

 新火种
2023-10-10
新火种
2023-10-10 


统一图像和文字生成的MiniGPT-5来了:Token变Voken,模型不仅能续写,还会自动配图了
OpenAI 的 GPT-5 大模型似乎还遥遥无期,但已经有研究者率先推出了创新视觉与语言交叉生成的模型 MiniGPT-5。这对于生成具有连贯文本描述的图像具有重要意义。
 论文地址:https://browse.arxiv.org/pdf/2310.02239v1.pdf项目地址:https://github.com/eric-ai-lab/MiniGPT-5
论文地址:https://browse.arxiv.org/pdf/2310.02239v1.pdf项目地址:https://github.com/eric-ai-lab/MiniGPT-5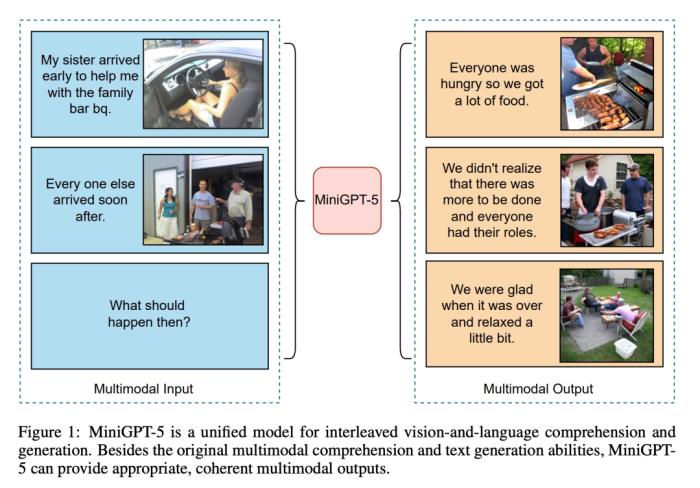





图片来源:由无界 AI生成
大模型正在实现语言和视觉的跨越,有望无缝地理解和生成文本和图像内容。在最近的一系列研究中,多模态特征集成不仅是一种不断发展的趋势,而且已经带来了从多模态对话到内容创建工具等关键进步。大型语言模型在文本理解和生成方面已经展现出无与伦比的能力。然而,同时生成具有连贯文本叙述的图像仍然是一个有待发展的领域。
近日,加州大学圣克鲁兹分校的研究团队提出了 MiniGPT-5,这是一种以 「生成式 voken」概念为基础的创新型交错视觉语言生成技术。
论文地址:https://browse.arxiv.org/pdf/2310.02239v1.pdf项目地址:https://github.com/eric-ai-lab/MiniGPT-5通过特殊的视觉 token「生成式 voken」,将 Stable Diffusion 机制与 LLM 相结合, MiniGPT-5 为熟练的多模态生成预示了一种新模式。同时,本文提出的两阶段训练方法强调了无描述基础阶段的重要性,使模型在数据稀缺的情况下也能「茁壮成长」。该方法的通用阶段不需要特定领域的注释,这使得本文解决方案与现有的方法截然不同。为了确保生成的文本和图像和谐一致,本文的双损失策略开始发挥作用,生成式 voken 方法和分类方法进一步增强了这一效果。
在这些技术的基础上,这项工作标志着一种变革性的方法。通过使用 ViT(Vision Transformer)和 Qformer 以及大型语言模型,研究团队将多模态输入转换为生成式 voken,并与高分辨率的 Stable Diffusion2.1 无缝配对,以实现上下文感知图像生成。本文将图像作为辅助输入与指令调整方法相结合,并率先采用文本和图像生成损失,从而扩大了文本和视觉之间的协同作用。
MiniGPT-5 与 CLIP 约束等模型相匹配,巧妙地将扩散模型与 MiniGPT-4 融合在一起,在不依赖特定领域注释的情况下实现了较好的多模态结果。最重要的是,本文的策略可以利用多模态视觉语言基础模型的进步,为增强多模态生成能力提供新蓝图。
如下图所示,除了原有的多模态理解和文本生成能力外,MiniGPT5 还能提供合理、连贯的多模态输出:
本文贡献体现在三个方面:
建议使用多模态编码器,它代表了一种新颖的通用技术,并已被证明比 LLM 和反转生成式 vokens 更有效,并将其与 Stable Diffusion 相结合,生成交错的视觉和语言输出(可进行多模态生成的多模态语言模型)。重点介绍了一种新的两阶段训练策略,用于无描述多模态生成。单模态对齐阶段从大量文本图像对中获取高质量的文本对齐视觉特征。多模态学习阶段包括一项新颖的训练任务,即 prompt 语境生成,确保视觉和文本 prompt 能够很好地协调生成。在训练阶段加入无分类器指导,进一步提高了生成质量。与其他多模态生成模型相比, MiniGPT-5 在 CC3M 数据集上取得了最先进的性能。MiniGPT-5 还在 VIST 和 MMDialog 等著名数据集上建立了新的基准。接下来,我们一起来看看该研究的细节。
方法概览
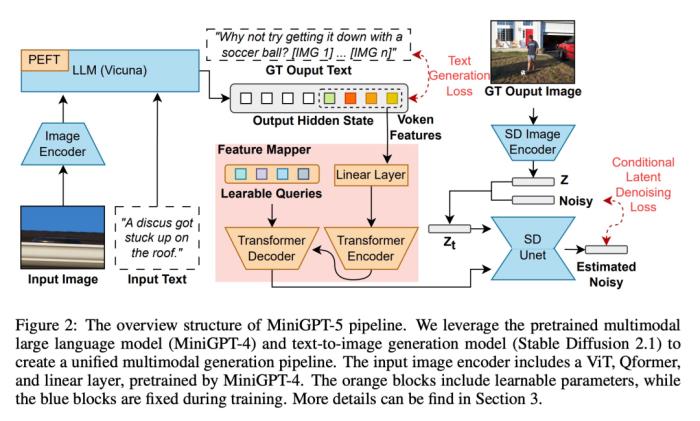
为了使大型语言模型具备多模态生成能力,研究者引入了一个结构化框架,将预训练好的多模态大型语言模型和文本到图像生成模型整合在一起。为了解决不同模型领域之间的差异,他们引入了特殊的视觉符号「生成式 voken」(generative vokens),能够直接在原始图像上进行训练。此外,还推进了一种两阶段训练方法,并结合无分类器引导策略,以进一步提高生成质量。
多模态输入阶段
多模态大模型(如 MiniGPT-4)的最新进展主要集中在多模态理解方面,能够处理作为连续输入的图像。为了将其功能扩展到多模态生成,研究者引入了专为输出视觉特征而设计的生成式 vokens。此外,他们还在大语言模型(LLM)框架内采用了参数效率高的微调技术,用于多模态输出学习。
多模态输出生成
为了使生成式 token 与生成模型精确对齐,研究者制定了一个用于维度匹配的紧凑型映射模块,并纳入了若干监督损失,包括文本空间损失和潜在扩散模型损失。文本空间损失有助于模型学习 token 的正确定位,而潜在扩散损失则直接将 token 与适当的视觉特征对齐。由于生成式符号的特征直接由图像引导,因此该方法不需要全面的图像描述,从而实现了无描述学习。
训练策略
鉴于文本域和图像域之间存在不可忽略的领域偏移,研究者发现直接在有限的文本和图像交错数据集上进行训练可能会导致错位和图像质量下降。
因此,他们采用了两种不同的训练策略来缓解这一问题。第一种策略包括采用无分类器引导技术,在整个扩散过程中提高生成 token 的有效性;第二种策略分两个阶段展开:最初的预训练阶段侧重于粗略的特征对齐,随后的微调阶段致力于复杂的特征学习。
实验及结果
为了评估模型功效,研究者选择了多个基准进行了一系列评估。实验旨在解决几个关键问题:
MiniGPT-5 能否生成可信的图像和合理的文本?在单轮和多轮交错视觉语言生成任务中,MiniGPT-5 与其他 SOTA 模型相比性能如何?每个模块的设计对整体性能有什么影响?为了评估模型在不同训练阶段的不同基准上的性能,MiniGPT-5 的定量分析样本如下图 3 所示:
此处的评估横跨视觉(图像相关指标)和语言(文本指标)两个领域,以展示所提模型的通用性和稳健性。
VIST Final-Step 评估
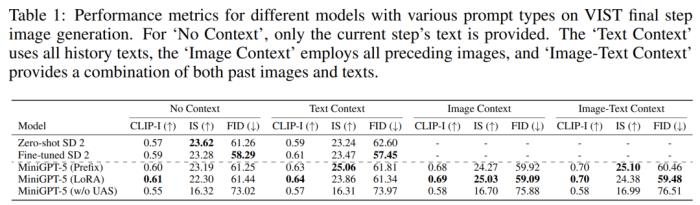
第一组实验涉及单步评估,即根据最后一步的 prompt 模型生成相应的图像,结果如表 1 所示。
在所有三种设置中,MiniGPT-5 的性能都优于微调后的 SD 2。值得注意的是,MiniGPT-5(LoRA)模型的 CLIP 得分在多种 prompt 类型中始终优于其他变体,尤其是在结合图像和文本 prompt 时。另一方面,FID 分数凸显了 MiniGPT-5(前缀)模型的竞争力,表明图像嵌入质量(由 CLIP 分数反映)与图像的多样性和真实性(由 FID 分数反映)之间可能存在权衡。与直接在 VIST 上进行训练而不包含单模态配准阶段的模型(MiniGPT-5 w/o UAS)相比,虽然该模型保留了生成有意义图像的能力,但图像质量和一致性明显下降。这一观察结果凸显了两阶段训练策略的重要性。
VIST Multi-Step 评估
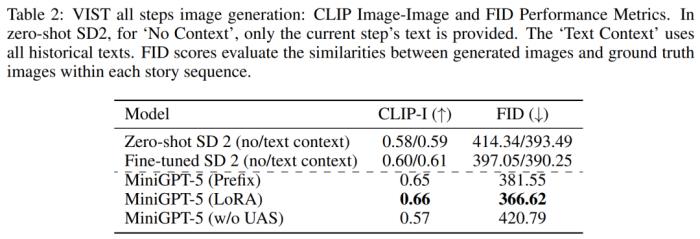
在更详细全面的评估中,研究者系统地为模型提供了先前的历史背景,并随后在每个步骤中对生成的图像和叙述进行评估。
表 2 和表 3 概述了这些实验的结果,分别概括了图像和语言指标的性能。实验结果表明,MiniGPT-5 能够在所有数据中利用 long-horizontal 多模态输入 prompt 生成连贯、高质量的图像,而不会影响原始模型的多模态理解能力。这凸显了 MiniGPT-5 在不同环境中的功效。
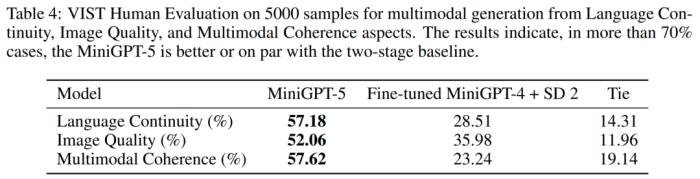
VIST 人类评估
如表 4 所示,MiniGPT-5 在 57.18% 的情况下生成了更贴切的文本叙述,在 52.06% 的情况下提供了更出色的图像质量,在 57.62% 的场景中生成了更连贯的多模态输出。与采用文本到图像 prompt 叙述而不包含虚拟语气的两阶段基线相比,这些数据明显展示了其更强的多模态生成能力。
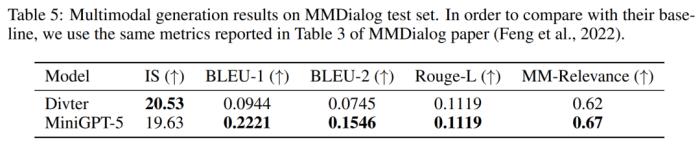
MMDialog 多轮评估
结果如表 5 所示,MiniGPT-5 在生成更准确的文本回复方面优于基线模型 Divter。虽然生成的图像质量相似,但与基准模型相比,MiniGPT-5 在 MM 相关性方面更胜一筹,表明其可以更好地学习如何适当定位图像生成,并生成高度一致的多模态响应。
效果如何呢?我们来看一下 MiniGPT-5 的输出结果。下图 7 为 MiniGPT-5 与 CC3M 验证集上的基线模型比较。
下图 8 为 MiniGPT-5 与 VIST 验证集上基线模型的比较。
下图 9 为 MiniGPT-5 与 MMDialog 测试集上基线模型的比较。
更多研究细节,可参考原论文。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










