新火种
2023-10-28
新火种
2023-10-28 


GPU暴增的GenAI时代,AMD正跨越英伟达的CUDA软件护城河
在生成式 AI 时代,GPU 的重要性毋庸置疑。英伟达与 AMD 这两个重量级选手正在硬件、软件层面展开激烈角逐。
如今,当人们谈论起生成式 AI(GenAI)时,GPU 以及相应的性能和访问性几乎是绕不过的话题。而英伟达又是 GPU 的代名词,在国际 GPU 市场上占据绝对优势的份额。同时,近年来 AMD 也逐渐崛起,占有了一定市场份额。
不过,AMD 与英伟达仍存在较大差距。此前市场调研机构 Jon Peddie Research 发布的 2022 年 GPU 市场数据统计报告显示,英伟达 PC GPU 出货量高达 3034 万块,是 AMD 的近 4.5 倍。
就英伟达而言,其 GPU 与生成式 AI 的紧密联系绝非偶然。一直以来,英伟达认识到需要利用工具和应用来帮助扩展自己的市场。因此,英伟达为人们获取自身硬件设置了非常低的门槛,包括 CUDA 工具包和 cuDNN 优化库等。
在被称为硬件公司之外,正如英伟达应用深度学习研究副总裁 Bryan Catanzaro 所言,「很多人不知道的一点是,英伟达的软件工程师比硬件工程师还要多。」
可以说,英伟达围绕其硬件构建了强大的软件护城河。虽然 CUDA 不开源,但免费提供,并处于英伟达的严格控制之下。英伟达从中受益,但也给那些希望通过开发替代硬件抢占 HPC 和生成式 AI 市场的公司和用户带来了挑战。
「城堡地基」上的建筑
我们知道,为生成式 AI 开发的基础模型数量持续增长,其中很多是开源的,可以自由使用和共享,如 Meta 的 Llama 系列大模型。这些模型需要大量资源(如人力和机器)来构建,并且局限于拥有大量 GPU 的超大规模企业,比如 AWS、微软 Azure、Google Cloud、Meta Platforms 等。此外其他公司也购买大量 GPU 来构建自己的基础模型。
从研究的角度来看,这些模型很有趣,可以用于各种任务。但是,对更多生成式 AI 计算资源的预期使用和需求越来越大,比如模型微调和推理,前者将特定领域的数据添加到基础模型中,使之适合自己的用例;后者在微调后,实际使用(即问问题)需要消耗资源。
这些任务需要加速计算的参与,即 GPU。显而易见的解决方案是购买更多的英伟达 GPU。但随着供不应求,AMD 迎来了很好的机会。英特尔和其他一些公司也准备好进入这一市场。随着微调和推理变得更加普遍,生成式 AI 将继续挤压 GPU 的可用性,这时使用任何 GPU(或加速器)都比没有 GPU 好。
放弃英伟达硬件意味着其他供应商的 GPU 和加速器必须支持 CUDA 才能运行很多模型和工具。AMD 通过 HIP(类 CUDA)转换工具使这一情况成为可能。
PyTorch 放下软件护城河「吊桥」
在 HPC 领域,支持 CUDA 的应用程序统治着 GPU 加速的世界。使用 GPU 和 CUDA 时,移植代码通常可以实现 5-6 倍的加速。但在生成式 AI 中,情况却截然不同。
最开始,TensorFlow 是使用 GPU 创建 AI 应用的首选工具,它既可以与 CPU 配合使用,也能够通过 CUDA 实现加速。不过,这一情况正在快速发生改变。
PyTorch 成为了 TensorFlow 的强有力替代品,作为一个开源机器学习库,它主要用于开发和训练基于神经网络的深度学习模型。
最近 AssemblyAI 的一位开发者 educator Ryan O’Connor 在一篇博客中指出,在流行的 HuggingFace 网站上,92% 的可用模型都是 PyTorch 独有的。
此外如下图所示,机器学习论文的比较也显示出放弃 TensorFlow、转投 PyTorch 的显著趋势。
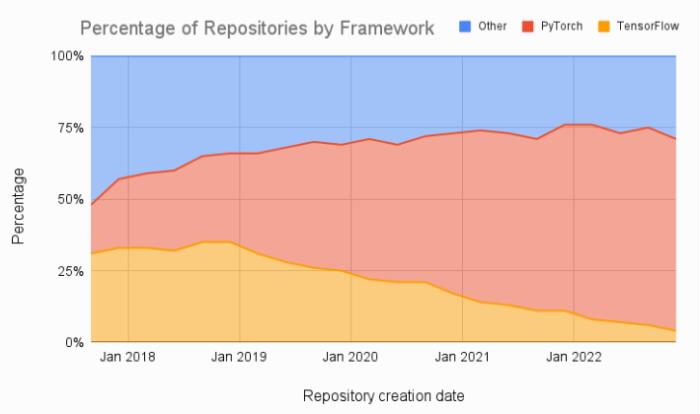
当然,PyTorch 底层对 CUDA 进行调用,但不是必需的,这是因为 PyTorch 将用户与底层 GPU 架构隔离开来。AMD 还有一个使用 AMD ROCm 的 PyTorch 版本,它是一个用于 AMD GPU 编程的开源软件堆栈。
现在,对于 AMD GPU 而言,跨越 CUDA 护城河就像使用 PyTorch 一样简单。
推理的本能
在 HPC 和生成式 AI 中,配有 H100 GPU 共享内存的英伟达 72 核、且基于 ARM 的 Grace-Hopper 超级芯片(以及 144 核 Grace-Grace 版本)备受期待。
迄今,英伟达发布的所有基准测试表明,该芯片的性能比通过 PCIe 总线连接和访问 GPU 的传统服务器要好得多。Grace-Hopper 是面向 HPC 和生成式 AI 的优化硬件,有望在微调和推理方面得到广泛应用,需求预计会很高。
而 AMD 从 2006 年(于当年收购了显卡公司 ATI)就已经出现了带有共享内存的 CPU-GPU 设计。从 Fusion 品牌开始,很多 AMD x86_64 处理器都作为 APU(加速处理单元)的组合 CPU/GPU 来实现。
AMD 推出的 Instinct MI300A 处理器(APU)将与英伟达的 Grace-Hopper 超级芯片展开竞争。集成的 MI300A 处理器将最多提供 24 个 Zen4 核心,并结合 CDNA 3 GPU 架构和最多 192GB 的 HBM3 内存,为所有 CPU 和 GPU 核心提供了统一的访问内存。
可以说,芯片级缓存一致性内存减少了 CPU 和 GPU 之间的数据移动,消除了 PCIe 总线瓶颈,提升了性能和能效。
 苏姿丰
苏姿丰
AMD 正在为模型推理市场准备 MI300A 处理器。如 AMD CEO 苏姿丰所言,「实际上,得益于架构上的一些选择,我们认为自己将成为推理解决方案的行业领导者。」
对于 AMD 和很多其他硬件供应商而言,PyTorch 已经在围绕基础模型的 CUDA 护城河上放下了吊桥。AMD 的 Instinct MI300A 处理器将打头阵。
生成式 AI 市场的硬件之战将凭借性能、可移植性和可用性等多因素来取胜。未来鹿死谁手,尚未可知。
原文链接:https://www.hpcwire.com/2023/10/05/how-amd-may-get-across-the-cuda-moat/
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。