

 新火种
2024-08-30
新火种
2024-08-30 


专访Motiff妙多国内首个UI大模型:UI领域,未来通用大模型很难赶超领域模型
「」去年年初ChatGPT引爆全球,大模型一路狂飙,迄今,行业的热潮从通用大模型早已转移到领域模型、应用、多模态以及当下最火的机器人。
整个行业在寻求应用落地的过程中,领域模型应运而生,有关于通用大模型跟领域模型谁更有价值的讨论仍未停止。有人认为通用大模型只是提供一个底座,具备大学生的智商,而要想成为一个专业领域的研究生,则需要给它投喂更多领域知识,专门训练一个领域模型;但也有人断言随着模型不断迭代,一个通用模型也能表现出很强的专业能力,这在代码生成领域已成事实,例如Claude 3.5 Sonnet 在代码能力上可媲美一些垂直代码模型。
而对自研国内首个UI多模态大模型的AI设计工具Motiff妙多(下简称“Motiff”)来说,其副总裁张昊然告诉AI科技评论,在寻找商业化落地的过程中,大模型厂商会选择更大业态、更多领域数据的商业场景去做刻意训练,但UI不在这个领域范畴。
同时在他看来,Scaling Law对绝大多数专业领域是失效的,因为专业领域没有那么大量级数据,自然不能用Scaling Law去评估,他认为如UI这样的领域模型应该存在长期价值,通用大模型很难在一个时间周期内去赶超领域模型。
不久前,在IXDC2024国际体验设计大会上,AI设计工具Motiff推出了自主研发的UI多模态大模型Motiff妙多大模型,这是国内首个UI大模型。
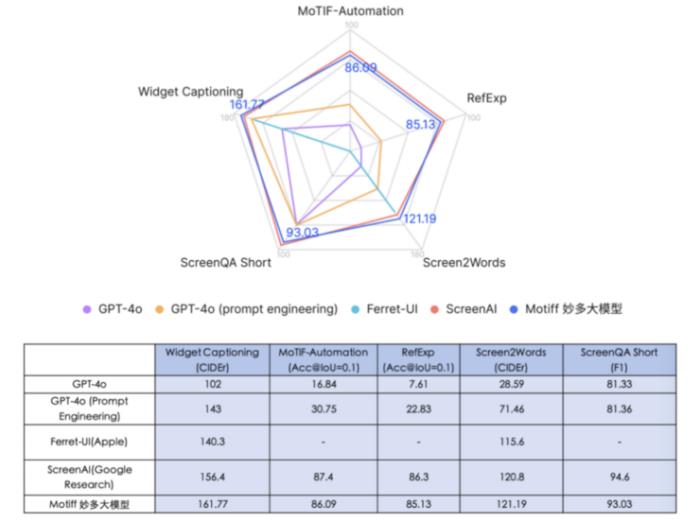
Motiff妙多大模型具备较强的UI理解能力和执行开放式指令的能力。在五个行业公认的UI能力基准测试集中,Motiff妙多大模型的各项指标均超过了GPT-4o和苹果的Ferret UI,同时在Screen2Words(界面描述与推断)和Widget Captioning(部件描述)两大指标上也超越了谷歌的ScreenAI,其中Widget Captioning指标高达161.77,刷新SoTA。与Ferret UI、ScreenAI等现有解决方案相比,Motiff妙多大模型能灵活地根据上下文理解界面元素,达到“设计专家”水平,最接近人类对UI界面的理解和表述结果。
Motiff孵化自猿辅导,这家教育界的独角兽,在 2021年又开始开拓了一些新的商业方向,猿辅导内部尝试了羽绒服、月子中心、咖啡等多项业务,这款产品便是其中之一。张昊然便是从那时开始负责Motiff。
近日,Motiff副总裁张昊然在IXDC2024国际体验设计大会上接受了AI科技评论的访谈,跟我们分享了Motiff多模态大模型背后的训练故事、商业模式的选择、对出海的认知等等思考。
以下是为对话实录,稍经整理:
1 Motiff多模态大模型的训练过程AI科技评论:一家主营业务是教育培训的公司,为什么会来做UI多模态大模型?
张昊然:在21年10月,我们写下了Motiff的第一行代码,结合团队的能力、擅长的事情,最终定位到AI结合专业工具可能会是一个新机会,往下细拆选择了UI设计领域。
整个决策过程经历了宏观到微观,选择SaaS,选择专业工具,选择产研领域的专业工具,选择UI设计。
AI科技评论:当时看到的整个UI设计的市场规模是多大?
张昊然:当时的预测和今天看到Figma 的结果可能差不多,但今天对总规模更乐观了。
Figma是领域头部产品,前年的营收是4亿美金,去年是6-7亿美金,今年预测大概能到10亿。最大的巨头即将获得了10亿美金的ARR,随着AI技术的发展,我认为总体市场规模会更大。
AI科技评论:什么时候开始做Motiff妙多大模型?
张昊然:我们其实不是ChatGPT出来后才开始做妙多这个产品,21年 GPT-3 还没有出现,当时用了很多AI1.0时代的技术,例如深度学习,已经产生了很高的效率。当时验证了这个方向是可行的,我们认为AI是这个工具到下一个代际的重要变量,大模型只是产品迭代过程中一项新技术出现。所以大模型对我们来说并不是所谓的新创业机会,而是考虑新技术的出现如何增强当下的产品。
AI科技评论:为什么不选用通用大模型来进行微调的方式,而是要选择自研?
张昊然:通用大模型在处理UI相关任务时,表现是弱的,这是事实。比如说让它去认知一个UI界面,通常只能到比较表层的认知,很难从UI专业角度去理解,通用模型没有太多专业领域的知识输入跟训练,所以我们需要去训一个专业模型来处理UI设计任务。
AI科技评论:哪些UI场景已经可以用AI来实现?
张昊然:我们把整个UI的场景分为三个部分,第一个部分是设计师日常的工作,也是一个可抽象、可量化的操作,比如说要完成一个设计稿,需要多少步骤,这些步骤中可以找到一些规律,这里面有非常多是可用AI解决的,原因是这些操作有特别大的共性跟重复性;
第二部分是团队协作,设计团队之间的协作,设计团队跟研发团队的协作,大家在协作中需要共同面对的问题是保证设计的一致性。一致性怎么理解?例如今天我们看到的微信界面,背后可能有超过100个设计师在做同一款产品的不同模块,那怎么保证整个团队不同的人做出的东西是风格统一?这很关键。一致性需要一套实践去约束,目前最广泛的实践是通过设计系统的方式,而这里面有大量低效的工作,Motiff的一个方向就是对设计系统的工作流提效。
第三部分是针对大模型出现后对整个UI领域生产力的改变,即生成UI的能力。这是大模型出现后才带来的改变,以前的AI技术并不能实现生成功能,大模型对自然语义、对图片的理解能力比原来更强,输出也更有结构性,这使得AI在生成UI的领域有了更多新的可能。这是我们研究的一个方向。
AI科技评论:这对应了Motiff的三个模块,AI工具箱,AI设计系统,AI生成UI。
张昊然:是的。AI生成UI一直是我们研究的一个大命题。
AI科技评论:Motiff的训练选择的是最经典的整合专家模型,是参照了别的多模态模型的训练过程吗?
张昊然:当然有大量的学习跟参照。这源于开源技术的迅速发展,开源才使得更专注领域的团队去训练领域模型变得更可能;市面上也有非常多成功的领域模型给了我们很大的信心,像医疗、法律领域的。大家的逻辑都一样,用更多的领域知识和数据再训练,让领域模型更好为行业服务。
AI科技评论:您是产品背景,您是从什么时候开始关注大模型的?
张昊然:从GPT-3进入公众视野的时候。看到非常惊艳,虽然我没办法去训练实操,但是有更多的精力去尝试应用。
AI科技评论:您看论文吗?
张昊然:去年可能是我有生之年看过最多的一年。创业者要有意愿去follow前沿,因为这是一个非常大的技术革命。
AI科技评论:在整个Motiff妙多大模型训练过程中遇到的最大困难是什么?
张昊然:最大的困难是数据的有效性验证。我们从非常多的来源收集了近千万的数据,判断哪些数据有用,哪些数据有害,是比较困难的。一般来说验证数据有效性的方法是消融实验,但是大模型的训练成本太高,所以没办法每个数据消融。
AI科技评论:Motiff是一个自研模型,但是底层的视觉模型和语言模型都是拿的开源或者别家的,自研的部分在哪里?
张昊然:关键问题是我们如何定义“自研”。在我的定义里,如果我们自己研究出一个新的东西,跟别人不一样,能带来价值,这个自己研究的过程可叫“自研”。
从这个角度,Motiff 妙多大模型虽然借鉴了很多行业通用的训练方法,但要解决问题的过程是我们自己研究的,最终也产出了不错的交付成果,我认为这就是自研。
某种程度上,一辆畅销的电动车的发动机不是自己的,电池也不是自己的,很多东西都是组装的,这辆车叫自研吗?我认为当然也是。
AI科技评论:领域数据是UI多模态大模型表现优劣的关键因素吗?
张昊然:是,我们拥有高质量的数据,这是一种长时间的积累,对于所有的AI工程,数据其实是一个非常强的累积工作,得靠很多方式去收集、标注,如何组织一个规模化的团队、如何提高标注的生成质量,这些都是AI领域的核心壁垒。
AI科技评论:数据的处理依然是难点?
张昊然:标注的方法中标注的维度是不断变化的,以及对数据质量好坏的评估,这两件事是难点。因为标注维度会随着应用场景的变化去变化,可能第一次想到的标注维度已经够详细了,但面向一个新的产品设计问题时,又发现原来的标注维度是不够的。
这是一个值得大家去反复思考、完善的事情,目前看来第二点才是更难的点,因为模型训练中数据好的好坏、大家各自评价标准不同,模型的效果就不同,这个过程非常主观,我们也找到了一些方法反复去评估、提升。
AI科技评论:获取千万量级的预训练数据花了多长时间,遇到哪些困难?
张昊然:因为 Motiff 在 AI 工作上有持续的积累,所以从几年前我们就开始收集 UI 界面相关的数据了。此外,Motiff 也积累了很多的 UI 专家模型,这又进一步节约了数据收集的时间。
一个困难是高质量的手机界面量级极小,想获得训一个大模型级别的手机界面数据是困难的。
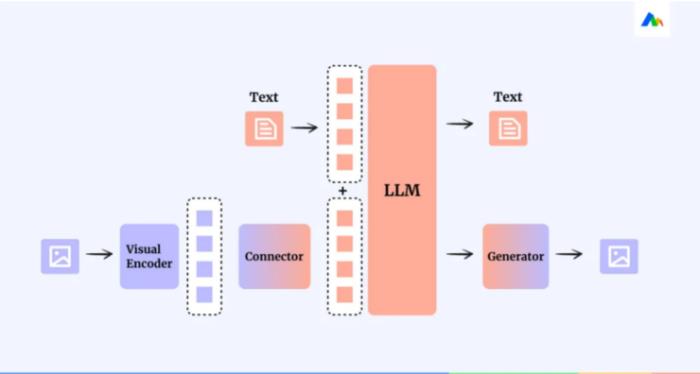
AI科技评论:在多模态大模型训练中,要将不同模态之间的数据有效地融合非常困难,妙多如何克服这个难题?视觉语言如何转换成自然语言?
张昊然:从模型角度来说,需要添加模态之间的转换器(Connector)。从数据角度。需准备模态对齐数据。从训练角度,则是固定专家模型参数,训练模态转换器(Connector)。
AI科技评论:在我们的模型训练过程中,为什么选择从第二阶段(对齐训练)开始领域迁移,而不是从第一阶段(独立预训练)就引入领域知识?
张昊然:在第一阶段就去做领域数据的训练是可行的,我们其实也在探索会不会更好,但它面临两个现实的问题,第一阶段去做成本巨高,因为训练量很大,不确定性也会很多;第二点是训练越接近最后一步,可控性越强,所以在对齐之后做领域的迁移训练,对模型的规训能力越强。
AI科技评论:打榜跟在实际生产环境中的表现相差多大?有投资人说现在如果有创业者说他的产品打榜排名多少,他们看都不会看。
张昊然:打榜跟实际生产环境中的表现有相关关系,但不是因果关系。我们的产品更在意的是在专业领域的任务实现是不是够好,而且打榜用的是公用的评测集,放到行业中会有一定的滞后性。
AI科技评论:UI这块的评测集的滞后性很大吗?
张昊然:至少我们现在关注的一些能力从专业角度来说非常重要,但其实都还没有被纳入公开的评测集中。
例如,一些公开的评测集中,有对某个组件到底是什么、怎么使用的理解,但却没有对组件的分类、分类是否准确的评测,这是非常务实的一个需求,因为设计师在应用场景中会有组件归类的诉求,所以这是评测集跟实际需求的gap。
AI科技评论:为什么不在开源的UI MLLMs上直接微调一个领域模型?
张昊然:据我所知目前还没有开源的UI MLLMs。但如果有,我们选不选开源标准是看如何能让产品 效果更好,一个开源模型的封装往往更后置,我们对它的控制力会更弱,优化空间也更小,所以我们权衡后选择了最经典的整合专家模型这个方案。
AI科技评论:听您讲Motiff要对标Figma,但是Figma并没有加入太多大模型的能力,Motiff要从哪几个维度对标?
张昊然:其实不是对标,是革新,用AI能力去革新现有的设计工具,我们要做一个AI时代的设计工具,就要去看Figma定义了哪些,我们要看这些能不能重新定义,我们专注这件事。
AI科技评论:如何解决大模型带来的超高推理成本这一行业痛点?
张昊然:越大的模型推理成本越高,但并不是所有任务都需要超大的模型。构建不同尺寸的多模态模型,可以缓解这个问题。此外,在功能设计上也有一些巧妙规避推理的方法。推理成本高应该是每个大模型应用的痛点,但是结合 Motiff 更灵活的 AI 产品形态,Motiff妙多大模型有更多更灵活的选择。
AI科技评论:您觉得大模型时代的产品跟上一个时代的产品有什么不一样吗?
张昊然:挺多不同的,尤其是产品力完全不同,过去的AI产品往往解决的是一个领域非常小的场景问题,是用大数据、海量的数据去解决小问题,例如深度学习里最典型的例子就是人脸识别。
产品思维也在发生改变。现在整个行业处于先训一个模型,再找应用场景的状态,有时候可能发现问题后再去匹配模型的状态。做AI产品的成本也大幅下降。以前得确定技术能商业化、评估有多大收益,才能下定决心去做那么大规模的训练。但是现在大模型训练出来后被调用的成本是低的,这给了行业很多新机会。人们能够更低门槛、更大限度、更高频次地去调用AI能力,从而去产生更多产品创新。这是大模型时代带来的本质的不同。
2 国内TOB、海外TOCAI科技评论:在商业模式选择上一开始就说要TOB?
张昊然:其实没有。对于这类协同SaaS的用户拓展来说,总结下来有两套路径,一个是PLG(Product Led Growth,产品驱动增长)一个是SLG(Sales Led Growth,销售驱动增长 ),这俩其实不矛盾,可能是一体两面或者相辅相成去看待。
目前专业工具的付费群体分为C和B,B就是企业付费给员工使用,C的主要市场来源是个体设计师或者小型团队,例如Freelancer,这部分在国际化市场中的体量非常大。
国内的Freelancer在UI领域偏少,更多还是在企业工作,所以我们目前的阶段性做法是海外主要TOC,国内TOB会重一点。这是阶段性的选择,不是一成不变的,原因是,第一点我们觉得Motiff在国内的产品力竞争优势非常明显,第二点是国内没有C,那么国内只能TOB。
AI科技评论:海外TOC的增长策略是什么?
张昊然:海外TOC更符合我们团队现在的能力,因为一个中国公司出海要靠销售去打,大部分公司其实不具备这个能力,或者说过往的经历证明了这样的团队是极少的。
AI科技评论:大多数技术方向都是这种状况吗?
张昊然:当然也有例外,WPS近些年在某些国家的出海TOB据说做得不错。但也有一些其它国产的协同办公产品,有钱有组织力,却铩羽而归。关键还是能否找到匹配的区域性市场,以及在区域性市场里还具备较强的企业连接能力。
AI科技评论:Motiff最初就决定要出海吗?
张昊然:是的,首先出海意味着你的市场天花板可能会高几十倍,从一片湖到真正的一片海。其次,越工具化的东西越适合全球化,内容或业务属性越强的越难,这是个共识。Motiff是个工具性很强的产品,所以它天然适合国际化。
AI科技评论:Motiff国内外版本有什么不同?
张昊然:功能层面没什么不同,同时海外和中国在支付、服务、安全性上也有一些差异化诉求,我们会针对化满足。
AI科技评论:就像飞书一样,国内的版本很多都是按照国外的用户使用习惯来设计的,Motiff没有这样的设计差异吗?
张昊然:就像刚才说的,UI并不是一个强内容或业务属性的行业,相反,它的工具属性极强,就像“全世界的扳手都长得差不多”。
AI科技评论:随着这一波生成式AI爆发,中国AI企业出海面临的共同问题有哪些?
张昊然:我可能不具备能力来总结共同问题,我觉得企业各有各的问题。挑战往往是针对领域、用户场景而不同,如果一定要说共性问题,海外直接建立销售的能力对大多数企业来讲是很难的,在这种情况下就要考虑TOC。
AI科技评论:Motiff海外的团队建设是怎样的?
张昊然:我们在新加坡、北美有分公司,但更多还是从运营的角度去考虑,而不是销售角度。
AI科技评论:出海战场主要是新加坡?
张昊然:我们并不限制国家,Motiff从发布到现在两个月,在十多个国家已经积累了不错的用户量,在不同国家表现也有差异。还是回到工具属性的问题,大家的gap是小的,其实更多是看有没有更高效或者ROI(投资回报率)好的渠道,能获得更多曝光。
AI科技评论:外界一直流传着一种预判是随着通用大模型的不断发展,垂直模型和领域模型未来不需要了,是一种伪命题,您怎么看?
张昊然:这有可能会发生,各种论断各不相同,我当下的认知是有部分的模型应该存在长期价值,通用大模型很难在一个时间周期内去赶超领域模型。
这背后的原因非常朴实,对于通用模型来说,很难拿到高质量的专业领域数据,一个模型训练的壁垒还是训练数据。通用大模型的好处是数量多,大力出奇迹,但是Scaling Law对绝大多数专业领域的效果都是失效的。原因是专业领域没有那么多数据,不符合大力出奇迹。所以没有那么大量级的数据时,就谈不上一个所谓的Scaling Law。
现实世界中的数据分布往往越不专业的越容易获得、数量越多,越专业的数据越稀疏。有没有一些领域会被大模型卷到呢?我觉得会,现在行业面临最大的挑战是找不到商业化应用的场景,大模型厂商首先会选择有更大商业业态、更多领域数据的场景,但目前UI不在这个领域范畴。
AI科技评论:在您看来,大模型带给UI领域怎样的影响?
张昊然:我们刚开始做Motiff这个项目时,还没有大模型技术,当时用的是深度学习等方式去解决任务式的问题,我们都觉得它在效率上已经足够好了。大模型出现后,它是技术层面的大变革,使得原来很多不可想象的事情变为可能,现在的界面生产工作流是产品经理、UI设计师、研发的整个流程,大模型能有效缩短现有的工作流。
人很多时候受限于效率跟时间,当技术无限压缩生产流程,使得意图到实现的路径变短,最终生产力、生产关系也都会发生改变。「」

相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









