型。
export NVIDIA_VISIBLE_DEVICES=0,1
DMLC_NUM_WORKER=1
DMLC_NUM_SERVER=1
DMLC_WORKER_ID=0
DMLC_ROLE=worker
DMLC_PS_ROOT_URI=10.0.0.1
DMLC_PS_ROOT_PORT=1234
DMLC_INTERFACE=eth0
python byteps/launcher/launch.py byteps/example/mxnet/train_imagenet_byteps.py --benchmark 1 --batch-size=32
对于分布式训练,你可能需要建立一个服务器镜像。团队提供了 Docker 文件作为例子。你可以使用同样的镜像用于调度和提供服务。
更多启动分布式任务和上手教程可参考:https://github.com/bytedance/byteps/tree/master/docs
在你的代码中使用 BytePS
BytePS 和 Horovod 接口高度兼容。选择 Horovod 可以降低测试工作量。
如果你的任务只依赖 Horovod 的 allreduce 和广播,你可以在一分钟内切换到 BytePS。
只需要用 import byteps.tensorflow as bps 替换 import horovod.tensorflow as hvd,并将代码中所有的 hvd 替换成 bps。
项目计划
BytePS 目前不支持单纯的 CPU 训练,一些底层逻辑可能不支持。你可以使用 CUDA 或 NCCL 来运行 BytePS。
BytePS 即将增加以下特性:
异步训练 容错机制 延迟减缓相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章