

 新火种
2023-09-07
新火种
2023-09-07 


元学习热度不再!ICLR2022投稿趋势:强化学习榜首,深度学习第二
来源:GitHub
编辑:LRS
【新智元导读】ICLR 2022 论文投稿情况都是公开的,所以有研究者收集统计了ICLR 2022的3400篇论文,排出了前50个热门研究话题,发现深度学习、强化学习仍旧霸榜前两名,元学习的热度下降很多!
最近GitHub上一个项目ICLR2022-OpenReviewData爬取了ICLR 2022的所有投稿论文。
总共有3407篇,通过分析发现热度前50的投稿关键词中,强化学习、深度学习、图神经网络排在前三位,并且强化学习和深度学习的投稿数量要远超其他研究领域,例如对比学习、迁移学习的投稿数量不足强化学习的四分之一。
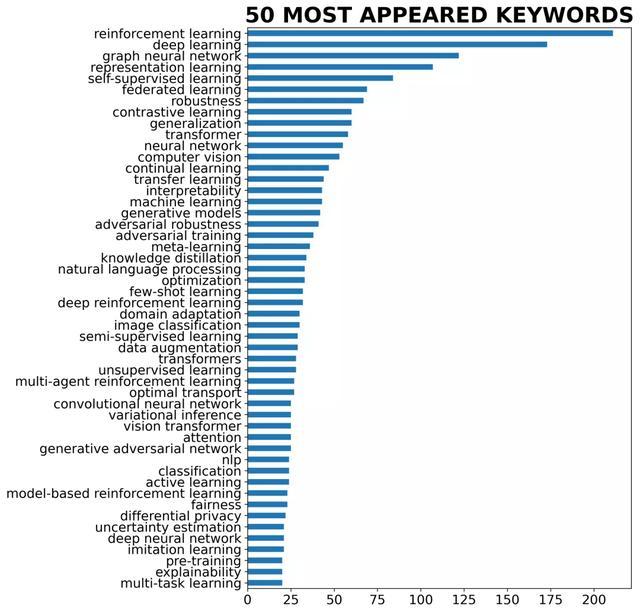
通过词云可视化后这种趋势也一目了然。

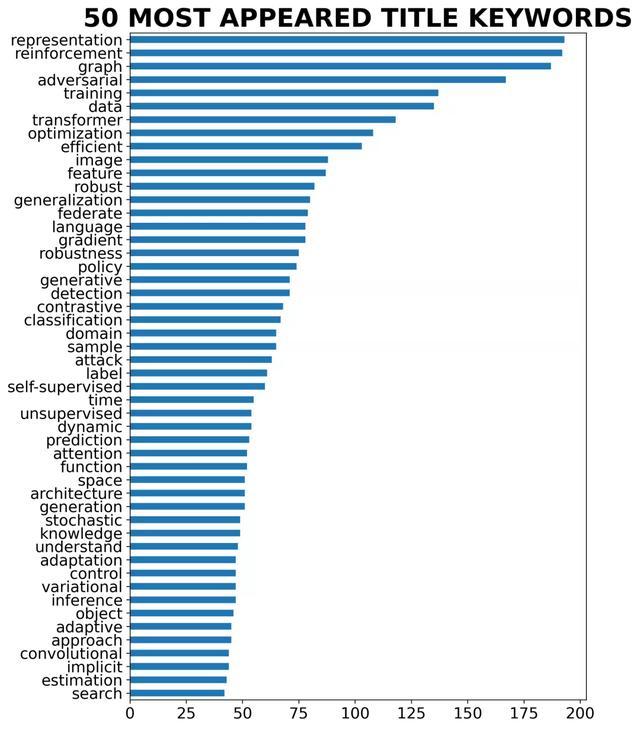
通过对标题关键词的单词进行分析后,可以看到论文使用的词的差距没有短语那么大,研究人员更喜欢最喜欢用表示(representation)这个词,毕竟会议的名字都是International Conference on Learning Representations (ICLR)。
作者在仓库中放出了爬取论文列表的代码,不过应该只能在Windows平台下运行。
首先需要下载一个msedgedriver.exe 的程序,方便模仿浏览器的行为进行数据爬取。除了Microsoft Edge外,也可以使用Chromium的driver。
爬取数据大约耗时30分钟,当然如果不想运行,作者也提供了爬取后的数据。
这个仓库受到ICLR2021-OpenReviewData数据分析的启发,通过数据对比可以发现,ICLR 2021的前两名依然是深度学习和强化学习,只不过位置发生了变换,三四名也是图神经网络和表示学习,位次也发生了转换。在ICLR 2021 中比较火热的元学习(meta learning),过了一年后热度也有了明显的下降。
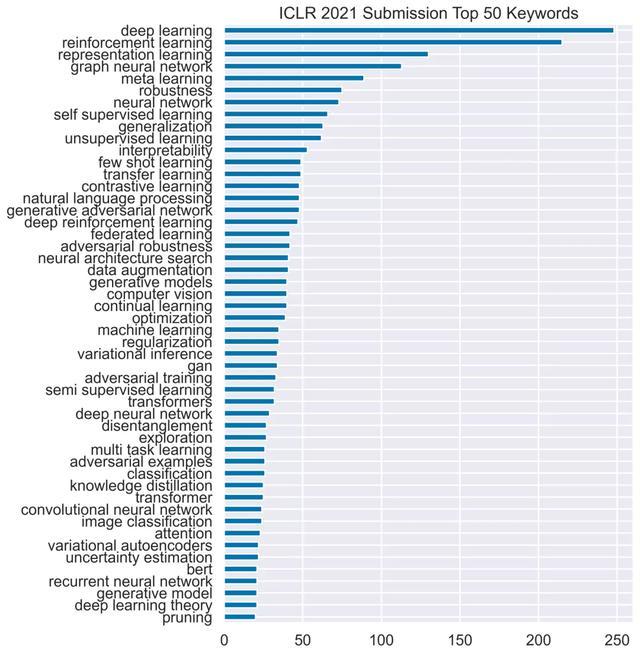
在ICLR 2021 的所有论文中,平均分为5.367,大部分论文都集中在5-6分,3.8分以下和7分以上都是一件不容易的事。
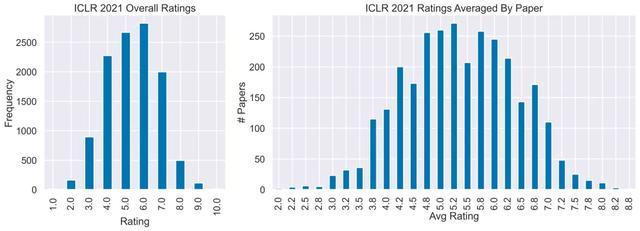
作者还研究了一下文章的评分和关键词之间的关系,可以发现reviewer的平均评分和关键字的频率之间有很大的关系,要最大限度地提高获得更高评分的机会,可以使用诸如深度生成模型(deep generative models)或标准化流(normalizing flows)之类的关键字。
绝大多数计算机科学会议都使用匿名同行评审,OpenReview 提供一个平台旨在促进同行评审过程的开放性。论文(元)评论、反驳和最终决定都将向公众公布。
当然OpenReview这种方式也会促使各位作者更加慎重地投稿自己的论文,防止被公开处刑。

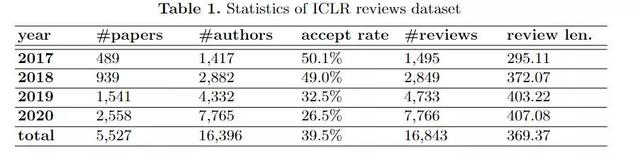
除了上述的简单分析外,OpenReview 也可以作为更大规模的语料提供给研究者进行研究,研究人员从OpenReview平台收集了5527份意见书和16853份评论,除此之外还从Google Scholar和arXiv.org的非同行评审版本收集这些提交的引文数据。

ICLR 自2013年开始一直使用OpenReview 平台进行双盲评审,每篇论文分配评审后,通常由三名评审员独立评估一篇论文。在rebuttal之后,评论者可以访问作者的回复和其他同行的意见,并相应地修改他们的评论。
然后,项目主席为每篇论文撰写元评论,根据三篇匿名评论做出最终的接受/拒绝决定。每次正式评审主要包括评审分数(1到10之间的整数)、评审员信心水平(1到5之间的整数)和详细评审意见。官方评论和元评论都在OpenReview平台上向公众开放,也可以在OpenReview上发布他们的评论。
论文中爬取了2017年以来的审查数据,因为2017年之前提交的资料太少。虽然利用了双盲审查过程,但在论文的最终决定之后,还将公布被拒绝掉的作者的身份。
由于提交量的大幅增加,ICLR 2020雇佣了更多的评审志愿者。有人抱怨评审人员的质量严重下降(47%的评审没有在相关领域发表文章)。在其他人工智能会议上,如NIPS、CVPR和AAAI中也观察到类似的情况。许多作者抱怨他们的意见没有得到很好的评价,因为指定的非专家评审员缺乏足够的技术背景,无法理解他们的主要贡献。
但这些非专家对审查进程有何影响却没有一个定量的分析。
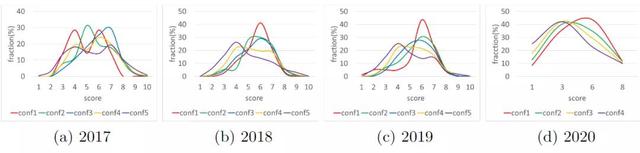
对于2017-2019年ICLR,审核人给出1到10之间的审核分数(整数),并要求选择1到5之间的置信水平(整数)。对于ICLR 2020,评审员在{1,3,6,8}中给出评级分数,并应选择介于1和4之间的经验评估分数(类似于置信度分数)。对于2018-2020年,置信度为1和2的重新评估分数可能高于置信度为4和5的审查分数。
2017年ICLR的趋势不清楚,因为它包含的样本太少,不具有统计意义。2017-2019年,最低置信水平审查的平均审查分数为5.675,而最高置信水平审查的平均审查分数为4.954。2020年,最低和最高置信水平审查的数字分别为4.726和3.678。
研究结果表明,低置信度的评审员(如1级和2级)倾向于更宽容,因为他们可能对自己的决定没有信心,而高自信的评审员(如4级和5级)倾向于更强硬和严格,因为他们可能对确定的弱点有信心。
下图中每一点都表示一组具有特定置信水平的评审,点的大小表示该组中评论的相对数量,两点之间的距离表示两组之间的评审分数差异。
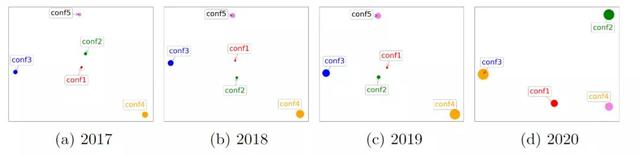
根据每个评论的情绪分析结果和评论得分的相关性分析中,研究人员将具有相同方面情感组合的评论分组,并计算每组的平均评论分数,并且不考虑接受少于3次审查的群体,因为他们的样本太少,不具有统计显著性。
将结果可视化后可以看到,从宏观角度来看,较高的审查分数通常会带来更积极的方面,这也是意料之中的。还观察到,大多数评分高于6分的评论在新颖性、动机和表现方面没有负面评论,但在相关工作和实验中可能存在一些缺陷。对论文总体持肯定态度的审稿人可能会对相关工作和实验提出改进建议,使论文更加完善。演讲质量和实验似乎比其他方面更经常被提及,并且对表达的积极情绪分布更加均匀。这意味着陈述在决策中不起重要作用。
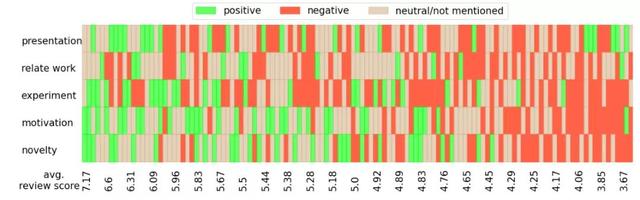
同样有趣的是,没有一项审查的所有方面都是积极的或消极的。一篇论文不太可能在所有方面都完美无缺或毫无价值。审稿人也可能对论文更严格,对差的论文更宽容。
通过深入了解这些数据,可以得到一些有趣的发现,这些发现有助于理解公众参与的双盲同行评审过程的有效性,可能还有助于撰写论文、审查论文以及决定是否接受论文。
人工智能会议是一个接收范围广泛的学科领域。作者经常被要求选择与他们提交的内容最相关的领域。区域主席可以为某个研究领域的提交做出决策。不同地区可能会收到不同数量的提交,也可能有不同的接受率。项目主席有时会在会议的开幕式上宣布每个区域的提交数量和接受率,这可能以某种方式表明每个区域的受欢迎程度。
但是,按地区进行的分类比较粗糙,需要提供更具体信息的更细粒度的分类。由于OpenReview提供了更详细的提交信息,可以利用每个提交的标题、摘要和关键字来提供更细粒度的聚类结果,并收集每个提交集群的接受率统计数据。
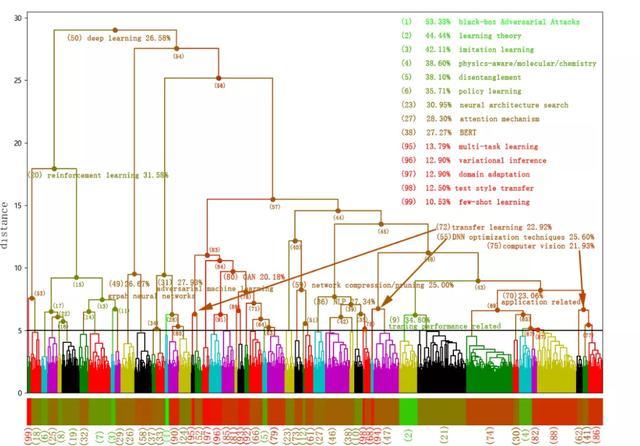
从接收主题上可以观察到大体上是一个深度学习研究的总体结构及研究主题内部之间的相关性。例如,左侧部分的提交内容属于强化学习领域。
另一个独立的研究领域是图形神经网络(GNNs),作为一个很有前途的领域,它在短短2-3年内变得非常热门,它通过关注图形结构将自己与其他领域区分开来。对抗式机器学习(Adversarial Machine Learning)也是一个新的独立研究领域。
下一个独立主题是对抗生成网络(GANs)。但GANs并不是完全独立的,可以发现许多关于NLP和CV的提交文件也与GANs混合在一起。还观察到迁移学习与GANs非常接近,因为一些研究已经将迁移学习应用于GANs。右部分中的大多数提交内容都与应用程序相关(例如,视觉、音频、NLP、生物学、化学和机器人学),它们与DNN优化技术混合在一起,因为在特定的应用领域提出了许多优化来改进DNN。
强化学习、GNNs、GANs、NLP和计算机视觉吸引了超过50%的提交,这些都是当今深度学习研究的热门话题。
不同课题之间的接受率也存在显著差异,黑匣子对抗性攻击(Black-Box Adversarial Attacks)提交的集群接受率最高(53.33%),属于对抗性机器学习领域。提交的few-shot learning主题的接受率最低(10.53%),属于强化学习领域。图神经网络接受率为26.67%,BERT接受率为27.27%,GANs 接受率为20.18%,强化学习接受率为31.58%。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










