新火种
2023-10-29
新火种
2023-10-29 


巨大飞跃!给英伟达1.6万亿个晶体管,它就能承托全球互联网流量
英伟达(Nvidia)一年一度的GTC大会如期而至,两年一更新的GPU架构Hopper也正式亮相。
今年,NVIDIA创始人兼CEO黄仁勋在英伟达新总部大楼发布了一系列新品,从新架构GPU H100,到Grace CPU 超级芯片,再到汽车、边缘计算的硬件新品,以及全面的软件更新。
英伟达的全新发布再次向外界宣告,英伟达不止是一家芯片公司,而是全栈计算公司。他们正在加强其在AI、汽车等领域的领导力,同时也在努力占领下一波AI浪潮以及元宇宙的先机。
当然,作为一家发明GPU的公司,英伟达的全新GPU架构依旧是GTC 2022最值得关注的新品。
Nvidia Hopper新架构以美国计算机领域的先驱科学家 Grace Hopper 的名字命名,将取代两年前推出的 NVIDIA Ampere 架构。相比上一代产品,基于Hopper架构的H100 GPU实现了数量级的性能飞跃。

黄仁勋表示,20个 H100 GPU 便可承托相当于全球互联网的流量,使其能够帮助客户推出先进的推荐系统以及实时运行数据推理的大型语言模型。
基于H100 GPU构建的各种系统,以及与Grace CPU 超级芯片组合的各种系统,配合英伟达多年构建强大的软件生态,将成为了英伟达掀起新一代计算浪潮的能量。
H100 GPU将在今年第三季度出货,明年上半年开始供货Grace CPU超级芯片。
最新Hopper架构H100 GPU的6大突破
黄仁勋2020年从自家厨房端出的当时全球最大7nm芯片Ampere架构GPU A100,两年后有了继任者——Hopper架构H100。英伟达H100 GPU采用专为英伟达加速计算需求设计优化的TSMC 4N 工艺,集成800亿个晶体管,显著提升了AI、HPC、显存带宽、互连和通信的速度,并能够实现近 5TB/s 的外部互联带宽。

H100同时也集多个首个于一身,包括首款支持 PCIe 5.0 的 GPU,首款采用 HBM3 的 GPU,可实现 3TB/s 的显存带宽,全球首款具有机密计算功能的GPU。
H100的第二项突破就是其加速器的 Transformer 引擎能在不影响精度的情况下,将Transformer网络的速度提升至上一代的六倍。Transformer 让自监督学习成为可能,如今已成为自然语言处理的标准模型方案,也是深度学习模型领域最重要的模型之一。
H100的第三项突破是进一步升级的第二代多实例GPU。上一代产品中,英伟达的多实例GPU技术可将每个A100 GPU分割为七个独立实例来执行推理任务。新一代的Hopper H100与上一代产品相比,在云环境中通过为每个 GPU 实例提供安全的多租户配置,将 MIG 的部分能力扩展了 7 倍。
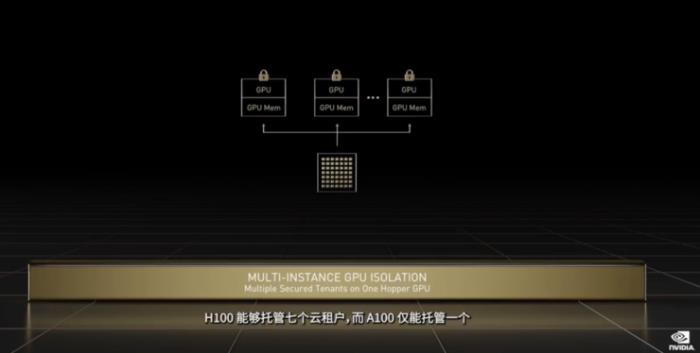
MIG 技术支持将单个 GPU 分为七个更小且完全独立的实例,以处理不同类型的任务。
H100的第四项突破就是其是全球首款具有机密计算功能的加速器,隐私计算此前只能在CPU上实现,H100是第一个实现隐私计算的GPU,可保护 AI 模型和正在处理的客户数据。机密计算的优势在于其不仅能确保数据的机密性,同时还不影响性能,可以应用于医疗健康和金融服务等隐私敏感型行业的联邦学习,也可以应用于共享云基础设施。
H100的第五项突破是在互联性能的提升,支持第4代 NVIDIA NVLink。如今的AI模型越来越大,带宽成为了限制超大规模AI模型迭代的阻碍。英伟达将NVLink 结合全新的外接 NVLink Switch,可将 NVLink 扩展为服务器间的互联网络,最多可以连接多达 256 个 H100 GPU,相较于上一代采用 NVIDIA HDR Quantum InfiniBand网络,带宽高出9倍。
这项突破可以带来的直接提升是,利用 H100 GPU,研究人员和开发者能够训练庞大的模型,比如包含3950亿个参数的混合专家模型,训练速度加速高达9倍,训练时间从几周缩短到几天。
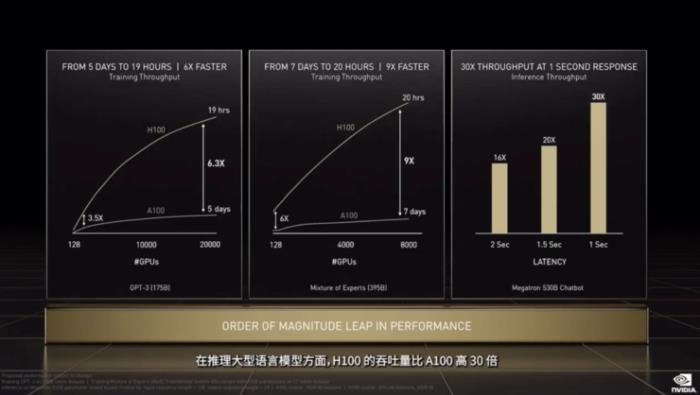
H100的第六个突破是对新的 DPX 指令可加速动态规划,适用于包括路径优化和基因组学在内的一系列算法,英伟达的测试数据显示,与 CPU 和上一代 GPU 相比,其速度提升分别可达 40 倍和 7 倍。
另外,Floyd-Warshall 算法与 Smith-Waterman 算法也在H100 DPX指令的加速之列,前者可以在动态仓库环境中为自主机器人车队寻找最优线路,后者可用于DNA和蛋白质分类与折叠的序列比对。
硬件突破之外,英伟达也发布了一系列相应的软件更新,包括用于语音、推荐系统和超大规模推理等工作负载的 NVIDIA AI 软件套件,还有60多个针对CUDA-X的一系列库、工具和技术的更新,能够加速量子计算和 6G 研究、网络安全、基因组学和药物研发等领域的研究进展。
显而易见,H100 GPU的六项突破,带来的是更高的计算性能,但这些性能的提升和优化,全都指向AI计算,这也是英伟达进一步扩大在AI计算领域领导力的体现。
NVIDIA Eos,比全球最快超级计算机AI性能快 4 倍
有了性能升级的GPU,英伟达的第四代DGX系统DGX H100也随之亮相,包括DGX POD和DGX SupePOD两种架构,能够满足大型语言模型、推荐系统、医疗健康研究和气候科学的大规模计算需求。


每个 DGX H100 系统配备八块 NVIDIA H100 GPU,并由 NVIDIA NVLink连接,能够在新的 FP8 精度下达到 32 Petaflop 的 AI 性能,比上一代系统性能高6倍。每个DGX H100 系统还包含两个NVIDIA BlueField-3 DPU,用于卸载、加速和隔离高级网络、存储及安全服务。
新的 DGX SuperPOD 架构采用全新的 NVIDIA NVLink Switch 系统,通过这一系统最多可连接32个节点,总计256块H100 GPU。第四代NVLink与NVSwitch相结合,能够在每个DGX H100系统中的各个GPU之间实现 900 GB/s 的连接速度,是上一代系统的 1.5 倍。
新一代DGX SuperPOD性能同样显著提升,能够提供1 Exaflops的FP8 AI性能,比上一代产品性能高6倍,能够运行具有数万亿参数的庞大LLM工作负载,有助于推动气候科学、数字生物学和 AI 未来的发展。
基于DGX H100,英伟达将在今年晚些时候开始运行全球运行速度最快的 AI 超级计算机 —— NVIDIA Eos,“Eos"超级计算机共配备 576 台 DGX H100 系统,共计 4608 块 DGX H100 GPU,预计将提供 18.4 Exaflops 的 AI 计算性能,比日本的Fugaku(富岳)超级计算机快 4 倍,后者是目前运行速度最快的系统。
在传统的科学计算方面,Eos 超级计算机预计将提供 275 Petaflop 的性能。

黄仁勋说:“对于 NVIDIA 及OEM 和云计算合作伙伴,Eos 将成为先进 AI 基础设施的蓝图。”
576个DGX H100系统能够构建一台全球运行速度最快的AI系统,少量的DGX SuperPOD 单元组合,也可以为汽车、医疗健康、制造、通信、零售等行业提供开发大型模型所需的 AI 性能。
黄仁勋提到,为支持正在进行AI开发的DGX客户,NVIDIA DGX-Ready软件合作伙伴(包括Domino Data Lab、Run:ai和Weights & Biases等)提供的MLOps解决方案将加入"NVIDIA AI 加速"计划。
为了简化AI部署,英伟达还推出了DGX-Ready 托管服务计划,能够为希望与服务提供商开展合作来监督其基础设施的客户提供支持。通过新的 DGX-Ready 生命周期管理计划,客户还可以借助新的 NVIDIA DGX 平台升级其现有 DGX 系统。
Grace CPU 超级芯片,最强大的CPU
去年的GTC 21,英伟达首款数据中心CPU Grace亮相,英伟达的芯片路线也升级为GPU+DPU+CPU。
今年的GTC 22,英伟达由推出了首款面向 AI 基础设施和高性能计算的基于Arm Neoverse的数据中心专属CPU Grace CPU 超级芯片。

Grace CPU 超级芯片是专为AI、HPC、云计算和超大规模应用而设计,能够在单个插座(socket)中容纳 144 个 Arm 核心,在 SPECrate 2017_int_base 基准测试中的模拟性能达到业界领先的 740 分。根据 NVIDIA 实验室使用同类编译器估算,这一结果较当前DGX A100搭载的双CPU(AMD EPYC 7742)相比高 1.5 倍以上。
黄仁勋称赞:“Garce的一切都令人惊叹,我们预计Grace超级芯片届时将是最强大的CPU,是尚未发布的第5代顶级CPU的2到3倍。”
据介绍,依托带有纠错码的LPDDR5x 内存组成的创新的内存子系统,Grace CPU 超级芯片可实现速度和功耗的最佳平衡。LPDDR5x 内存子系统提供两倍于传统DDR5设计的带宽,可达到1 TB/s ,同时功耗也大幅降低 ,CPU加内存整体功耗仅500瓦。
值得注意的是,Grace CPU超级芯片由两个CPU芯片组成,通过NVLink-C2C互连在一起。NVLink-C2C 是一种新型的高速、低延迟、芯片到芯片的互连技术,将支持定制裸片与NVIDIA GPU、CPU、DPU、NIC 和 SOC 之间实现一致的互连。
借助先进的封装技术,NVIDIA NVLink-C2C 互连链路的能效最多可比NVIDIA芯片上的PCIe Gen 5高出25倍,面积效率高出90倍,可实现每秒900GB乃至更高的一致互联带宽。
得益于Grace CPU 超级芯片可以运行所有的英伟达计算软件栈,包括NVIDIA RTX、NVIDIA HPC、NVIDIA AI 和 Omniverse。Grace CPU超级芯片结合NVIDIA ConnectX-7 网卡,能够灵活地配置到服务器中,可以作为独立的纯CPU系统,或作为GPU加速服务器,搭载一块、两块、四块或八块基于Hopper的GPU,客户通过维护一套软件栈就能针对自身特定的工作负载做好性能优化。

今日发布的NVIDIA Grace超级芯片系列以及去年发布的Grace Hopper超级芯片均采用了NVIDIA NVLink-C2C 技术来连接处理器芯片。
英伟达表示,除NVLink-C2C外,NVIDIA还将支持本月早些时候发布的 UCIe(Universal Chiplet Interconnect Express,通用小芯片互连传输通道)标准。与NVIDIA芯片的定制芯片集成既可以使用 UCIe 标准,也可以使用 NVLink-C2C。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章