新火种
2025-04-08
新火种
2025-04-08 

MetaLlama4被疑考试「作弊」:在竞技场刷高分,但实战中频频翻车
Meta 翻车来得猝不及防。
上周六,Meta 发布了最新 AI 模型系列 ——Llama 4,并一口气出了三个款,分别是 Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth。
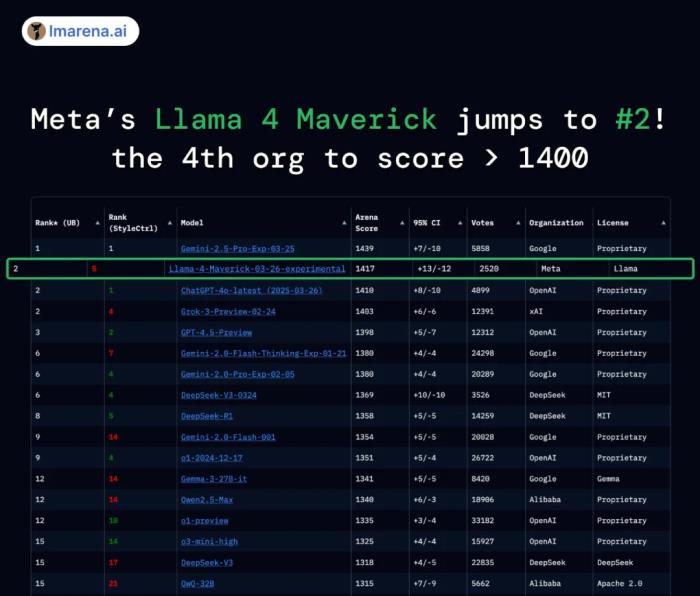
据官方介绍,在大模型竞技场中,它们的排名相当不赖。
就拿 Llama 4 Maverick 来说,总排名第二,成为第四个突破 1400 分的大模型。其中开放模型排名第一,超越了 DeepSeek;在困难提示词、编程、数学、创意写作等任务中排名均为第一。
然而,不少网友体验后反馈,Llama 4 似乎是一个糟糕的编码模型。
@deedydas 发帖称,Llama 4 Scout(109B)和 Maverick(402B)在 Kscores 基准测试中表现不佳,不如 GPT-4o、Gemini Flash、Grok 3、DeepSeek V3 以及 Sonnet 3.5/7 等模型。而 Kscores 基准测试专注于编程任务,例如代码生成和代码补全。
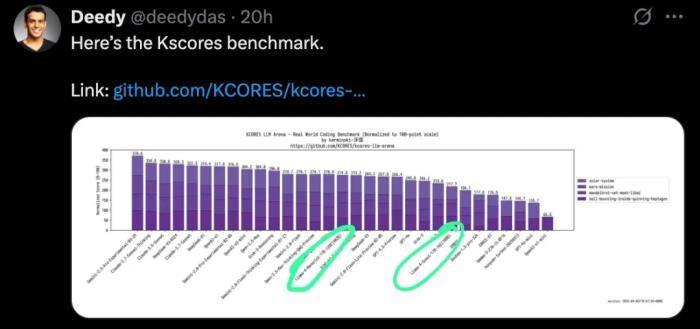
比如小球在旋转六边形中跳跃的测试中,Llama 4 的表现并不理想。
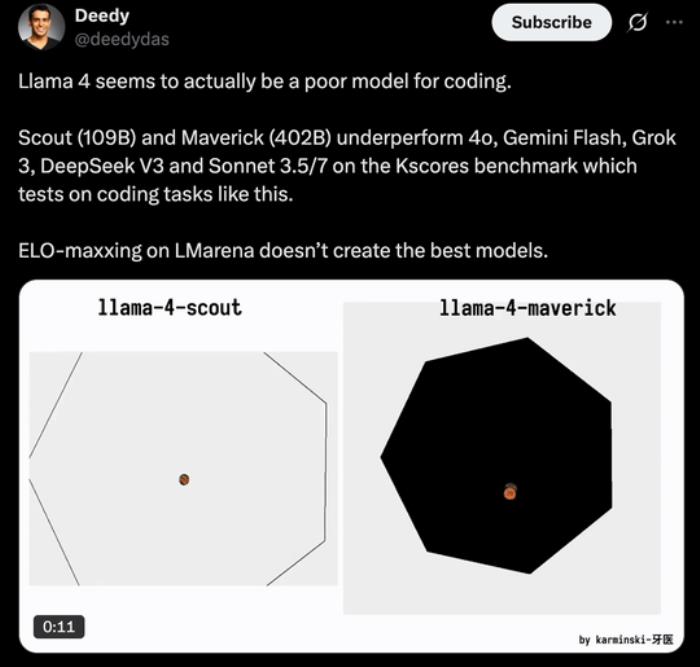
底下评论区的网友也纷纷表示,无论是 Scout 还是 Maverick,在实际编程中好像都不好用,即使有详细的提示也不行。

还有网友在 Novita AI 平台上测试了该模型,给出的结论是在复杂问题上有点吃力,但响应速度很快。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章