

 新火种
2024-04-22
新火种
2024-04-22 


直播网友AI写歌征婚,实测最新登榜音乐SOTA模型:免费无限次,一键生成
继Suno、Udio带火AI音乐生成大模型之后,第一个国产“音乐版Sora”,终于来了!
话不多说,直接“开箱”听效果,看看到底怎么事。
我们开始就上一下难度,让它根据《高速运转的机械》这个网络段子来做首个歌。
这个任务的难度在于,所有的文字并非是歌词那般押韵、工整,并且逻辑也比较混乱。
AI先是采用男声Rap的方式把气场打开,中间还夹带了一小段方言,最后女声演唱部分的音乐也是颇有“黄龙江一派”的气势。
嗯,熟悉的画面这不就来了。

若是让它爆改一下文字较为工整的古诗词,AI又该如何接招?
有请李清照的《声声慢》:
这段音乐整体是现代风格,先是有一段男声Rap,咬字和节奏感上依旧是比较过关。
但最令人意想不到的是,在第23秒的时候,AI直接来了个峰回路转,直接“杀”进了女声,音乐的情绪也放慢了下来,颇有“怎一个愁字了得”的意味。
当然,用粤语、英语演唱抒情歌曲,这个AI也是不在话下,甚至连颤音、和声、和弦都能生成得惟妙惟肖:
而已经体验过Suno等产品的小伙伴可以听出来,这个AI在处理中文的时候是拿捏得比较自然的。
那么这个国产“音乐版Sora”,到底是什么来头?
不卖关子,它就是由昆仑万维在4月17日正式发布的天工SkyMusic,划重点:

效果听起来还算不错,那么操作上是否会很麻烦呢?不,巨简单。
简单2步就能做首歌
目前,SkyMusic已经集成到了手机上的天工APP,入口就在主页顶部的“音乐”一栏中。
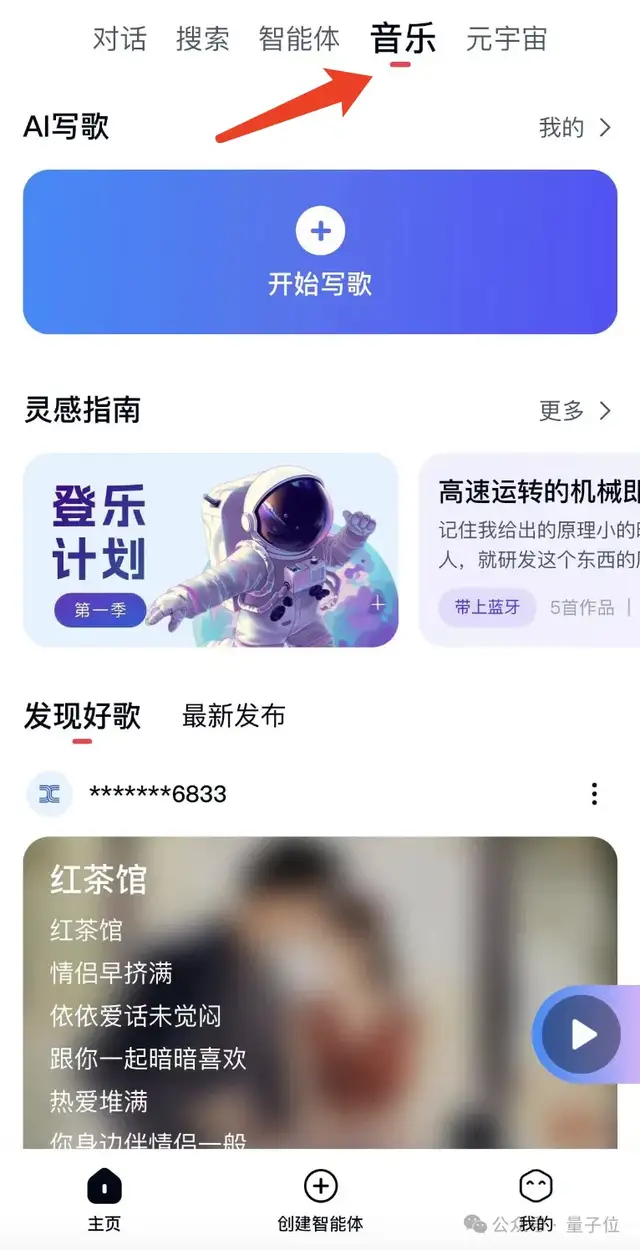
要想生成刚才那样的音乐,只需点击“开始写歌”就可以了。
在接下来的界面中,正如上文所言,你只要执行2个操作即可:
填写歌词(300字内)选择参考曲目
如果在写歌词的过程中没有灵感,你还可以通过“AI写词”的功能让大模型给你帮忙哦~
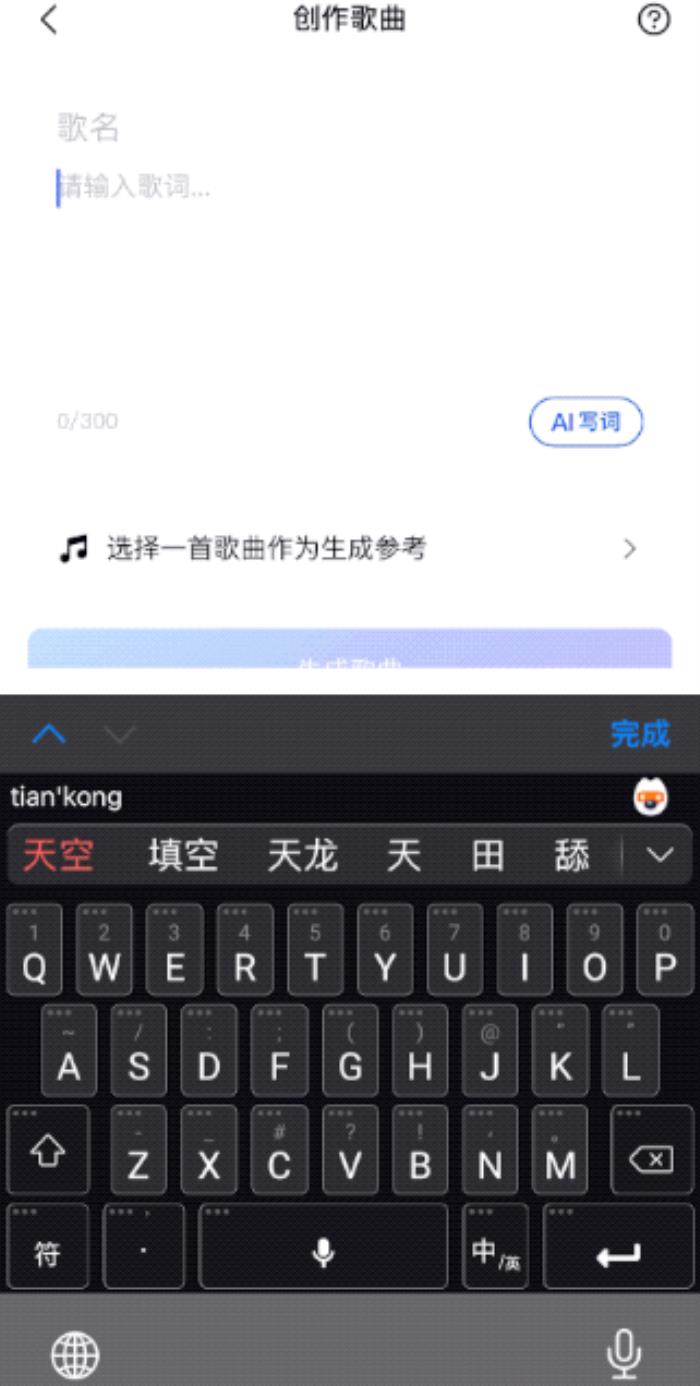
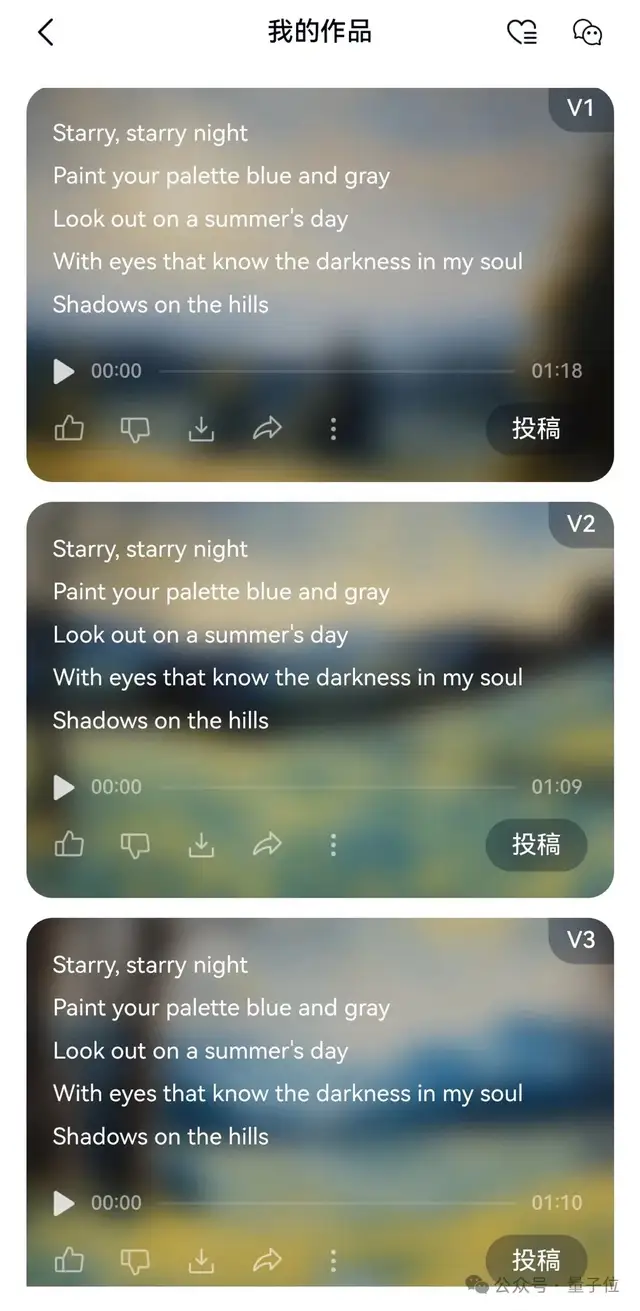
最后,点击底部的“生成歌曲”按钮,大约1到2分钟左右(亲测),就会出结果了。
而且还不是只有1首,是直接给到3个完全不同的版本!
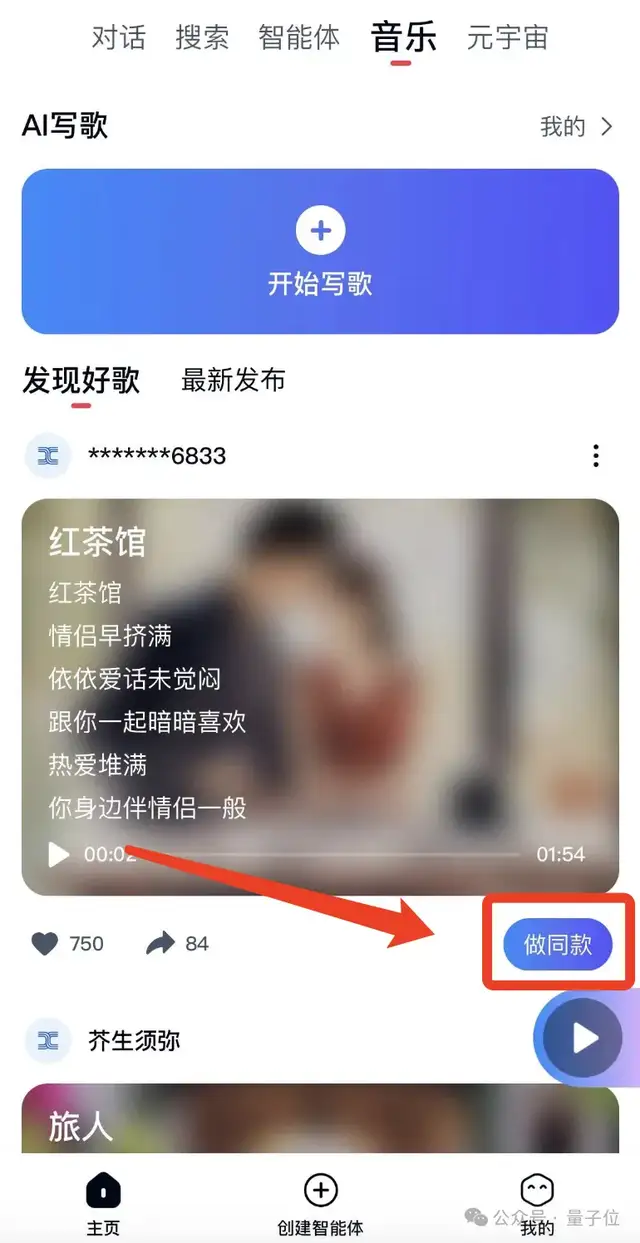
除此之外,在天工APP“音乐”栏目的下方,也有展示用户筛出来的AI作品。
如果你在听完某首歌曲之后觉得效果不错,也想尝试生成类似风格的音乐,可以点击旁边的“做同款”按钮,只需填写歌词就能再生成一首不一样的歌曲了。
从目前的结果来看,天工SkyMusic可以支持生成80秒左右时长的歌曲;不过一个好消息是,昆仑万维表示马上就会开放3分钟版本了~
而也正如刚才所言,天工SkyMusic是国内首个“音乐版Sora”,并且也取得了不错的效果。
如此又快又稳,昆仑万维又是如何做到的呢?
全球首个公开的技术路线
在AI生成音乐这件事上,即使是像Suno、Udio这样掀起热潮的玩家,也同Sora一样,并没有公开其背后的技术细节内容。
但值得一提的是,昆仑万维此次不仅是把AI生成音乐的产品给发布出来这么简单,更是做到了在技术上的“全球首家公开”。
在聊SkyMusic关键技术之前,我们需要了解的是,AI音乐生成从技术角度来看,可以分为两大流派:
符号音乐生成路线大模型音乐音频生成路线
符号音乐生成比较典型的技术就是MIDI(Musical Instrument Digital Interface,乐器数字接口),通常需要先对大量的乐谱做标注的工作,再对模型进行训练。
其结果最后得到是乐谱,而并非是真正意义上的音乐,还需要其它的工具来对乐谱做“善后”的工作。
虽然此前学术界也尝试了在MIDI这样的技术基础上,后期加入人声、乐器、旋律、音色等元素,但所得到的结果并不是非常理想。

而天工SkyMusic选择的大模型音乐音频生成,则是与之截然相反的技术路线——
是通过直接地学习来生成音频波形,并做到把乐器、人声、旋律、音量、音符等等元素都“一锅出”。但这条路线需要大量的研发投入和资金支持,让大多数人望而却步。即使强如Google、Meta等科技巨头,目前也没有发布在这条路线上的突破性成果。
同时,这条路线又分为Song、BGM、Speach三个细分领域;由于行业内普遍都在研究无人声的BGM领域,导致行业内对有人声的Song领域近乎没有很好的解决方案,更没有开源的方案可借鉴。
也正因如此,音乐届的“Sora时刻”才会来得比图像和视频更晚一些。
为了解决这两个老大难的问题,昆仑万维自研出一套架构来解决,它主要由Encoder、DiT和Decoder三个模块组成
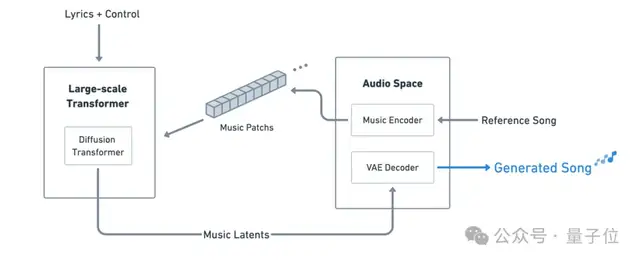
具体而言,其采用的架构可视为音乐音频领域的类Sora模型:
Large-scale Transformer:负责谱曲,来学习Music Patches的上下文依赖关系,同时完成音乐可控性;Diffusion Transformer:负责演唱,通过LDM让Music Patches被还原成高质量音频。
这也是天工SkyMusic能够支持生成80秒44100Hz采样率双声道立体声歌曲的关键所在。
在我们与昆仑万维的交流中,研究人员进一步表示:
从效果中来看,天工SkyMusic在音乐中的咬字(尤其是中文)、情绪、技巧等元素的效果也是达标的。
昆仑万维董事长兼CEO方汉和新火种CEO孟鸿在昨天的对话直播中,便现场展示了比较有意思的几个曲子。
例如把《道德经》和宝妈一天的“吐槽”喂给天工SkyMusic,它生成的音乐是这样的:
再如一位老人给孙女以征婚启事为主题生成的歌,和吐槽购物“买买买”的歌:
嗯,确实有点意思。
而天工SkyMusic的优异表现,源自他背后优异的底座大模型——天工3.0。
天工3.0已经发布,直接拿下两个业界之最:
最大规模:4000亿参数的开源MoE大模型国内第一:中国首个音乐AIGC SOTA(State of the arts,领域内最高水准)
先来看下天工3.0大模型在全球权威多模态性能测试基准MMBench上的评分:
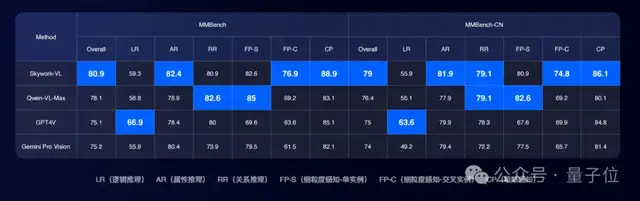
在全球权威多模态性能测试MMBench和MMBench-CN的评估中,天工3.0不仅在A属性推理、关系推理、细粒度感知-交叉实例、粗略感知四项性能拿下第一,综合评分更超越GPT-4V、Gemini Pro等知名文本大模型。
同时昆仑万维还将将天工3.0“上架”自家的天工APP。
效果怎么样?一言蔽之:
更聪明:技术知识能力提升20%,数学/推理/代码/文创能力提升30%更独立:独立规划、调用、组合外部工具及整合信息来完成复杂需求更全能:提升了专项Agent应对复杂需求的能力多才多艺:内容创作能力全面升级,包括搜、写、读、聊、说、画、听、唱
例如“弱智吧Benchmark”难不倒天工大模型:
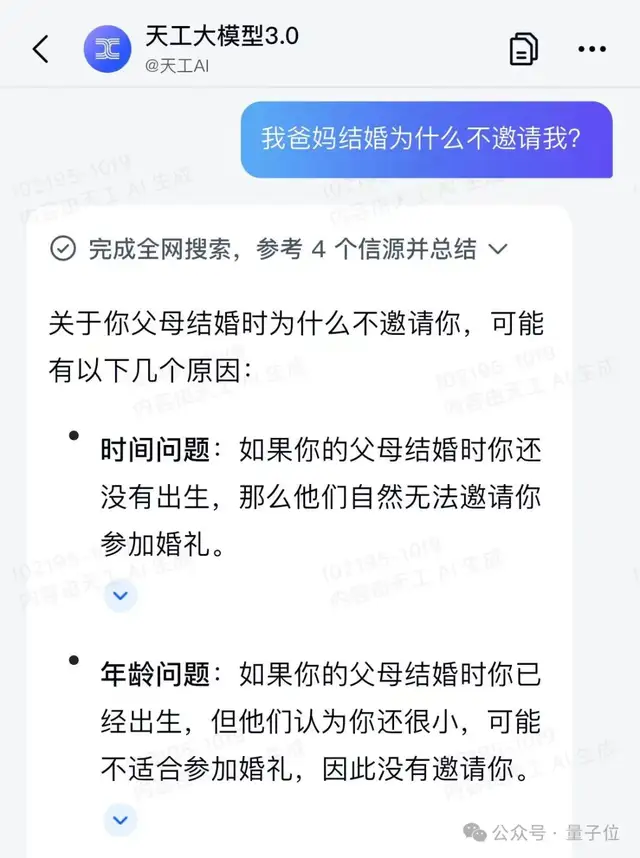
在AI搜索方面,天工3.0APP在调用能力上做了增强,甚至在“研究”模式下还能自动生成大纲、图谱、思维导图等内容。
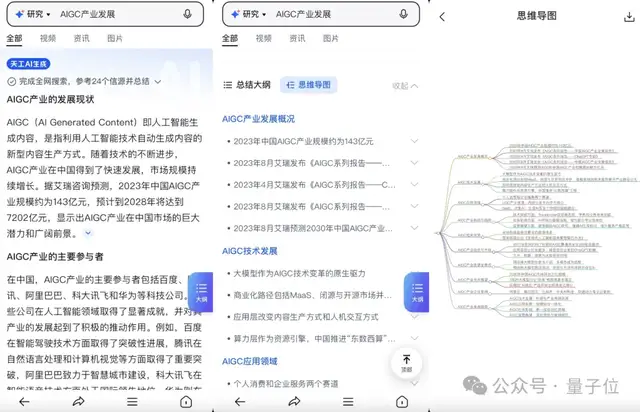
以搜索“AIGC产业发展”为例,现在的打开方式可以是这样的:
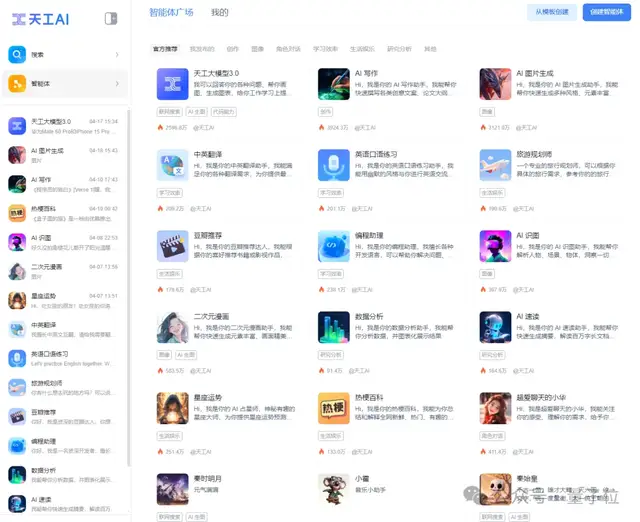
在大火的Agent技术方面,天工3.0也专门开设了“智能体”广场,用户可以自行构建专属的超强AI智能体,也可以在广场中pick自己想要的那一个。
以工作、生活都比较常用到的“扩图”为例,只需要丢给它一张图并提出要求,智能体就能生成4种不同的扩图效果。

总而言之,现在的天工3.0整体体验的最直观感受就是面面俱到,最前沿、最fashion的技术和应用统统都可以拥有。
最后,对于国内首发“音乐版Sora”这事,还有个话题值得聊一聊:
为什么是昆仑万维?
自从Sora问世引爆全球AIGC大热潮以来,昆仑万维绝对称得上是众多入局百模大战选手中的黑马。
此前,或许很多人对于昆仑万维的印象还停留在“游戏”、“出海”,但现在,“AIGC”已然成为它最鲜明的标签。
深入探究昆仑万维在AIGC领域的发展历程,我们可以清晰地看到其迅猛的发展步伐。
就在Sora发布仅一个月后,2022年12月,昆仑万维便发布了自主研发的全系列AIGC算法及模型,这套模型不仅具备先进的文本对话功能,还覆盖了图像生成、音乐创作、文本理解等多个模态领域。
从起步开始,昆仑万维就把“格局打开”,剑指多模态,而这正是今年AI产业最火热的赛道之一。
2023年4月17日,昆仑万维正式发布其自研的千亿级大语言模型“天工”,并于同年7月在天工APP上线。紧随其后,8月又推出了国内首款AI搜索产品——天工AI搜索,成为首批将AI大模型直接推向市场并服务于C端用户的企业。
在这场“AI一日,人间一年”的产业竞赛中,昆仑万维并没有安于现状,而是持续死磕技术:从公开测试多模态大模型Skywork-MM,到开源百亿参数级别的大语言模型天工Skywork-13B系列,继而又推出天工SkyAgents平台,并在今年2月,将国内首个采用MoE架构的大语言模型天工2.0免费向全社会开放。
而现在,正值天工大模型发布一周年之际,昆仑万维在2个月内将其迭代到3.0版本,再次拿下两个业界之最。
至此,也就不难回答“为什么是昆仑万维”这个疑问。因为昆仑万维始终坚守并践行“All in AGI 与 AIGC”战略,凭借敏锐的前瞻性和高效的行动力,始终站在AIGC技术发展的最前沿。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









