新火种
2025-03-07
新火种
2025-03-07 


腾讯混元发布并开源图生视频模型:让照片开口说话唱歌AI神器
3月6日消息,今日,腾讯混元宣布发布图生视频模型并对外开源,同时上线对口型与动作驱动等玩法,并支持生成背景音效及2K高质量视频。
企业和开发者可在腾讯云申请使用API接口,用户通过混元AI视频官网即可体验。
开源内容包含权重、推理代码和LoRA训练代码,支持开发者基于混元训练专属LoRA等衍生模型,目前在Github、HuggingFace等主流开发者社区均可下载体验。
据介绍,基于图生视频的能力,用户只需上传一张图片,并简短描述希望画面如何运动、镜头如何调度等,混元即可按要求让图片动起来,变成5秒的短视频,还能自动配上背景音效。

此外,上传一张人物图片,并输入希望“对口型”的文字或音频,图片中的人物即可“说话”或“唱歌”;使用“动作驱动”能力,还能一键生成同款跳舞视频。
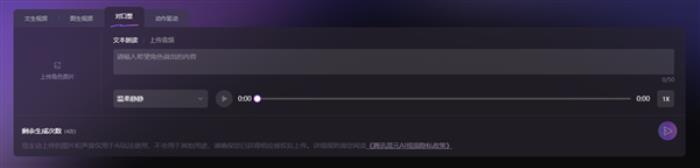
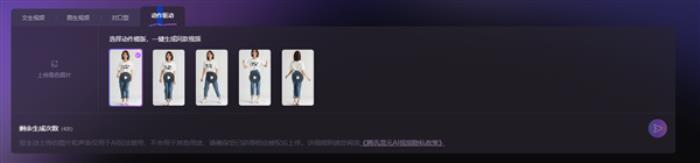
腾讯混元表示,此次开源的图生视频模型,是混元文生视频模型开源工作的延续,模型总参数量保持 130 亿,模型适用于多种类型的角色和场景,包括写实视频制作、动漫角色甚至CGI角色制作的生成。

相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章