

 新火种
2024-02-21
新火种
2024-02-21 


三个Agent顶个GPT-4,基于开源小模型的那种|中大阿里联合出品
真·“三个臭皮匠,顶个诸葛亮”——
基于开源小模型的三个Agent协作,比肩GPT-4的工具调用效果!
话不多说,直接来看两个系统执行记录。
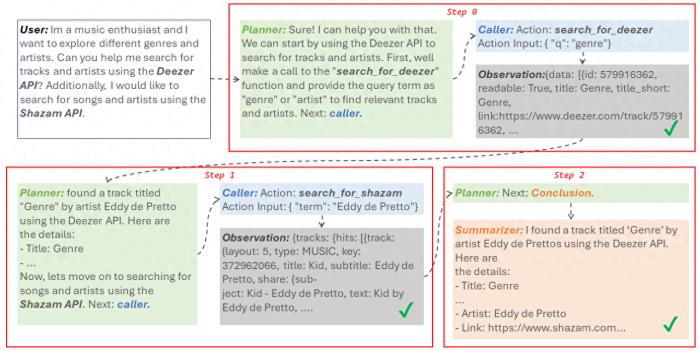
用户表示自己是一个音乐爱好者,想探索不同的音乐流派以及音乐家。他在指令中指定模型使用Deezer和Shazam的API来搜寻一些音乐曲目以及相应艺术家信息。
之后饰演三个不同的角色的Agent分工协作,在两步之内完成了任务。
更难一点的,不指定工具,让模型找一个最受欢迎的风景画教程视频以及上传该视频的频道详情。
在这种情况下,模型通常会遇到工具状态变化、出现工具被下架或工具所需参数定义变化的问题。
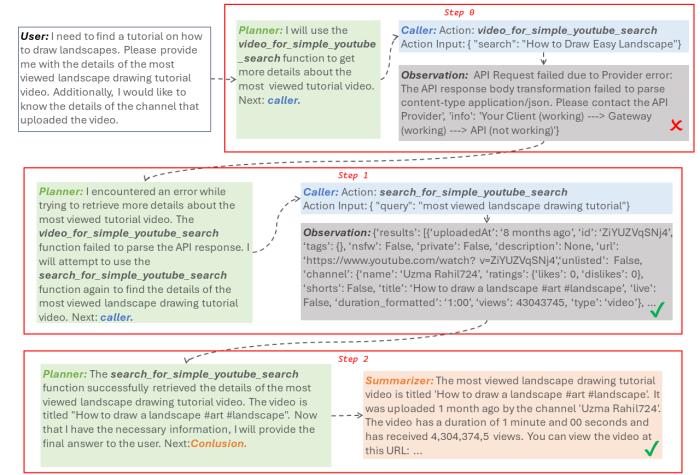
然而使用上述方法,模型在第0步试图使用video_for_simple_youtube_search来获取视频详细信息,但发现这个API已经被破坏,无法调用。
因此饰演planner角色的Agent转换思路,告诉饰演caller角色的Agent需要尝试另外一个API,并最终通过尝试新的API发现了详细信息,解决了用户的任务。
这就是中山大学、阿里通义实验室联合提出的一种基于开源小模型的多模型协作Agent框架——α-UMi。

α-UMi通过微调多个开源小模型,实现协同作战,在工具调用等数据集效果比肩GPT-4。
总的来说,相比于其他的基于闭源API框架,α-UMi的优势有以下几点:
基于α-UMi多模型协同框架,通过三个小模型:planner、caller和summarizer分别负责路径规划、工具调用和总结回复,对小模型进行工作负荷的卸载。相比单模型Agent支持更灵活的prompt设计。其在ToolBench,ToolAlpaca corpus等多个benchmark上超过单模型Agent框架,获得比肩GPT-4的性能。提出了一种“全局-局部”的多阶段微调范式(GLPFT),该范式成功在开源小模型上训练了多模型协作框架,实验结果表明这种两阶段范式为目前探索出的最佳训练多模型协作Agent范式,可以被广泛应用。多模型协作框架α-UMi长啥样?
目前,基于大模型调用API、function和代码解释器的工具学习Agent,例如OpenAI code interpretor、AutoGPT等项目,在工业界和学术界均引起了广泛关注。
在外部工具的加持下,大模型能够自主完成例如网页浏览、数据分析、地址导航等更复杂的任务,因此AI Agent也被誉为大模型落地的一个重要方向。
但上述一些主流项目主要基于闭源ChatGPT、GPT-4大模型,其本身在推理、步骤规划、调用请求生成和总结回复等能力上已经足够强。
相比之下开源小模型,由于模型容量和预训练能力获取的限制,单个模型无法在推理和规划、工具调用、回复生成等任务上同时获得比肩大模型等性能。
为了解决这一问题,本文研究人员提出了α-UMi。
α-UMi包含三个小模型planner、caller和summarizer。
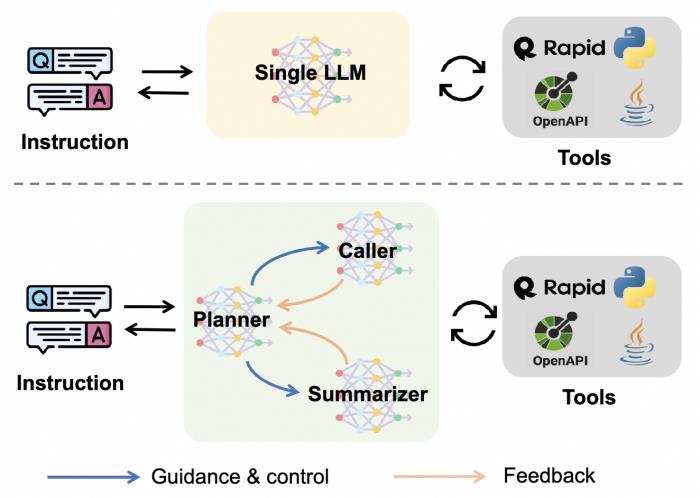
其中planner模型为系统的核心大脑,负责在某一Agent执行步骤内激活caller或summarizer,并给予对应的推理(rationale)指导;
而caller和summarizer则分别负责接收planner的指导完成该步后续工作,caller负责生成于工具交互的指令,summarizer负责总结最终的回复反馈给用户。
这三个模型都是基于开源小模型进行不同类型数据微调实现的。
此外,研究人员提出了全局-局部多阶段微调范式——GLPFT。
基于开源小模型,实现多模型协作框架并非一件简单的事,有两个作用截然相反的影响因素:
一是生成Rationale,Action和Final Answer三个任务在训练中可以相互促进的,同时也能增强模型对于Agent任务的全局理解。因此目前大部分工作均训练单个模型同时生成rationale, action和final answer。
二是模型容量,不同任务的数据配比等也限制了我们很难训练单个模型同时在三个任务上获得表现峰值。
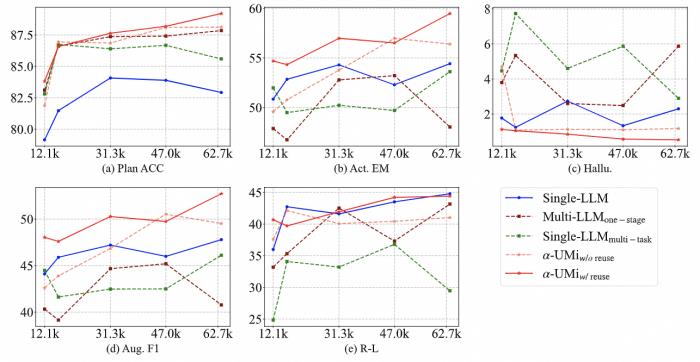
下图中,单模型Agent在各项指标上达到峰值所需的数据量是不同的,很难找到一个在所有指标上达到峰值的数据量和模型检查点。
而通过多模型协作,可以解决这个问题。
综合考虑上述两点,研究人员提出了一种“全局-局部”的多阶段训练方法,目标在于利用充分利用Rationale,Action和Final Answer在训练中相互促进的优势,获得一个较好的单模型初始化,再进行多模型微调,专攻子任务性能的提升。
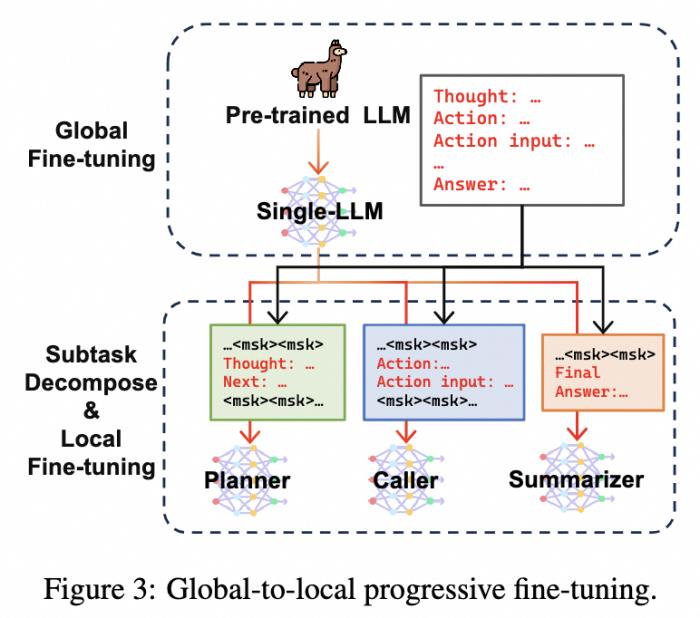
上图展示了这种多阶段微调的流程,在第一阶段中,使用预训练LLM在完成工具调用Agent任务上微调,获得一个单模型的Agent LLM初始化。
接着,在第二阶段中,研究人员对工具调用Agent任务的训练数据进行重构,分解成生成rationale,生成工具交互action和生成最终回复三个子任务,并将第一阶段训练好的Single-LLM Agent底座复制三份,分别在不同子任务上进一步微调。
性能比肩GPT-4
静态评估
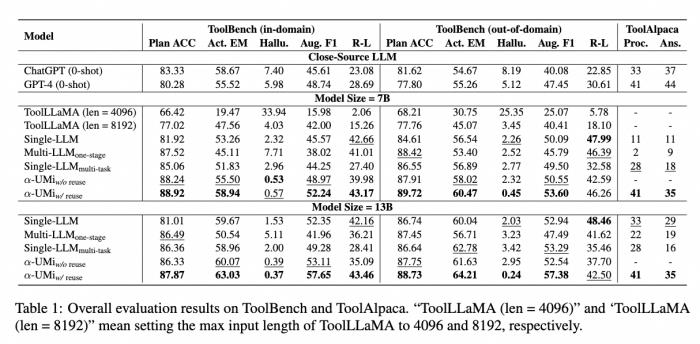
在静态评估中,本文将所有对比baseline的输出结果与标注输出进行对比,可以看到:
α-UMi系统表现显著超过了ChatGPT和工具调用开源模型ToolLLaMA,性能与GPT-4比肩。
值得一提的是,ToolLLaMA需要8192的输出长度以获得令人满意的结果,而α-UMi只需要4096的输入长度,得益于多模型框架带来的更灵活的prompt设计。
在多模型协作框架模型的微调方案对比上,直接微调三个模型、或单个模型多任务微调均无法使多模型协作框架发挥效果,只有使用多阶段微调GLPFT才能达到最佳性能,为后续多模型协同训练打开了思路。
真实API调用评估
作者也在ToolBench数据集上引入了一种真实API调用的评估方式,实验结果如下:
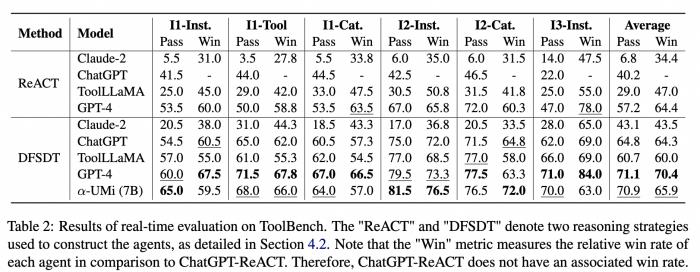
在真实API调用实验结果中,α-UMi 依然战胜了ChatGPT和ToolLLaMA,并在成功率上取得了与GPT-4比肩的结果。
模型开销
看到这可能有人问了,多模型协作会不会引入更多成本?作者也探究了多模型协作框架在训练、推理及储存阶段的开销对比:
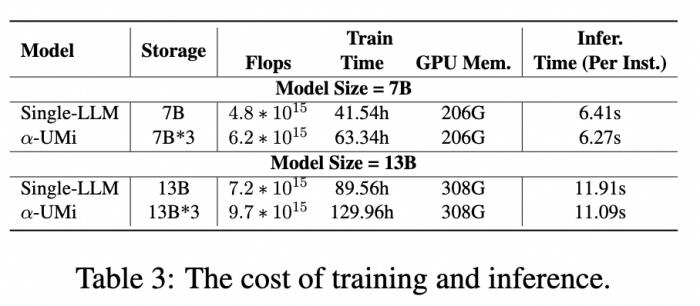
总体来说,多模型协作框架确实会在训练和模型参数储存上引入更高的开销,但其推理速度与单模型框架相当。
当然,考虑到多模型协作Agent框架使用7B底座的性能远超13B单模型Agent性能,总开销也更少。这意味着可以选择小模型为底座的多模型协作Agent框架来降低开销,并超过大模型的单模型Agent框架。
最后研究人员总结道,多智能体协作是未来智能体发展的趋势,而如何训练提升开源小模型的多智能体协作能力,是实际落地很关键的一环,本文为基于开源小模型的多智能体协作打开了新思路,并在多个工具调用benchmark上取得了超过单模型Agent baseline,比肩GPT-4的工具调用结果。
后续将会增强planner的泛化性,使其使用于更广泛的Agent任务场景,进行caller模型的本地私有化,使其专注于本地工具调用任务,以及云端大模型结合本地小模型的“大-小”模型协同框架。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










