

 新火种
2024-09-04
新火种
2024-09-04 


GPT-4omini排名雪崩,大模型竞技场规则更新,奥特曼刷分小技巧无效了
大模型竞技场规则更新,GPT-4o mini排名立刻雪崩,跌出前10。

新榜单对AI回答的长度和风格等特征做了降权处理,确保分数反映模型真正解决问题的能力。
想用漂亮的格式、增加小标题数量等技巧讨好用户、刷榜,现在统统没用了。
在新规则下,奥特曼的GPT-4o mini、马斯克的Grok-2系列排名显著下降,谷歌Gemini-1.5-flash小模型也有所回落。
Claude系列、Llama-3.1-405b大模型分数则纷纷上涨。
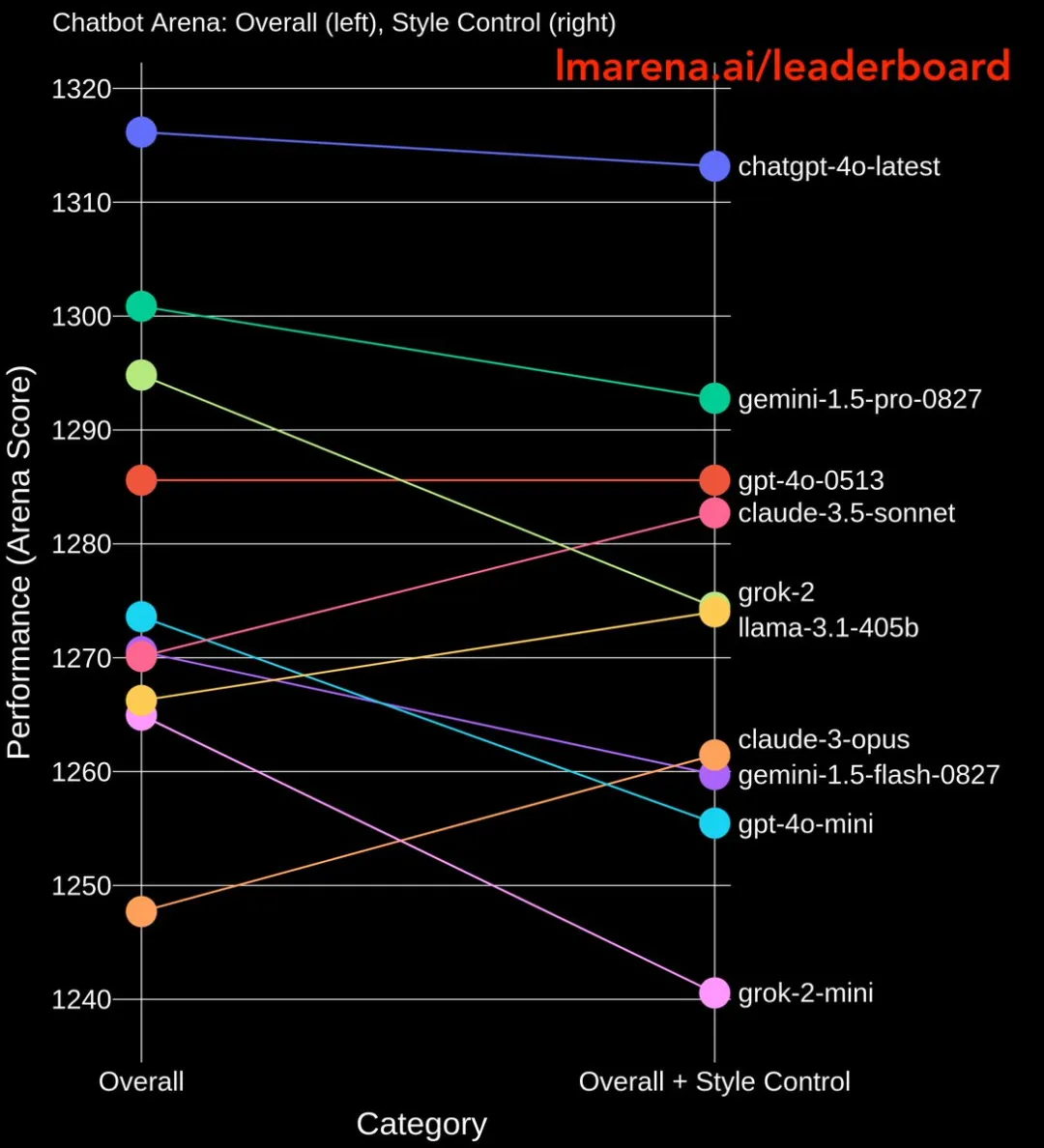
只计算困难任务(Hard Prompt)的情况下,大模型在风格控制榜单中的优势更加明显。
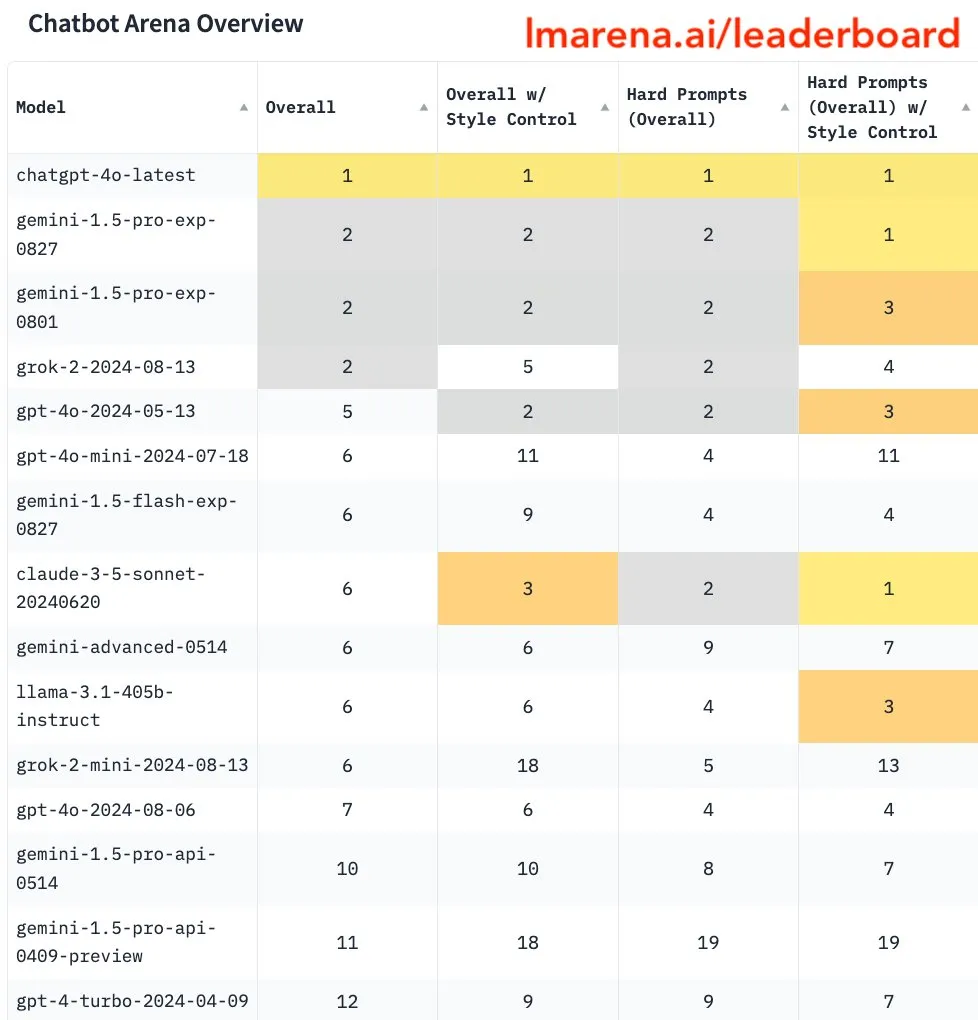
此前GPT-4o mini小模型一度登顶,与GPT-4o满血版并列第一,与网友的体感明显不符。
Lmsys大模型竞技场这个一度被Karpathy推荐的评价标准,口碑也跌落到“只能反映用户喜好而不是模型能力了”。
Lmsys组织痛定思痛,先是公开了GPT-4o mini参与的1000场battle数据,从而分析出模型拒绝回答率、生成内容长度、和格式排版是影响投票结果的几个因素。
而且奥特曼还在GPT-4o mini发布之前,暗示了正是按照人类偏好做优化的。
现在,Lmsys进一步推出了控制这些因素的新算法,而且还只是规划中的第一步。
 如何控制风格的影响?
如何控制风格的影响?假设有模型A擅长生成代码、事实和无偏见的答案等,但它的输出非常简洁。
模型B在实质内容(例如正确性)上不是很好,但它输出的内容长而详细、格式排版华丽。
那么哪个更好?
答案不是唯一的,Lmsys尝试用数学方法找出一个模型的得分有多少是内容或风格贡献的。
此外,最近也已经有研究表明,人类对排版漂亮和更详细的AI回答可能存在偏好性。

通过在Bradley-Terry回归中添加样式特征,如响应长度、markdown小标题的数量、列表和加粗文本数量作为自变量。
这是统计学中的一种常用技术,最近被AlpacaEval LC等用于大模型评估。
在回归中包含任何混杂变量(例如回答长度),可以将分数的增加归因于混杂变量,而不是模型能力本身。
相关代码已在Google Colab上公开。
此外团队还对“只控制长度”和“只控制格式”做了消融实验。GPT-4o mini、谷歌Gemini系列分数受格式影响更大。
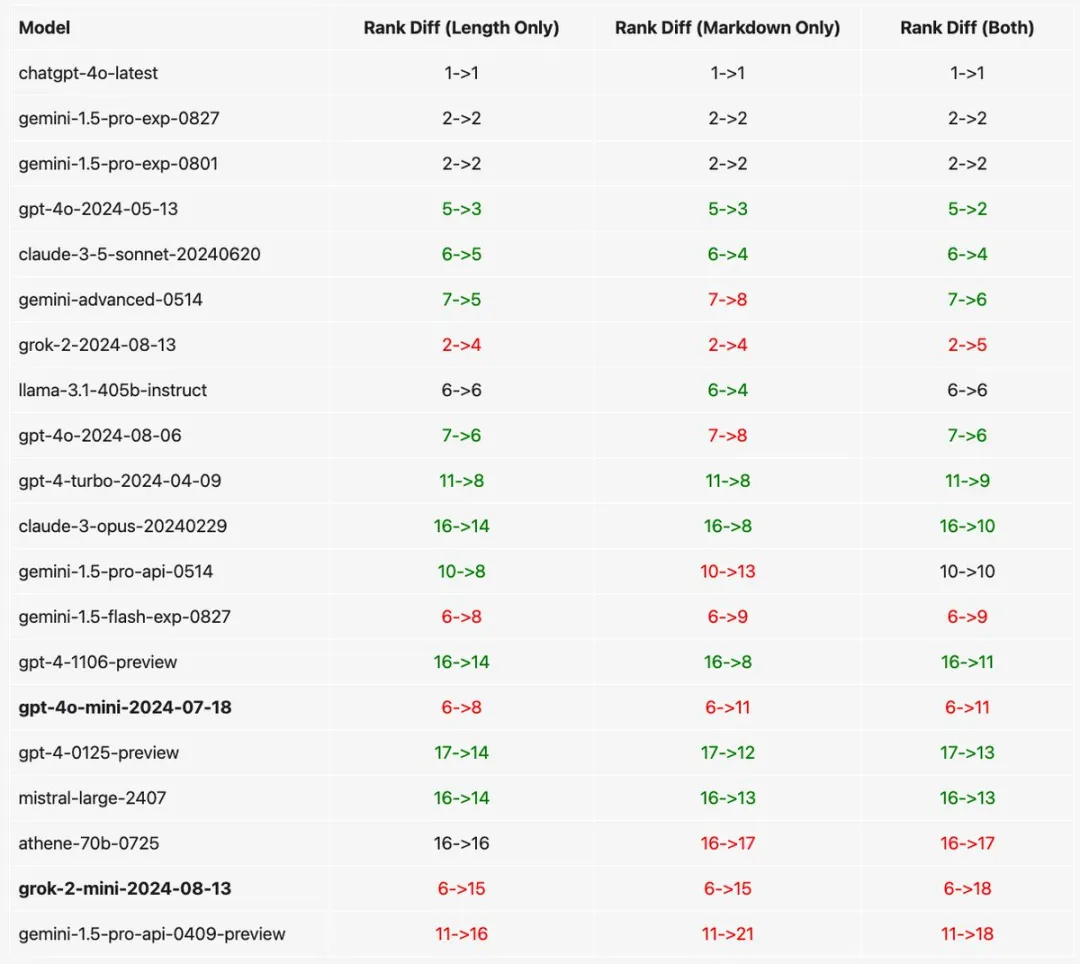
不过这种做法也存在局限性,比如可能存在未观察到的混杂因素,例如长度和回答质量之间的正相关,这些因素没有被考虑在内(例如思维链提示)。
有不少网友表示,调整后的困难任务榜单与自己的主观印象更吻合了。

也有人觉得,正是榜单和冲榜的大模型公司这种来回博弈,才能让整个领域一起进步。

你还在参考大模型竞技场结果选择模型吗?或者有什么更好的评估方法,欢迎在评论区分享。
参考链接:[1]https://x.com/lmsysorg/status/1829216988021043645[2]https://lmsys.org/blog/2024-08-28-style-control/[3]https://arxiv.org/abs/2402.10669
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










