

 新火种
2024-02-27
新火种
2024-02-27 

从Sora的发展史,聊聊设计师如何面对AI焦虑
经过春节小休整,很多朋友都鼓起信心重新出发,因为吉祥话听多了还是会受用,没想到返岗途中还没来得及跟大家道句开工大吉,资讯话题就被Sora的发布信息填满。
Sora的发布让人感叹科幻电影都不敢这样拍,而且很多权威平台都认为奥特曼的大招还没亮出来,几句话做60秒视频只是前戏,先吊吊大家胃口,为他后面融资铺垫。

此图最近已经符号化了
Sora这个名字据说来自日文中的“空”(そら sora),象征“无限创造力”,众所周知,空也是佛家用语,以我的无知只能找来《道德经》的“无”来应战,无中生有,有生于无,意味深长。
关于最新科技无论在公在私大家都应该了解,不然酒局时候无法插嘴,于是我在网上找来一些资讯,普遍说得学术晦涩,都不太满意,所以按照惯例,决定自己写一篇。
此文希望通俗一点跟大家谈一下Sora,包括它的诞生过程,背后团队,技术原理,五大绝招,三大局限,及面对AI冲击时候,设计行业的一点思考。
一、Sora如何诞生?在AI绘画发展得如火如荼的时候,探索AI生成视频是不少公司都在攻克的课题,比如Meta公司的Make-A-Video,Runway的 Gen-2 和Google的 Lumiere等等。
这些公司及其相关模型已经在2023年取得阶段性成果,其中“跑路公司”(Runway)托名字的福,果然相对领跑,它生成的AI视频具有画面清晰,精美度强,能影视运镜等特征,而且最新版本已经能生成4k画质,但时长只有4-16秒。

Runway的Gen-2
你大爷还是你大爷,Openai作为人工智能领域的头牌阿姑,不鸣则已一鸣惊人,在2024年2月16日发布的Sora除了视频生成时长达到60秒之外,还在语义理解,画面表现,细节完善度等方面秒杀全部同学。
而且Sora居然能理解物体在物理世界的存在,并且可以应对复杂场景的变化等等。

关于Sora的牛已经不需要我在本文章里夸,但我想指出一点,就是官方视频就像卖家详情,到了买家手上还是会有变化,就如同你买的车永远开不出厂家标注的油耗一样。
当然更多发布细节其实我并不了解,但根据过去认识,类似发布一般不会现场给你演示,所以就对了。
而关于Sora的诞生历程与细节自然不为外界所知,只有项目负责人及Openai才有发言权,所以这里只能扒一下几位核心成员背景,及谈谈Sora的技术基本原理。
Sora整个团队仅仅合计13人,而核心成员只有三位,而且都非常年轻。
分别是负责研发的蒂姆·布鲁克斯(Tim Brooks)、比尔·皮布尔斯(Bill Peebles)、及负责系统的康纳·福尔摩斯(Connor Holmes)。
布鲁克斯是2023年在加州大学伯克利分校的博士,一看“出厂年份”真的年纪不大。

蒂姆·布鲁克斯
去加州大学之前,布鲁克斯其实先在谷歌的智能手机“Pixel”部门工作了两年,主要研究AI相机,而他的本科就读于卡内基梅隆大学,主修逻辑与计算,辅修计算机科学,实习期间则在 Facebook的软件工程部门,为期四个月。
在谷歌工作的布鲁克斯也许对自己期许更大,就选择了到加州大学的“伯克利人工智能研究所”攻读博士,主要研究方向就是图片与视频生成。
第二位核心人物皮布尔斯跟布鲁克斯是同学,两人都师从一位导师,同样在2023年博士毕业,而皮布尔斯的本科就读于麻省,也是主修计算机科学。

比尔·皮布尔斯
皮布尔斯曾经在英伟达(美国电脑处理器知名公司)的深度自动驾驶团队实习,研究计算机视觉。
而最后一位核心人物,Sora系统的负责人福尔摩斯则毕业于科罗拉多矿业大学,本科主修电气电子工程、博士阶段主攻高性能计算,他曾在微软工作,因为跟Openai有项目合作被外派,于是顺理成章的被挖走。

康纳·福尔摩斯
以上三人的履历起码让大家清楚,开发Sora是一群拥有什么技能的人才,据说面对AI的高速迭代发展,团队13人在一年时间里都持续加班,睡眠时间极少,可见年轻就是好。

Openai的办公室
二、Sora的技术原理Sora的技术原理如果细说大部分人都不知所云,因为太多专业名词,要搞懂A先得弄懂B,弄懂B则需要了解C,大家现在连咒语都还编不好,所以不能太勉强,这里以最有效通俗的类比法讲述一下:
AI人工智能技术首先必须有一个输入端,可以理解为吃东西,各种AI模型就像中国山海经里的饕餮,怎么都吃不饱,当然吃东西也要成本,这是第一个重点。
Sora在输入时候主要吃视频跟图片,它吃的方式比较特别,也是核心技术,就是能将一个鸡腿从三维拍扁为二维,sora称为“视频压缩网络”,就是降维处理,所以不管什么东西被它拍扁之后就格式统一了,而且便于储存。
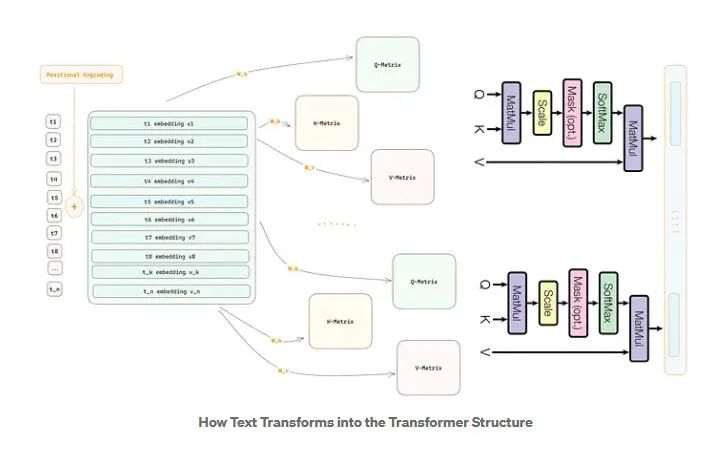
吃完就要消化分解了,这是Sora另一个核心技术,叫“空间时间补丁”(Spacetime Patches),就等于将吃进去的鸡腿分成鸡皮,鸡肉,跟鸡骨头等等,所以不管这是一个母鸡,火鸡还是小鸡的腿,分解之后格式又一致了,分别是皮、肉、骨。
当然它不止吃鸡腿,什么牛肉、胡萝卜、馒头等世间万物都吃,比如大山,大河,建筑物,如同视频中有动物主题也有风景主题等,然后都以同样技术拍扁消化,再归类储存。
好了,现在有人通过关键词伸手跟它要一个主题为“一个像胡萝卜的鸡腿在大海里裸泳”的视频,它就从自己的素材库里拼拼凑凑,生成这样一个视频出来。
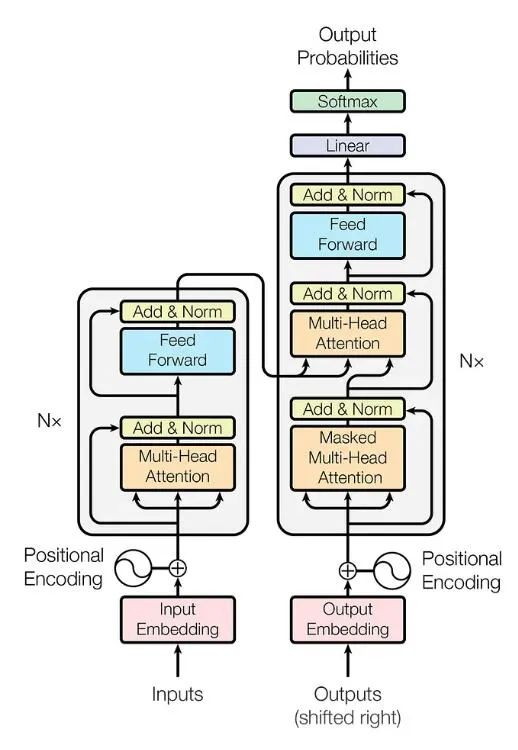
所以拆解下来如果不讲技术细节,其实逻辑跟AI绘画差不多,过去我也写过一篇《最易读懂的AI绘画发展史》,大家也可以去挖坟回顾。
因此Sora除了有自己的独门技术之外,就是每个部分都做得比对手好,整体效果出来自然就好了。
过去我经常跟朋友说好车的区别就是每个部分做得好一些,比如空调好一点,轮胎好一点,皮革好一点,豪华感就来了,都是四个轮子扛着沙发,但10万就变100万。
三、Sora的五大绝招至于横空出世就名震江湖的Sora有什么绝招呢,大致有以下5点:
1. 准确及多样:
Sora可以准确解释用户的文本输入,并生高品质视频,不管人物动物或者风景建筑,并且据说Sora能够准确解释长达135个单词这么长的提示。
2. 语言理解能力强:
Sora能利用Dall·E模型的“重述要点”技术,生成视觉训练数据的描述性字幕,除了能提高文本准确性,还能提升视频整体质量,意思是它已经懂你要干啥,但你说得太烂,它帮你再说一次。

3. 强大扩展功能:
Sora可以接受多样化的语言提示,用户还可以根据图像创建视频或者补充现有视频,并且还能沿时间线向前后扩展视频,我们脑补一下AI绘画中的补图功能就好理解了,比如一段视频里有只猫从楼下跳下来就没了,我们可以输入“猫跳下来后变身奥特曼”之类,猫就不能退出剧组,变身奥特曼继续出演。
4. 卓越的设备适配:
Sora具备出色的采样能力,从宽屏 1920*1080p 到 竖 屏 1080*1920的任何视频尺寸都能轻松搞定。
5. 场景和物体的一致和连续:
Sora可以生成带有动态视角变化的视频,人物和场景元素在三维空间中的移动变化显得更加自然,而且还能很好的处理遮挡问题,比如那只猫往下掉又还没变身奥特曼之前被招牌挡住了一下,再出现时候还是那只猫。
四、Sora的三大局限给人介绍对象都不能只谈优点,所以Sora的局限性我们也要客观提出来,主要有三点:
1. 物理交互的模拟不够准确:
Sora模型在模拟一些物理变化的时候不够准确,比如玻璃破碎,这可能因为模型在训练数据中(“吃东西”)时候缺乏足够的类似食物,或者sora还无法充分理解这些变化过程的底层原理。
2. 对象状态变化不正确:
Sora在模拟如吃食物这一类场景的时候,存在无法始终正确反映变化的情况,比如一根香蕉吃到最后居然比吃第一口时候还长之类。
3. 长时视频样本还不够连贯:
Sora在生成长时间的视频时,可能会产生出不连贯的情节或者细节,而且视频中可能会出现对象无缘无故弹出来,表明Sora在空间和时间连续性的理解上还有待提高。

这个Demo的狗就忽隐忽现
当然,我们前面谈过,奥特曼可能留了一手,等Sora正式推出的时候,这些问题也许就不存在了,又或者早有完善版本,就是等你们先讨论一下。
五、面对AI,我们该怎么办?Sora发布的那天我刚好回到深圳公司,当时在互联网各种气氛的烘托下,我还真的抑郁了一下,想着AI绘画还没完全学好,又来了个Sora。
但晚点就想通,想通原因是目前公司其实还有插画师,工作中并没有真的如同之前恐慌那样砍掉了插画师角色。
所以针对大家的“AI焦虑症”,我有三个观点:
其一观点关于“竞合关系”,历史上任何一次技术大变革,都会让新型技术跟现有技术产生竞合关系,就是竞争与合作,从而产生出新的工作岗位。
以AI绘画为例子,自从AI绘画诞生起码有三种新型工作随之诞生,比如AI培训。
然后是一些过去根本不会绘画的人通过AI技术可以完成一些简单绘画而提供服务,比如今天刷到一位号称外卖员转行过来的制图员,一张图几十元,第一次订单就承接了4000张,开始专门从事这个行业,然后走上致富之路,当然我想不通是什么样的客户.
但确实有些朋友可以为一些低端需求提供AI绘图服务,比如生成头像或者产品图之类,我们当前一个客户的模特图就找了AI公司进行生成。
还有一种就是用AI做自媒体,比如调戏AI,通过一些搞怪想法让AI生成一些极具娱乐性的画面赚取流量,这个时代流量就是货币,所以可以变现盈利。

调戏AI
因此以上三者都确实是因为AI绘画的诞生而产生的新工作,欢迎大家补充举例。
第二个观点关于“傻瓜与专业”,就是如果AI技术的使用足够傻瓜,那么最后会成为类似美图秀秀或者剪映这样的大众工具,最后只是看谁用得好,所以威胁是会化解的。
而假设AI技术足够专业又会形成门槛,比如AI绘画也有专业流,比如能进一步修改,通过平面生成三维,线稿进行上色,让一个形象连续生成等,一般人其实学不到这个层面,所以又会成为一个专业领域,好比写散文大家都在高中学过,不表示每个人都能成为散文高手,所以威胁又消解了。
第三个观点关于“完美与自然”,就目前来看,无论AI绘画或者生成视频,其痕迹感是很强的,这种痕迹就是一种风格局限,但市场需求永远是多元的。
前些天周鸿祎在视频里谈他家音响,说到音乐中最打动他的其实是一些来自人的细节,比如乐手演奏时候的用力深浅,情绪变化,甚至是一些喘息的声音等,而这些自然细节就目前来看(以后不知道)正是AI的弱项。
比如之前不少主播其实是使用了数字人进行视频制作,但不久后很多人又切换为真人录制,因为现实生活着没人受得了身边人都跟央视主播一样说话,不完美有时候才足够自然真实,而自然真实才更能打动人。
所以不管如何,大家面对的事实都会一样,不会因为你的过分紧张而改变世界运用的方式与进度,我们应该拥抱变化,但无需过度焦虑,作茧自缚。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
