

 新火种
2024-04-02
新火种
2024-04-02 




最神秘国产大模型团队冒泡,出手就是万亿参数MoE,2款应用敞开玩
国内基础大模型创业公司,最后一位强实力选手终于正式来到台前。
它就是微软前全球副总裁姜大昕所创办的阶跃星辰。

一年前,新火种就对这位大牛的创业动向有所耳闻。
姜大昕在微软工作16年有余,曾任职微软全球副总裁,微软亚洲互联网工程院(STCA)首席科学家,全面负责微软必应搜索的技术研发工作。但就是这么一位风云人物,此番创业,却有不少令人费解的动作。
一来,他在微软职级极高,在微软混得风生水起,怎么想不开创业?
二来,阶跃星辰已经成立一年,但在百模群战的2023年,这家公司低调得近乎隐形。不仅没有主动对外发声,连新火种在圈内打听消息也探不得虚实。
现如今,大模型五虎已经初成格局,市场的注意力已经被瓜分不少,阶跃星辰的亮相才姗姗来迟——会不会晚了?
会者不晚。
一出手,阶跃星辰就亮出了自己蛰伏水下一年沉淀的成绩:
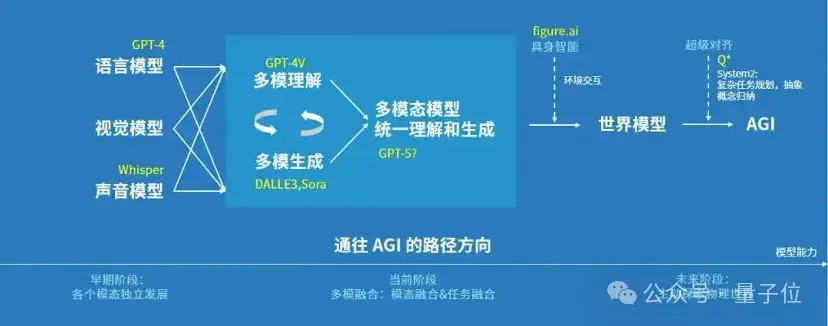
千亿模型有了,ToC产品有了,万亿模型在路上,且通往AGI的路也十分明确:
走一条“单模态—多模态—多模理解和生成的统一—世界模型—AGI(通用人工智能)”的路。
2款C端产品全面开放使用
阶跃星辰的产品是什么?
不玩虚的,一露面,阶跃星辰就直接带来了2款面向C端市场的应用:
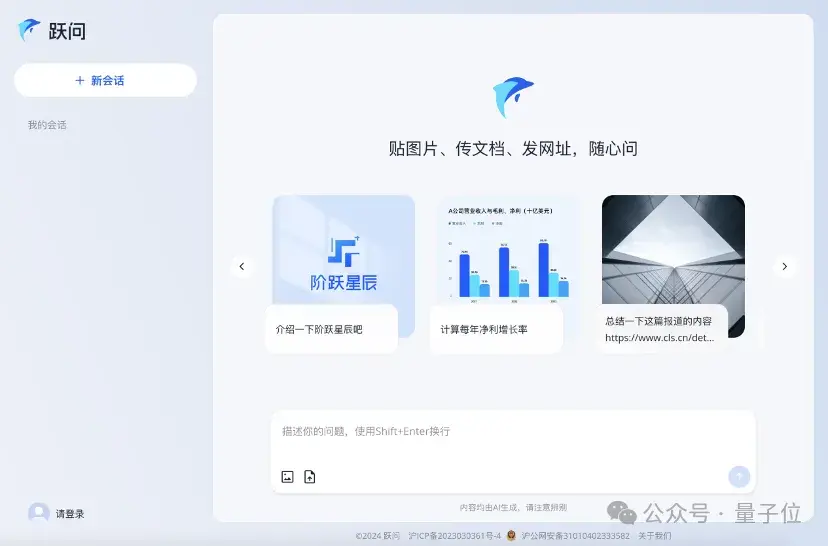
跃问和冒泡鸭,均全面开放使用。
它们一个是聊天类应用,定位个人效率助手。
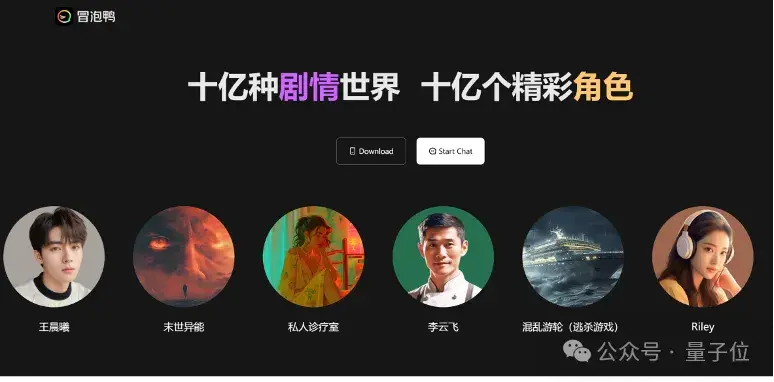
一个是AI开放世界平台,提供海量智能体,主打一个休闲娱乐。
具体效果怎么样?火速注册登录,新火种带大伙一睹为快。
先来看效率工具跃问。
第一轮基本问答我们让它对比一下ChatGPT和Claude的不同,重点:以图表形式呈现。
结果很快啊——
不止是开发公司、模型结构、文件读取能力这种硬性对比,也有专注方向、创新水平、安全性等偏主观的总结,一共14个小项,主打一个全面:

第二轮看看联网、信息检索能力。
和很多大模型一样,跃问的知识库信息只截止到2023年,后面的信息自然只能现搜了。
“今天的天气如何”太简单,我们直接问它马斯克脑机接口公司的进展如何。
结果,准确检索到1月份首位志愿者植入芯片的重大事件。

不过不知道是不是对“重大进展”这一词有不同理解,跃问没提几天前这位志愿者可以打游戏的报道。
我们追问之下,它倒也准确“交代”出来,包括志愿者名字、玩的什么游戏——除了游戏,下象棋7胜4负的事儿也一并提了。

第三轮:文件处理。
身处AI科技圈,最新论文和大佬教程我们自然要紧跟步伐。
先用OpenAI前科学家Karpathy不久前的《从头构建GPT Tokenizer》视频摸摸底。
直接给俩小时长的视频目前没有哪个大模型能直接解析,我们还是上传字幕文件。
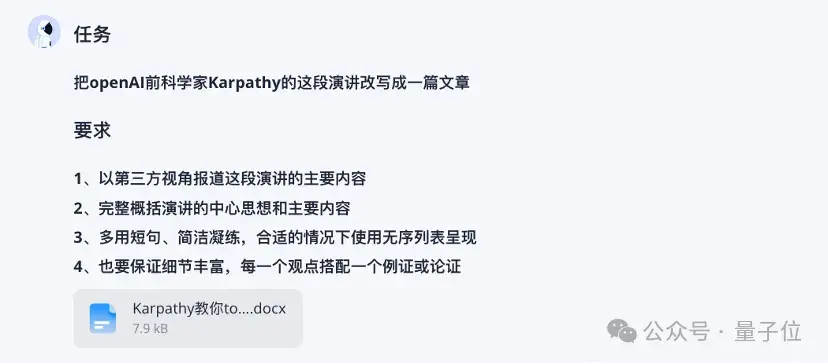
很快,全英文的内容跃问刷刷刷地就总结完毕:

仔细帮大家验证了,里面提到的例子都有都对。用起来相当给力。
对于论文来说就更简单了,直接给arXiv的链接就行。
一篇8.3万字(基本满足日常所需)的大模型微调方法论文(《AutoFT: Robust Fine-Tuning by Optimizing Hyperparameters on OOD Data》)丢进去,最核心的内容几秒便可知。
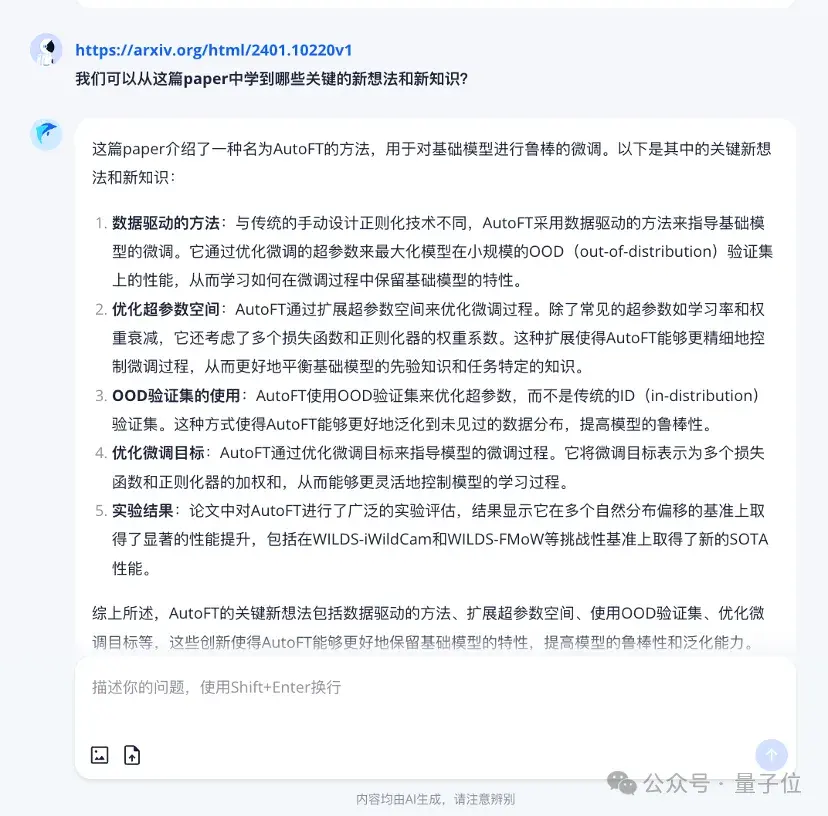
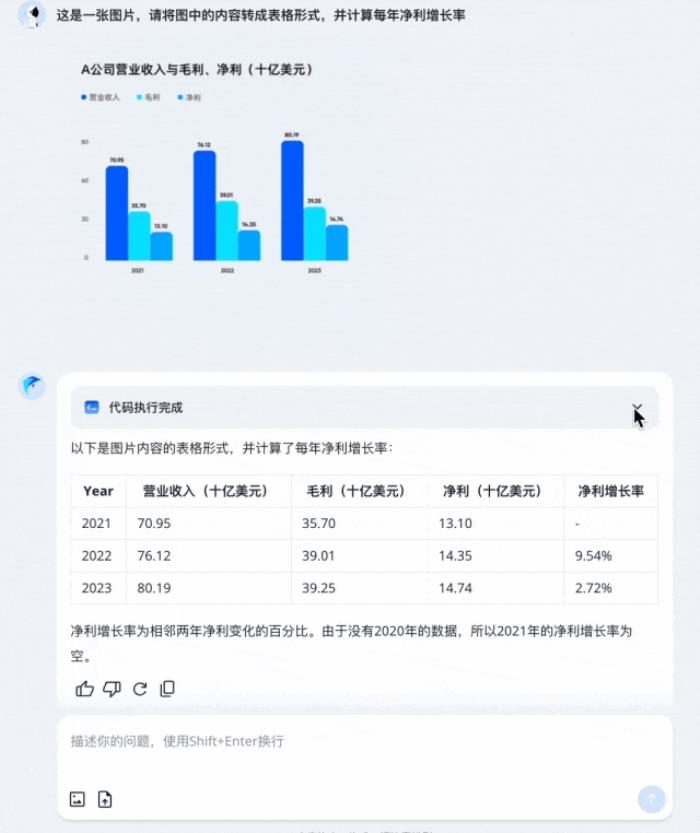
至于数据处理,如下图所示,图片转表格、净增长率计算,这种需要复杂逻辑推理的任务,跃问用代码的方式轻松解决。
最后,大家关心的多模态:
解读表情包,easy。

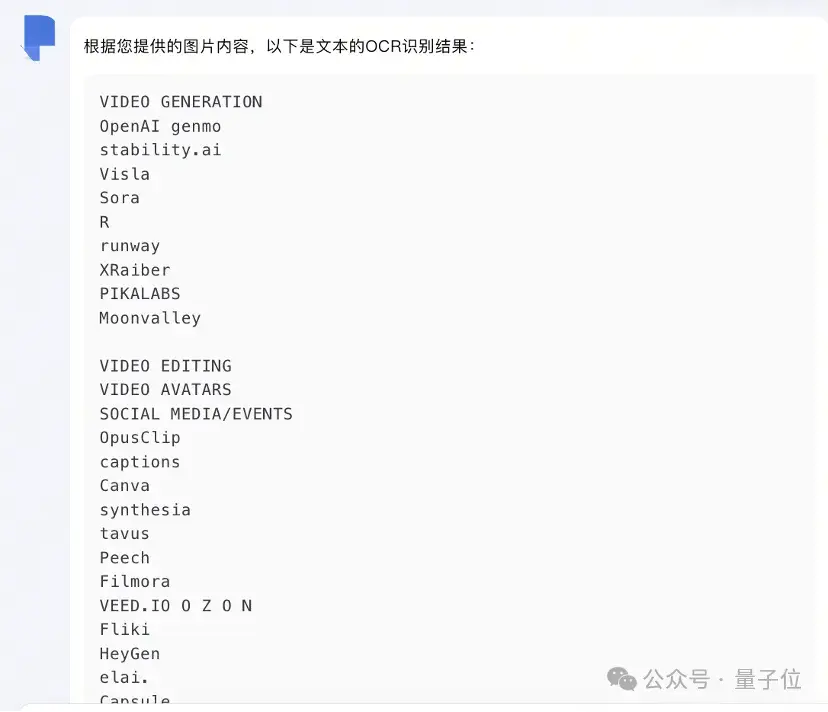
挑战一下投资机构整理的AI视频公司全景图。
别看logo们字体五花八门,跃问不仅迅速识别,还按照原图归门别类,阅读起来相当清晰。

相比之下,有同类选手不仅识别漏洞一个接一个,格式也完全顾不上。
总的来说,说起目前市面上的AI个人效率助手,已经不算少。但跃问,该有的功能不仅有,在多模态、长文本理解上也能做得更好。
并且最重要的是:免费!
使用起来没啥限制,目前也不用担心宕机、模型“太累了”回答不出问题(手动狗头),所以完全不失为一个优秀的平替。

至于冒泡鸭,它有app版也有web版。
平台上载有各种由多模态大模型驱动的智能对话体,可以进行各种有趣的对话、也可以探索有趣的剧情互动游戏(“戏精”们有福了)。

实在不够,还可以自己上手创建:
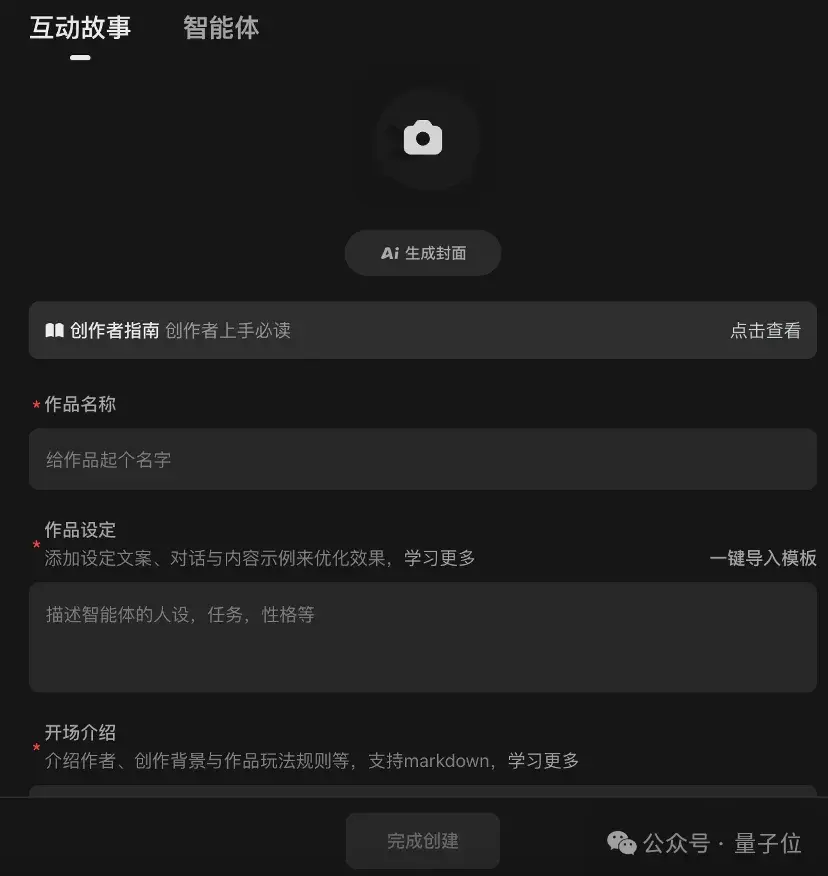
官方也提供了非常详细的上手文档,包教包会。

我们浅试了《逃离精神病院》这一剧情。

和AI的对话相当流畅、沉浸,让人一不小心抬头看时间才发现已经玩了好久。
(不瞒您说,新火种开了好几轮都没能成功逃出“精神病院”,难度还是有亿点点的。)

对于大模型产品,姜大昕表示:“我把模型和产品的关系比喻成灵魂和皮囊。大家一定听过一句话,好看的皮囊千篇一律,有趣的灵魂万里挑一。我们希望灵魂能更加有趣一点,才能显示出产品的不同。”
那么,跃问和冒泡鸭背后的“灵魂”——大模型们长什么样?
“铁人四项”攀登万亿参数模型
冒泡鸭和跃问的背后,是阶跃星辰已经成熟的两款千亿参数大模型。
该公司将其称为Step系列通用大模型,分别是Step-1千亿参数语言大模型,以及Step-1V千亿参数多模态大模型。

一路看来,阶跃星辰训模型的路,走得出奇的顺。
去年7月起,研发团队正式开始训练模型。
2个月后,综合性能超过GPT-3.5的千亿参数大模型Step-1,一次性训练成功。
在大模型遍地开花的时代,听起来拥有一个模型并不是什么难事,但短时间内一次成功,这种效率仍然令人咋舌。
姜大昕把原因归结于两点。
一是团队本身在AI领域有经验和积累;二是创业公司团队精悍,能对训练中遇到的问题及时沟通与反应。
这次成功极大地鼓舞了团队的信心,“这验证了我们的方法是正确的。”
再2个月后,也就是去年11月,千亿参数的多模态大模型Step-1V又告成。
Step-1V大模型可以精准描述和理解图像中的文字、数据、图表等信息,并根据图像信息实现内容创作、逻辑推理、数据分析等多项任务。此外,它还能理解视频中的内容。
上海人工智能实验室推出的大型模型评估平台“司南”(OpenCompass)多模态模型评测榜单显示,阶跃星辰研发的Step-1V位列第一,性能比肩GPT-4V。
“千亿参数的GPT-3.5模型是一个重要的分水岭。”姜大昕表示。
模型要达到GPT-4的万亿参数规模,各个维度的要求都上了一个台阶。
譬如,训练万亿模型需要等效A800万卡单一集群,进行高效稳定的训练;需要十万亿tokens的高质量数据;需要驾驭好新颖的MoE架构。
姜大昕称,以上几点,无论是有哪一点有所不足,都会导致Scaling Law难以向上攀登。

但是!
就在前几天的全球开发者先锋大会开幕式上,阶跃星辰又给出了万亿参数MoE语言大模型Step-2的预览版——这也是国内初创公司,首次交出的万亿参数模型答卷。
姜大昕介绍,Step-2从去年12月启动训练,目前训练稳定,待完全训练完毕和打磨成熟。
“我坚信Scaling Law,(会)训练更大模型。”姜大昕谈到,团队追求的是多模理解和生成的统一,“Step系列大模型将为多模理解和生成的统一奠定坚实基础。”

基于实践经验,团队把攀登Scaling Law称为一个“铁人四项”般的超级工程。
哪四项?
算力、系统、数据、算法。
而阶跃星辰自然有自己熟稔的打怪套路。
算力方面,通过自建机房+租用算力,积极进行算力储备;
系统方面,团队核心成员实践过单集群万卡以上的系统建设与管理,训练千亿模型的MFU(有效算力输出)达 57%;
数据方面,数据团队核心骨干出身必应搜索引擎,曾支持全球100多种语言,为200多个国家和地区提供服务,对全球互联网高质量语料的分布有深入了解,并建立起强大的数据处理和知识图谱流水线;
算法方面,团队不仅能驾驭各种架构,比如万亿参数的MoE架构,而且对大模型的认知以及发展路线有深刻洞察。
不想只在时代的风中凌乱
面对铁人四项和多模态融合之路,阶跃星辰就这么默默进发了一年。
那么,是什么样的团队行进在这条Scaling Law之路上?
新火种得知的消息是,阶跃星辰现在已经有一支150多人的队伍。
领队者姜大昕,现任阶跃星辰CEO,同时也是团队算法负责人。
2005年,姜大昕获纽约布法罗州纽约州立大学计算机科学博士,在机器学习、数据挖掘、自然语言处理、生物信息等领域有丰富的经验和工程经验。
博士毕业后,他先后任南洋理工大学担任助理教授,MSRA(微软亚研院)研究员。
2011年开始,姜大昕转入微软亚洲互联网工程院(STCA)工作。
该中心主要负责微软全球产品的研发工作,包括必应搜索引擎、智能语音助手Cortana、Azure认知服务以及Microsoft 365的自然语言理解系统等。
去年3月,姜大昕正式升任为微软副总裁,同时兼任亚洲软件技术中心WebXT S+D(网络体验、搜索和分销)集团总经理。
——是的,你没听错,刚刚被升职,明明可以在微软干到退休,却跑出来创业了。
“在微软,只能基于OpenAI的模型做工作。”姜大昕回忆,即便是微软和OpenAI的关系,使用其模型也只能调用API,对黑盒里的秘密、模型算法的修复/迭代建议,完全插不上手。
琢磨再三,姜大昕决心不能再被动地风中凌乱。
于是,离开微软;于是,躬身入局。

有了创业想法的姜大昕,与现在阶跃星辰的数据负责人焦斌星“密谋”两个多小时,一拍即合。
焦斌星同样出身微软,是中科大和MSRA联合培养博士。
博士毕业后,焦斌星正式入职微软,是微软必应引擎核心搜索团队前负责人,日常工作主要是利用数据挖掘和NLP算法优化索引和搜索质量;也曾开发全球高质量站点的自动挖掘算法并用于索引和排序。
还在微软时,他二人就听说过外界盛传大模型时代的“数据荒”,即Scaling Law所需的数据不够用了。
当时,他们不以为然。有搜索引擎背景在,眼见互联网有上亿、上万亿的网页网站,怎么会不够用?
等到自己置身其中时,发现是真的不够用(笑死)。
好在现在既可以从多模态数据中挖掘更多数据,也可以像OpenAI训练Sora那样使用人造数据。

核心团队的另外一位成员,朱亦博,此前拥有多次单集群万卡以上的系统建设与管理实践经验。
他博士毕业于美国加州大学圣芭芭拉分校,曾任微软研究院研究员。
在这一波浪潮袭来之前,他的工作主要面向大规模系统以及超高速度性能网络。
2018年,他任职字节跳动,负责公司AI基础设施与基础AI框架,开始积累万卡集群的搭建经验;2022年底,他离开字节,跳槽至Google任高级主管,直接支持OpenAI最大劲敌、Claude的背后公司Anthropic。
可以说,阶跃星辰三位核心骨干的经历十分相似,就是第一阶段(博士期间)进行相关研究,第二阶段进入大厂在一线打拼,一直都在和AI的最新进展亲密贴贴。
当ChatGPT引领的大模型时代开始时,他们都意识到这是一个大变革,因此以最快速、最灵活、最全面的方式投身变革当中。
One More Thing
最最最后,阶跃星辰的个人效率助手跃问,刚刚上线了一个很赞的新功能。
叫一图读懂。
说大白话就是丢给它一个文档,就能一键生成解析重点的长图文
这是此前的ChatBot没上线过的功能,想要体验的朋友们,速去哟~
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章









