

 新火种
2024-11-15
新火种
2024-11-15 


自动驾驶界秋名山车神!CoRL杰出论文让自驾车学会漂移,机器人整出新活
今年的机器人顶会 CoRL 杰出论文,竟然帮自动驾驶车稳稳地完成了漂移。
先来个甜甜圈漂移热个身:
然后,上点难度,来个「8 字」:
最后来个蛇形绕桩(Slalom,这次没有实体的桩)。可以听见,在绕到一半的时候,工作人员忍不住欢呼了一下。
即使地面湿滑,自动驾驶汽车的发挥也不受影响。
这些动作都是由一个安装了自动驾驶系统的雷克萨斯 LC 500 汽车来完成的,同样一套系统安装到丰田 Supra 上也可以安全运行。这得益于研究者们在 CoRL 一篇杰出论文中提出的方法,该方法可以提高自动驾驶在极限操控(如漂移)条件下的安全性和可靠性。
另外一篇获奖论文则有关机器人导航。作者借助强化学习对导航智能体进行了端到端大规模训练,结果可以很好地泛化到现实世界。其中,论文一作 Kuo-Hao Zeng 是一位华人学者,目前就职于艾伦人工智能研究院。他本科毕业于中山大学,在清华大学拿到了硕士学位,去年在美国华盛顿大学拿到了博士学位。

在颁奖典礼现场,获奖者拿到了一个神秘的大盒子。据透露,里面装的是看起来很美味的零食:
CoRL 是面向机器人学习研究的会议,涵盖机器人学、机器学习和控制等多个主题,包括理论与应用。自 2017 年首次举办以来,CoRL 已经成为了机器人学与机器学习交叉领域的全球顶级学术会议之一。
除了两篇杰出论文,还有四篇论文拿到了今年的杰出论文提名,比如只需要学习 5 分钟人类演示,就能轻松泛化到新的物体和场景的机器人策略 EquiBot、ALOHA 团队主要成员的新工作 —— 人形机器人 HumanPlus,斯坦福提出的首个开源视觉语言动作大模型 OpenVLA 等。
以下是关于获奖论文和提名论文的详细介绍。
杰出论文奖获奖论文
论文一:One Model to Drift Them All

作者:Franck Djeumou, Thomas Jonathan Lew, Nan Ding, Michael Thompson, Makoto Suminaka, Marcus Greiff, John Subosits
机构:丰田研究院、美国伦斯勒理工学院
论文链接:
让自动驾驶汽车在极限操控状态下 —— 也就是轮胎抓地力达到最大时 —— 安全运行是一个非常重要的问题,尤其是在紧急避障或恶劣天气等情况下。不过,要实现这样的能力并不容易,因为这项任务本身变化多端,而且对道路、车辆特性以及它们之间的相互作用的不确定性非常敏感。
为了克服这些难题,作者提出了一个新的方案:利用一个包含多种车辆在多样环境下行驶轨迹的未标记数据集,来训练一个高性能车辆控制的条件扩散模型。他们设计的这个扩散模型能够通过一个基于物理信息的数据驱动动态模型的参数多模态分布,来捕捉复杂数据集中的轨迹分布。
通过将在线测量数据作为生成过程的条件,作者将这个扩散模型融入到实时模型预测控制框架中,用于极限驾驶。
在丰田 Supra 和雷克萨斯 LC 500 上进行的大量实验表明,在不同路况下使用不同轮胎时,单一扩散模型可使两辆车实现可靠的自动漂移。该模型与特定任务专家模型的性能相匹配,同时在对未知条件的泛化方面优于专家模型,为在极限操控条件下采用通用、可靠的自动驾驶方法铺平了道路。

左:条件扩散模型在两辆车上执行漂移轨迹的示例。右:控制器结构概述和在线模型参数生成过程。
论文二:PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators

作者:Kuo-Hao Zeng, Kiana Ehsani, Rose Hendrix, Jordi Salvador, Zichen Zhang, Alvaro Herrasti, Ross Girshick, Aniruddha Kembhavi, Luca Weihs
机构:艾伦人工智能研究所 PRIOR(Perceptual Reasoning and Interaction Research)团队
项目链接:
论文链接:
PoliFormer 是 Policy Transformer 的缩写。这是一种纯 RGB 室内导航智能体,它通过强化学习进行端到端大规模训练。尽管纯粹是在模拟中训练,但训练结果无需调整即可泛化到现实世界。
PoliFormer 使用基础视觉 transformer 编码器和因果 transformer 解码器来实现长期记忆和推理。它在不同的环境中进行了数亿次交互训练,利用并行化、多机扩展实现了高吞吐量的高效训练。
PoliFormer 是一个优秀的导航器,在 LoCoBot 和 Stretch RE-1 机器人这两种不同的具身智能方案和四项导航基准测试中均取得了 SOTA 成绩。它突破了以往工作的瓶颈,在 CHORES-S 基准上实现了前所未有的 85.5% 的目标导航成功率,绝对值提高了 28.5%。
PoliFormer 还可轻松扩展到各种下游应用,如目标跟踪、多目标导航和开放词汇导航,无需进行微调。
以下是一些利用 PoliFormer 进行导航的机器人示例:
1、穿过布满障碍的长走廊找到苹果(LoCoBot):

2、找到一本名为「人类」的书(Stretch RE-1)

3、一次寻找多个物品 —— 沙发、书本、厕所和室内植物(Stretch RE-1)

杰出论文提名
论文 1:Re-Mix: Optimizing Data Mixtures for Large Scale Imitation Learning

机构:斯坦福大学、UC 伯克利
作者:Joey Hejna, Chethan Anand Bhateja, Yichen Jiang, Karl Pertsch, Dorsa Sadigh
论文地址:
为了训练机器人基础模型,研究领域正在构建越来越多的模仿学习(imitation learning)数据集。然而,数据选择在视觉和自然语言处理中已经被认为是至关重要的,但在机器人技术领域,模型实际上应该使用哪些数据进行训练还是个悬而未决的问题。
基于此,该研究探索了如何权衡机器人数据集的不同子集或「域」以进行机器人基础模型预训练。
具体来说,该研究使用分布式鲁棒优化(DRO)来最大化所有可能的下游域最坏情况性能,提出方法 Re-Mix。Re-Mix 解决了将 DRO 应用于机器人数据集时出现的广泛挑战。Re-Mix 采用提前终止训练(Early Stopping)、动作归一化和离散化来解决这些问题。
通过在最大的开源机器人操作数据集 Open X-Embodiment 上进行广泛的实验,该研究证明数据管理可以对下游性能产生巨大的影响。
论文 2:Equivariant Diffusion Policy

作者:Dian Wang, Stephen Hart, David Surovik, Tarik Kelestemur, Haojie Huang, Haibo Zhao, Mark Yeatman, Jiuguang Wang, Robin Walters, Robert Platt
机构:东北大学、波士顿动力
论文地址:
在机器人学习领域,如何构建有效的模仿学习方法,让机器人能从有限数据中的学习泛化到多样的现实环境中,一直是一个挑战。
为此,该团队结合了 SIM (3) 等神经网络架构与扩散模型,提出了 EquiBot。机器人在学习过程中,不会受到物体大小、位置或方向变化的影响,从而提高了其在不同环境中的适应能力。
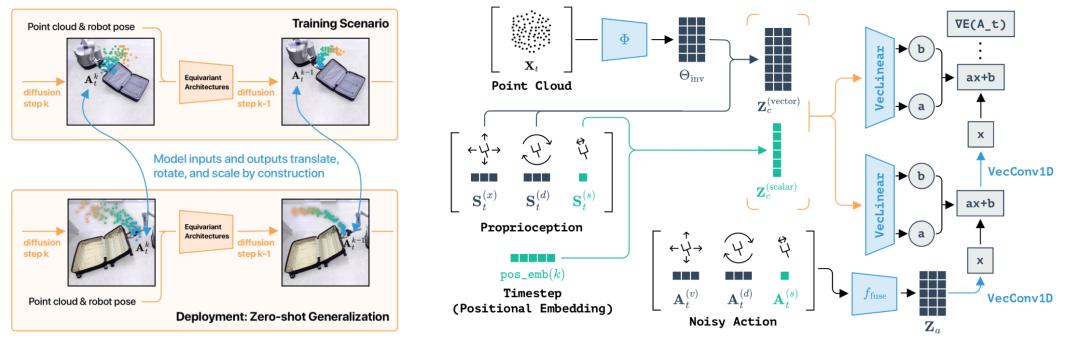
同时,扩散模型的多模态和鲁棒性优势,进一步增强了 EquiBot 策略在未知环境中的适用性。
实验结果表明, EquiBot 显著减少了机器人对训练数据的需求,对新场景的泛化能力也大幅提升。比如下面这个收拾行李的任务,被 EquiBot 策略点化的机器人只需要学习 5 分钟的人类演示,就能轻松泛化到新的物体和场景。

论文 3:HumanPlus: Humanoid Shadowing and Imitation from Humans

作者:Zipeng Fu, Qingqing Zhao, Qi Wu, Gordon Wetzstein, Chelsea Finn
机构:斯坦福大学
论文地址:
说起斯坦福开源的 Mobile ALOHA 全能家务机器人,大家肯定印象深刻,ALOHA 做起家务活来那是有模有样:滑蛋虾仁、蚝油生菜、干贝烧鸡,一会儿功夫速成大餐:

这款人形 HumanPlus,也是 ALOHA 团队主要成员的工作。HumanPlus 和 ALOHA 都在探索模仿学习对机器人带来怎样的增益。HumanPlus 更关注设计一套数据处理流程,让人形机器人可以自主学习技能。
该研究首先基于 40 小时的人体运动数据集,通过强化学习在模拟环境中训练低级策略。然后将这一策略迁移到现实世界中,使人形机器人仅使用 RGB 相机即可实时跟踪人体和手部运动,形成 Shadowing 系统。
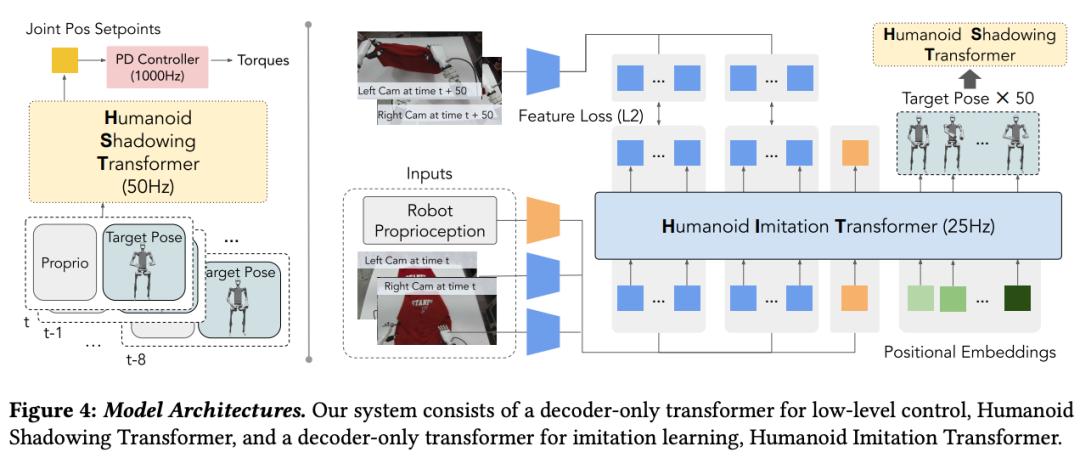
人类操作员可以通过 Shadowing 系统远程控制人形机器人,收集其全身运动数据,以便在现实环境中学习各种任务。基于这些数据,研究人员采用有监督的行为克隆方法,再对机器人进行训练。

只需 40 次演示,搭载 Shadowing 系统的机器人就可以可以自主完成诸如穿鞋站立和行走,从仓库货架上卸载物品,叠衣服,重新排列物品,打字以及与另一个机器人打招呼等任务,成功率为 60-100%。

更多详情,请参看机器之心之前的报道:论文 4:OpenVLA: An Open-Source Vision-Language-Action Model

机构:斯坦福大学、UC 伯克利、丰田研究院、Google Deepmind 等
作者:Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, Chelsea Finn
论文地址:
项目地址:
机器人技术视觉语言动作(VLA)的广泛采用一直面临挑战,因为:
现有的 VLA 基本上是封闭的,无法开放访问;
之前的工作未能探索针对新任务有效微调 VLA 的方法。
为了解决上述挑战,斯坦福提出首个开源 VLA 大模型 ——OpenVLA(7B 参数),经过 97 万个真实机器人演示的多样化数据集进行训练。OpenVLA 以 Llama 2 语言模型为基础,结合视觉编码器,融合了 DINOv2 和 SigLIP 的预训练特征。
作为增加数据多样性和新模型组件的产物,OpenVLA 在通用操作方面展示了强大的结果,在 29 个任务上任务成功率比 RT-2-X (55B) 等封闭模型高出 16.5%,参数减少为 1/7。

该研究进一步表明,可以针对新设置有效地微调 OpenVLA,在涉及多个对象和强大语言基础能力的多任务环境中具有特别强的泛化结果。

在计算效率方面,该研究表明 OpenVLA 可以通过低秩适应(LoRA)方法在消费级 GPU 上进行微调,并通过量化有效地提供服务,而不会影响下游的成功率。
相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










