

 新火种
2024-05-28
新火种
2024-05-28 


摩尔线程国产GPU重大里程碑!千卡集群完成30亿参数大模型实训
5月27日消息,摩尔线程、无问芯穹联合宣布,双方已经正式完成MT-infini-3B 3B(30亿参数)规模大模型的实训,基于摩尔线程国产全功能GPU MTT S4000组成的千卡集群,以及无问芯穹的AIStudio PaaS平台。
本次实训充分验证了夸娥千卡智算集群在大模型训练场景下的可靠性,同时也在行业内率先开启了国产大语言模型与国产GPU千卡智算集群深度合作的新范式。
据悉,这次的MT-infini-3B模型训练总共用时13.2天,全程稳定无中断,集群训练稳定性达到100%,千卡训练和单机相比扩展效率超过90%。
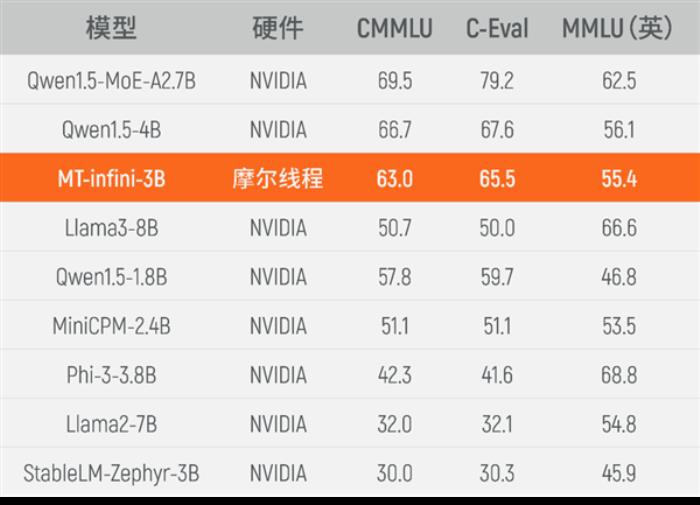
目前,实训出来的MT-infini-3B性能在同规模模型中跻身前列,相比在国际主流硬件上(尤其是NVIDIA)训练而成的其他模型,在C-Eval、MMLU、CMMLU等3个测试集上均实现性能领先。
无问芯穹正在打造“M种模型”和“N种芯片”之间的“M x N”中间层产品,实现多种大模型算法在多元芯片上的高效、统一部署,已与摩尔线程达成深度战略合作。
摩尔线程是第一家接入无问芯穹并进行千卡级别大模型训练的国产GPU公司,夸娥千卡集群已与无穹Infini-AI顺利完成系统级融合适配,完成LLama2 700亿参数大模型的训练测试。
T-infini-3B的训练,则是行业内首次实现基于国产GPU芯片从0到1的端到端大模型实训案例。

就在日前,基于摩尔线程的夸娥千卡集群,憨猴集团也成功完成了7B、34B、70B不同参数量级的大模型分布式训练,双方还达成战略合作。
经双方共同严苛测试,兼容适配程度高,训练效率达到预期,精度符合要求,整个训练过程持续稳定。

相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










