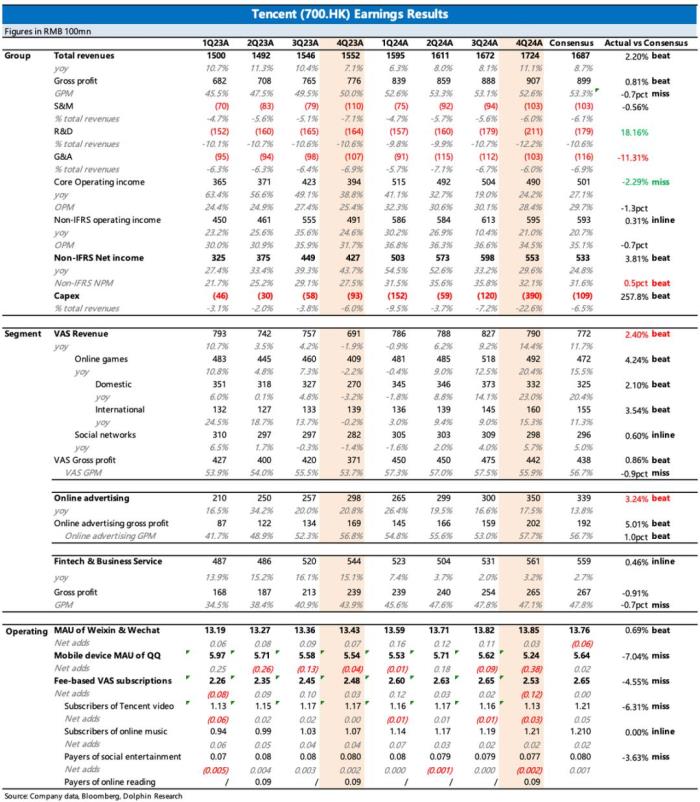
新火种
2023-10-25
新火种
2023-10-25 


综合LSTM、transformer,DeepMind强化学习智能体提高数据效率
选自arXiv
作者:Andrea Banino等
机器之心编译
编辑:陈萍、杜伟

来自 DeepMind 的研究者提出了用于强化学习的 CoBERL 智能体,它结合了新的对比损失以及混合 LSTM-transformer 架构,可以提高处理数据效率。实验表明,CoBERL 在整个 Atari 套件、一组控制任务和具有挑战性的 3D 环境中可以不断提高性能。
近些年,多智能体强化学习取得了突破性进展,例如 DeepMind 开发的 AlphaStar 在星际争霸 II 中击败了职业星际玩家,超过了 99.8% 的人类玩家;OpenAI Five 在 DOTA2 中多次击败世界冠军队伍,是首个在电子竞技比赛中击败冠军的人工智能系统。然而,许多强化学习(RL)智能体需要大量的实验才能解决任务。
最近,DeepMind 的研究者提出了 CoBERL(Contrastive BERT for RL)智能体,它结合了新的对比损失和混合 LSTM-transformer 架构,以提高处理数据效率。CoBERL 使得从更广泛领域使用像素级信息进行高效、稳健学习成为可能。
具体地,研究者使用双向掩码预测,并且结合最近的对比方法泛化,来学习 RL 中 transformer 更好的表征,而这一过程不需要手动进行数据扩充。实验表明,CoBERL 在整个 Atari 套件、一组控制任务和具有挑战性的 3D 环境中可以不断提高性能。

论文地址:/uploads/pic/20231025/pp.pdf style="box-sizing: border-box;margin: 20px 0px;padding: 0px;border: 0px;text-align: left" data-from-paste="1">方法介绍
为了解决深度强化学习中的数据效率问题,研究者对目前的研究提出了两种修改:
首先提出了一种新的表征学习目标,旨在通过增强掩码输入预测中的自注意力一致性来学习更好的表征;
其次提出了一种架构改进,该架构可以结合 LSTM 以及 transformer 的优势。
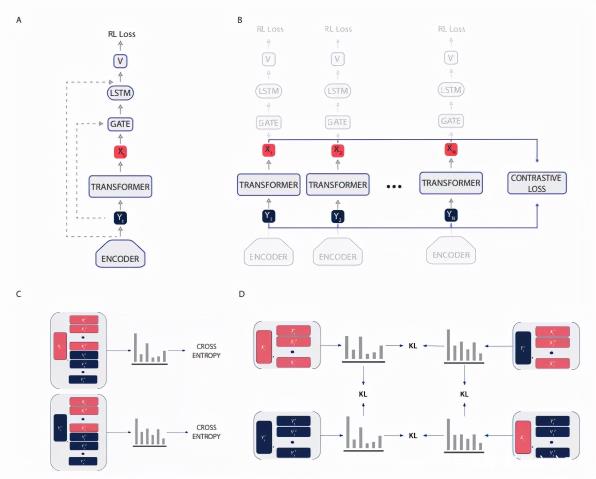
CoBERL 整体架构图。
表征学习
研究者将 BERT 与对比学习结合起来。基于 BERT 方法,该研究将 transformer 的双向处理机制与掩码预测设置相结合。双向处理机制一方面允许智能体根据时间环境来了解特定状态的上下文。另一方面,位于掩码位置处的预测输入通过降低预测后续时间步长的概率来缓解相关输入问题。
研究者还使用了对比学习,虽然许多对比损失(例如 SimCLR)依赖于数据扩充来创建可以进行比较的数据分组,但该研究不需要利用这些手工数据扩充来构造代理任务。
相反地,该研究依赖输入数据的顺序性质来创建对比学习所需的相似和不同点的必要分组,不需要仅依赖图像观测的数据增强(如裁剪和像素变化)。对于对比损失,研究者使用了 RELIC,该损失同样适应于时间域;他们通过对齐 GTrXL transformer 输入和输出创建数据分组,并且使用 RELIC 作为 KL 正则化改进所用方法的性能,例如 SimCLR 在图像分类领域以及 Atari 在 RL 领域性能都得到提高。
CoBERL 架构
在自然语言处理和计算机视觉任务当中,transformer 在连接长范围数据依赖性方面非常有效,但在 RL 设置中,transformer 难以训练并且容易过拟合。相反,LSTM 在 RL 中已经被证明非常有用。尽管 LSTM 不能很好地捕获长范围的依赖关系,但却可以高效地捕获短范围的依赖关系。
该研究提出了一个简单但强大的架构改变:在 GTrXL 顶部添加了一个 LSTM 层,同时在 LSTM 和 GTrXL 之间有一个额外的门控残差连接,由 GTrXL 的输入进行调制。此外,该架构还有一个包含从 transformer 输入到 LSTM 输出的跳跃连接。更具体地说,Y_t 在时间 t 时编码器网络的输出,可以用下列方程定义附加模块:
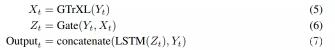
这些模块是互补的,因为 transformer 没有最近偏差,而 LSTM 的偏差可以表示最近的输入——等式 6 中的 Gate 允许编码器表征和 transformer 输出混合。这种内存架构与 RL 机制的选择无关,研究者在开启和关闭策略(on and off-policy)设置中评估了这种架构。对于 on-policy 设置,该研究使用 V-MPO 作为 RL 算法。V-MPO 使用目标分布进行策略更新,并在 KL 约束下将参数部分移向该目标。对于 off-policy 设置,研究者使用 R2D2。
R2D2 智能体:R2D2(Recurrent Replay Distributed DQN) 演示了如何调整 replay 和 RL 学习目标,以适用于具有循环架构的智能体。鉴于其在 Atari-57 和 DMLab-30 上的竞争性能,研究者在 R2D2 的背景下实现了 CoBERL 架构。他们用门控 transformer 和 LSTM 组合有效地替换了 LSTM,并添加了对比表示学习损失。因此,通过 R2D2,以及分布式经验收集的益处,将循环智能体状态存储在 replay buffer 中,并在训练期间「烧入」(burning in)具有 replay 序列展开网络的一部分。
V-MPO 智能体:鉴于 V-MPO 在 DMLab-30 上的强大性能,特别是与作为 CoBERL 关键组件的 GTrXL 架构相结合,该研究使用 V-MPO 和 DMLab30 来演示 CoBERL 与 on-policy 算法的使用。V-MPO 是一种基于最大后验概率策略优化(MPO)的 on-policy 自适应算法。为了避免策略梯度方法中经常出现的高方差,V-MPO 使用目标分布进行策略更新,受基于样本的 KL 约束,计算梯度将参数部分移向目标,这样也同样受 KL 约束。与 MPO 不同,V-MPO 使用可学习的状态 - 价值函数 V(s) 而不是状态 - 动作价值函数。
实验细节
研究者证明了 1) CoBERL 在更为广泛的环境和任务中能够提高性能,2)最大化性能还需要所有组件。实验展示了 CoBERL 在 Atari57 、DeepMind Control Suite 和 DMLab-30 中的性能。
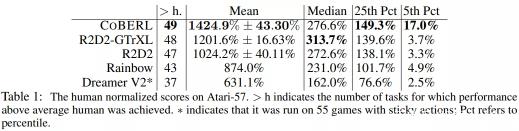
下表 1 为目前可获得的不同智能体的结果。由结果可得,CoBERL 在大多数游戏中的表现高于人类平均水平,并且显著高于同类算法平均性能。R2D2-GTrXL 的中值(median)略优于 CoBERL,表明 R2D2-GTrXL 确实是 Atari 上的强大变体。研究者还观察到在检查「25th Pct 以及 5th Pct」时 ,CoBERL 的性能和其他算法的差异更大, 这表明 CoBERL 提高了数据效率。
为了在具有挑战性的 3D 环境中测试 CoBERL,该研究在 DmLab30 中运行,如下图 2 所示:

下表 3 的结果表明与没有对比损失的 CoBERL 相比,对比损失可以显著提高 Atari 和 DMLab-30 的性能。此外,在 DmLab-30 这样具有挑战性的环境中,没有额外损失的 CoBERL 仍然优于基线方法。
下表 4 为该研究提出的对比损失与 SimCLR、CURL 之间的比较:结果表明该对比损失虽然比 SimCLR、CURL 简单,但性能更好。
下表 5 为从 CoBERL 中删除 LSTM 的效果(如 w/o LSTM 一列),以及移除门控及其相关的跳跃连接(如 w/o Gate 一列)。在这两种情况下 CoBERL 的性能都要差很多,这表明 CoBERL 需要这两个组件(LSTM 和 Gate)。
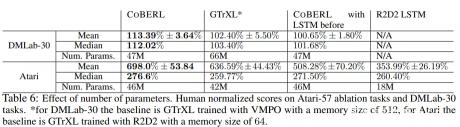
下表 6 根据参数的数量对模型进行了比较。对于 Atari,CoBERL 在 R2D2(GTrXL) 基线上添加的参数数量有限;然而,CoBERL 仍然在性能上产生了显着的提升。该研究还试图将 LSTM 移到 transformer 模块之前,在这种情况下,对比损失表征取自 LSTM 之前。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。