新火种
2023-09-28
新火种
2023-09-28 


能说会看,ChatGPT多模态亮相!官方透露:模型早在去年就训完了
文 | 尚恩
编辑 | 邓咏仪
刚刚发布文生图工具DALL·E 3后,OpenAI又在半夜带多模态ChatGPT来炸场。
来源:OpenAI
美国时间9月25日晚,OpenAI在ChatGPT中推出新的语音和图像功能,允许用户直接与ChatGPT进行语音对话或展示正在讨论的内容。简单来说现在的ChatGPT看、听、说样样俱全。
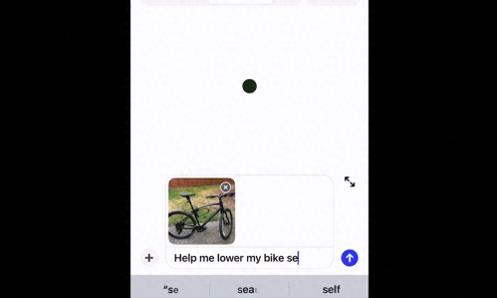
比如拍一张照片,询问如何调整自行车座椅高度,GPT给你说的头头是道。
来源:OpenAI
又或者,晚上回家后打开冰箱不知道吃啥,拍张照扔给GPT,它就能生成详细的菜谱。
OpenAI表示,多模态将在两周内先向“ChatGPT Plus订阅用户”和“企业版用户”推出,iOS和安卓都支持。
除了官方放出的这些实操细节,令人惊讶的是,多模态版GPT-4V模型其实早在2022年就训练完了,和GPT-4是同期进行训练的…

来源:公开网络
消息一出,网上可是炸开了锅,不少网友纷纷表示“太牛了”!
来源:X(Twitter)
也有网友开始做梦畅想:“终于可以拥有HER同款女友了”。

来源:X(Twitter)
看完这些演示,也有一部分网友暗暗发问:
有多少创业公司的饭碗在刚刚5分钟内被抢了?
来源:X(Twitter)
能说会看,一种新的交互方式
根据OpenAI官方放出的消息,这次更新主要聚焦在两方面“基于图片的对话”和“实时语音对话”,直接在ChatGPT的APP里,就可以拍照上传开启对话。
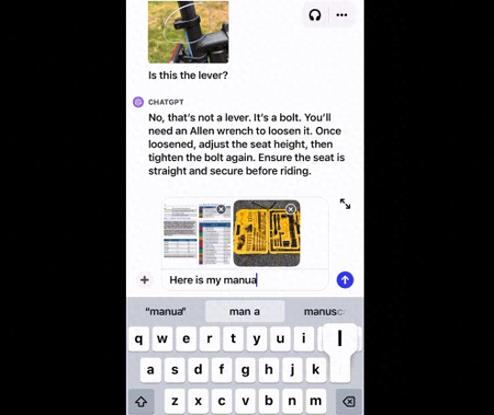
先来看看基于图片对话的功能,比如“如何调整自行车座椅高度”,ChatGPT会给出详细步骤,并指出要先找出“快拆杆”在哪。
来源:OpenAI
即使完全不熟悉自行车结构也没关系,可以直接在App上圈出照片的一部分,丢给GPT让它解释。就像在手机图片上直接圈出来一样,简单到飞起。
只见GPT立马就能识别出圈出的部分不是快拆杆,而是螺栓,并表示还需要找一个六角形扳手。
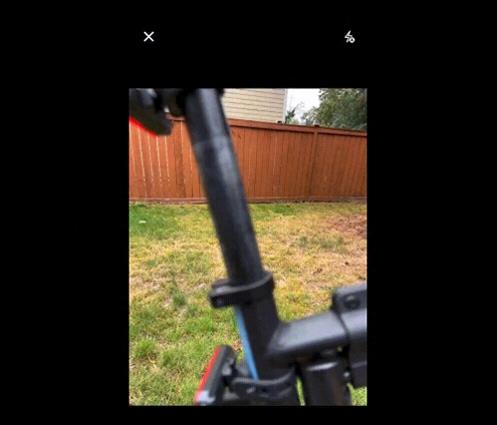
来源:OpenAI
不知道用什么工具,也没关系,直接把工具箱打开拍给ChatGPT,它不光能指出需要的工具,甚至连标签上的文字也能看懂,咱就是说也太方便了吧….
来源:OpenAI
语音部分的演示,则还是上周DALL·E 3演示的“小刺猬”,这次是让ChatGPT把5岁小朋友幻想中的“超级向日葵刺猬”讲成一个完整的睡前故事。

来源:OpenAI
此次ChatGPT升级背后的技术主要依赖于语音识别和语音合成,语音识别部分则是基于自家开源的Whisper模型,生成部分是基于额外的TTS(text-to-speech)模型进行,目前语音合成支持五种语音。
用户可以从“Juniper、Sky、Cove、Ember、Breeze”等五种不同的合成声音中进行选择,OpenAI表示这些声音都是与专业配音演员合作制作的。
更多语音交互细节,可试听官方的视频。
多模态模型更多细节
这次放出的ChatGPT多模态模型,官方版本叫GPT-4V(ision)。
根据OpenAI释出的报告显示,与GPT-4 类似,GPT-4V的训练是在2022年完成的,今年3月开始进行系统早期访问内测。鉴于GPT-4是GPT-4V视觉功能背后的技术,因此训练过程也是一样的。之后出于人工智能安全和合规考量,才等到现在才放出来。

来源:OpenAI
结合所有公布的视频演示与GPT-4V System Card中的内容,下面简单总结了GPT-4V的视觉能力。
物体检测:可以检测和识别图像中的常见物体,如汽车、动物、家居用品等。其物体识别能力在标准图像数据集上进行了评估。
文本识别:模型具有光学字符识别 (OCR) 功能,可以检测图像中的打印或手写文本并将其转录为机器可读文本。
人脸识别:可以定位并识别图像中的人脸,根据面部特征识别性别、年龄和种族属性。其面部分析能力是在 FairFace和LFW等数据集上进行测量。
验证码解决:在解决基于文本和图像的验证码时,GPT-4V显示出了视觉推理能力。
地理定位:具有识别风景图像中描绘的城市或地理位置的能力。
当然,看似强大的GPT-4V(ision),也有一些局限性。
比如,在空间关系方面,目前模型可能很难理解图像中对象的精确空间布局和位置,无法正确传达对象之间的相对位置;当图像中的对象严重重叠时,会无法进行区分并把不同对象混在一起;模型上下文推理能力不够,缺乏强大的视觉推理能力来深入分析图像的上下文并描述对象之间的隐式关系等。
另外,对于非常小的物体、文本或图像中的复杂细节,模型经常会错过或误解,从而导致错误的关系描述。
上面提到过,之所以现在才放出多模态模型,主要原因是为了确保模型安全性和效用。
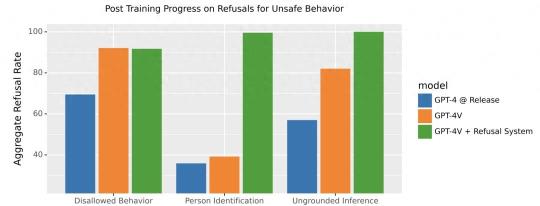
对于模型安全这块,OpenAI也进行一系列的评估。团队采用逐步部署策略,首先提供给一小部分用户试用,以便收集反馈和识别潜在风险,如系统误报或人脸识别的隐私问题等。之后进行了比较长时间全面综合评估,包括聘请外部专家进行伦理测试和建立性能度量标准。
来源:OpenAI
在评估过程中,团队发现模型会出现例如无法给予准确医学建议、刻板印象、无根据的推断等问题。为缓解这些问题,OpenAI也采取措施,包括“增加安全训练数据以拒绝不当请求,并改进系统以应对文字和图像的挑战”。
回看OpenAI的每次重量级产品发布/提升,都是在竞争对手推出新品后立即做出反应。比如,在谷歌宣布自己的最强大模型“Gemini”、推出了Bard拓展程序(Extensions)后,OpenAI立马就用DALL·E 3和多模态模型GPT-4V(ision),又把业界惊艳了一把。
这其中,作为OpenAI话事人的Sam Altman,其对商业嗅觉的超高灵敏度在很大程度上让OpenAI一直保持领先状态,而这一次在多模态大战中,又小赢了一把。

来源:公开网络
长按添加「智涌」小助手入群
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章