

 新火种
2024-08-21
新火种
2024-08-21 


豆包版《Her》升级上新!随时打断,交流自然,还是开箱即用的那种
豆包大模型应用落地,又有新进展。
8月21日,火山引擎在AI创新巡展活动上发布了豆包大模型的一系列产品升级。
据活动现场披露,最新版豆包大语言模型的综合能力相比三个月前首次发布时提升了20.3%:
在六项关键能力评测中,角色扮演能力提升38.3%,具备了更强的上下文感知,让对话情境更连贯、角色更拟人化;语言理解提升33.3%,包括信息分类和抽取、总结摘要、阅读理解和问答等能力增强。此外,模型在长文任务、数学、专业知识、代码能力上也有不同程度提升。

值得关注的是,此次活动还发布了豆包大模型的一系列语音能力升级。豆包大模型团队的Seed-ASR、Seed-TTS研究成果(论文见文末),已成功应用于豆包语音识别模型和语音合成模型。在此基础上,火山引擎整合了RTC技术(实时音视频),全新发布对话式AI实时交互解决方案。
此方案让用户不仅能用语音与AI进行交谈,还能像平时说话一样、在对话过程中适时打断或插话,整体对话质量不受影响。经过升级后的AI声音相较以往而言更具表现力和感情色彩,对话也因此更自然、更真实、更流畅,让大模型交互体验更强。

现场,火山引擎还携手多点DMALL成立零售大模型生态联盟,基于豆包大模型打造零售AI解决方案。首批联盟成员包括物美集团、抖音电商、抖音生活服务、百胜、麦当劳、中国飞鹤、海底捞、居然之家、南7-11、重庆百货、百果园、波司登、天虹、三得利、绝味、名创优品、NielsenIQ、电通等。
自然流畅的AI实时语音应用,一站式搞定搭载火山方舟大模型服务平台,通过火山引擎RTC实现语音数据的高效采集、处理和传输,并深度整合豆包·语音识别模型和豆包·语音合成模型,简化语音到文本和文本到语音的转换过程,火山引擎对话式AI实时交互解决方案,提供优秀的智能对话和自然语言处理能力,帮助应用快速实现用户和云端大模型的实时语音通话。
豆包·语音识别模型:更高的准确率及灵敏度,更低的语音识别延迟,支持多语种的正确识别。豆包·语音合成模型:解锁「豆包」同款音色,提供自然生动的语音合成能力,善于表达多种情绪,演绎多种场景。火山方舟:提供模型精调、推理、评测等全方位功能与服务,提供丰富的插件生态和AI原生应用开发服务,全方位保障企业级AI应用落地。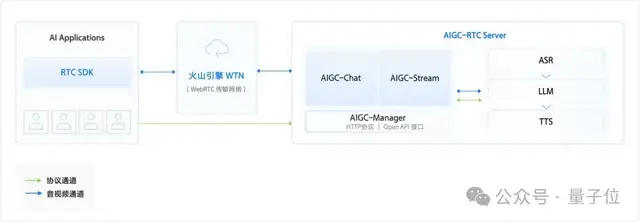
△对话式AI实时交互服务方案架构
开箱即用快速搭建,只需调用标准的OpenAPI接口即可配置所需的语音识别(ASR)、大语言模型(LLM)、语音合成(TTS)类型和参数。而火山引擎AIGC RTC-Server负责边缘用户接入、云端资源调度、文本与语音转换处理以及数据订阅传输等环节。整体简化开发流程,让企业应用更专注在对大模型核心能力的训练及调试,加速AI实时语音场景创新。
随时打断,交流自然要让与AI的交流像和朋友一样自然,随时打断甚至直接插话,关键在于:当用户和AI同时说话时,如何解决互相干扰的音频“双讲”现象。
火山引擎RTC基于成熟的音频3A处理技术,针对“双讲”通过传统回声消除算法和深度学习算法的结合,不仅有效去除回声,还能避免用户语音被过度处理,确保云端语音识别(ASR)能准确捕捉和识别用户的语音信息。
此外,火山引擎RTC通过简化算法提高处理速度,避免因算法复杂性带来的额外延时。
实时秒回,全球畅聊火山引擎RTC依托于WebRTC传输网络(WTN),优选全球海量优质节点,实现全球用户智能接入和音视频数据超低延时传输,在复杂的网络环境下具有强大的抗弱网能力,即使在高达80%的数据包丢失率下,也能确保音频传输的稳定和质量。
同时,火山引擎RTC结合云端语音识别流式处理,优化链路延迟,端到端响应延时可低至1秒。此外,火山引擎实时信令RTS可提供稳定可靠、低延时、高并发的信令收发能力,可对文字信令高效传输。
不受限于AI服务部署区域,用户无论身处何地,是语音交流还是文字对话,都可以享受极低延迟、流畅的AI交互体验。
产品融合,高效架构在方案中,客户端提供音频帧级别的语音活动性检测(VAD),可以精准检测出音频信号中何时有人正在说话,何时是静默状态。帮助整体语音系统更有效地处理语音输入,更准确地识别和理解用户的指令或话语,减少误识别。同时,避免对无意义的背景声进行处理,从而节省计算资源,提高系统的整体效率。
当前人工智能领域创新和突破正以前所未有的速度发生,几乎每周都有新的进展。AIGC交互形态和规模也在快速发展中,如从文字到语音再到视频等多模态,从1对1到多人多Agent互动。火山引擎对话式AI实时交互服务在支持实时语音基础上,也在探索拓展多模态视频对话和多人群聊等场景,帮助开发者能够快速迭代和创新,不断推出新的应用场景和玩法。
灵活、多样化的接入方案对于追求快速部署AI实时语音功能的企业来说,火山引擎提供的一站式解决方案,让企业能够专注于打造核心功能和创新,而不必深陷底层技术的细节。此外,火山引擎也提供多样化的接入方案,以满足不同企业在开发应用时的具体需求。以下是另外两种接入方案:
自集成方案:企业可以利用火山引擎RTC的音视频采集处理能力、云端媒体服务和音视频数据传输技术,结合ASR、LLM以及TTS等技术构建一个完整大模型语音处理流程,实现更自主、灵活的架构设计。WebRTC传输网络(WTN)方案:对于在客户端拥有自主研发音视频技术的企业,火山引擎提供了基于WebRTC标准协议构建的传输网络(WTN)。通过接入WTN,企业能够轻松获得全球范围内的超低延迟、稳定可靠的实时音视频传输服务,提升端到端多模态大模型的响应效率。通过这些方案,企业可以根据自己的技术栈和业务场景,选择最合适的接入方式,实现高质量的AI实时语音场景。目前,火山引擎提供的AI实时语音能力已在国内TOP级的AI虚拟人物聊天产品中应用落地,为众多用户带来全新的互动体验。
Seed-TTS及Seed-ASR技术详情:
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models论文链接:https://arxiv.org/pdf/2406.02430Demo展示:https://bytedancespeech.github.io/seedtts_tech_report/
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition论文链接:https://team.doubao.com/zh/publication/seed-asr-understanding-diverse-speech-and-contexts-with-llm-based-speech-recognition?view_from=researchDemo展示:https://bytedancespeech.github.io/seedasr_tech_report/
*本文系新火种获授权刊载,观点仅为作者所有。
— 完 —
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










