

 新火种
2024-02-02
新火种
2024-02-02 


媲美GPT-4的开源模型泄露!Mistral老板刚刚证实:正式版本会更强
Mistral-Medium竟然意外泄露?此前仅能通过API获得,性能直逼GPT-4。
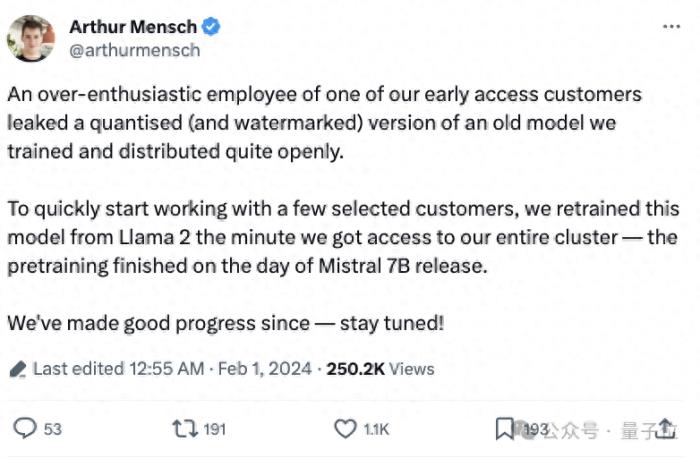
CEO最新发声:确有其事,系早期客户员工泄露。但仍表示敬请期待。
换句话说,这个版本尚且还是旧的,实际版本性能还会更好。

这两天,这个名叫“Miqu”的神秘模型在大模型社区里炸了锅,不少人还怀疑这是LIama的微调版本。
对此Mistral CEO也做出了解释, Mistral Medium是在Llama 2基础上重新训练的,因为需尽快向早期客户提供更接近GPT-4性能的API, 预训练在Mistral 7B发布当天完成。
如今真相大白,CEO还卖关子,不少网友在底下戳戳手期待。


Mistral-Medium意外泄露
我们还是重新来回顾一下整个事件。1月28日,一个名叫Miqu Dev的神秘用户在HuggingFace上发布一组文件“miqu-1-70b”。
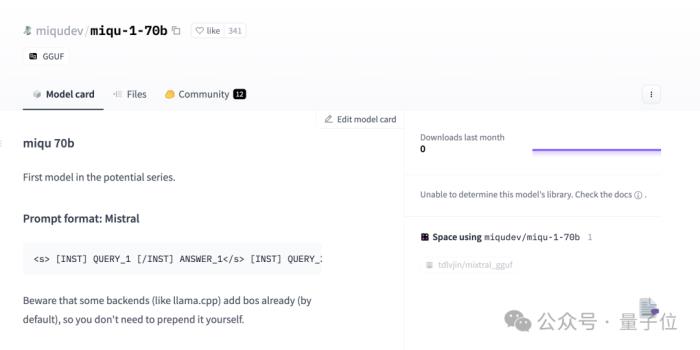
文件指出新LLM的“提示格式”以及用户交互方式同Mistral相同。
同一天,4chan上一个匿名用户发布了关于miqu-1-70b文件的链接。
于是乎一些网友注意到了这个神秘的模型,并且开始进行一些基准测试。
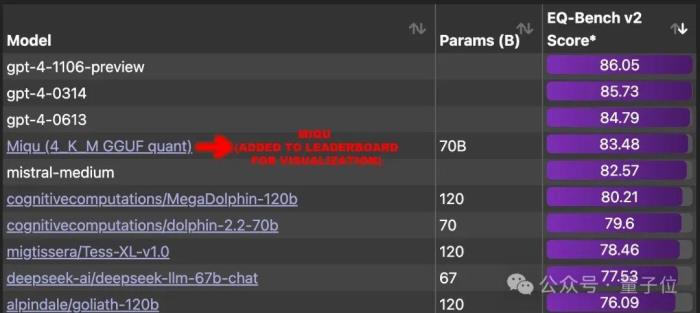
结果惊人发现,它在EQ-Bench 上获得83.5 分(本地评估),超过世界上除GPT-4之外的所有其他大模型。
一时间,网友们强烈呼吁将这个大模型添加到排行榜中,并且找出背后的真实模型。
大致怀疑方向主要有三个:
与Mistral-Medium是同一个模型。
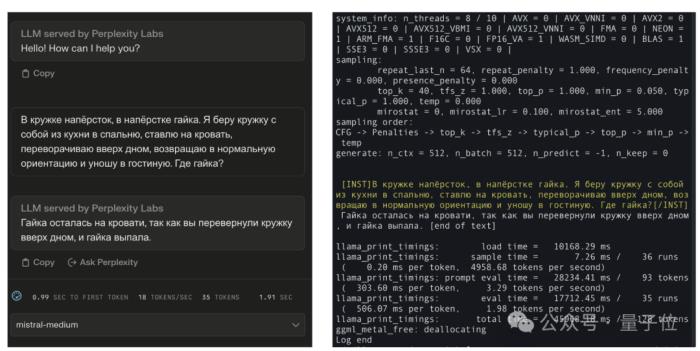
有网友晒出了对比效果:它知道标准答案还说得过去,但不可能连俄语措辞也跟Mistral-Medium完全相同吧。
Miqu应该是LIama 2的微调版本。
但另外的网友发现,它并不是MoE模型,并且同LIama 2架构相同、参数相同、层数相同,。
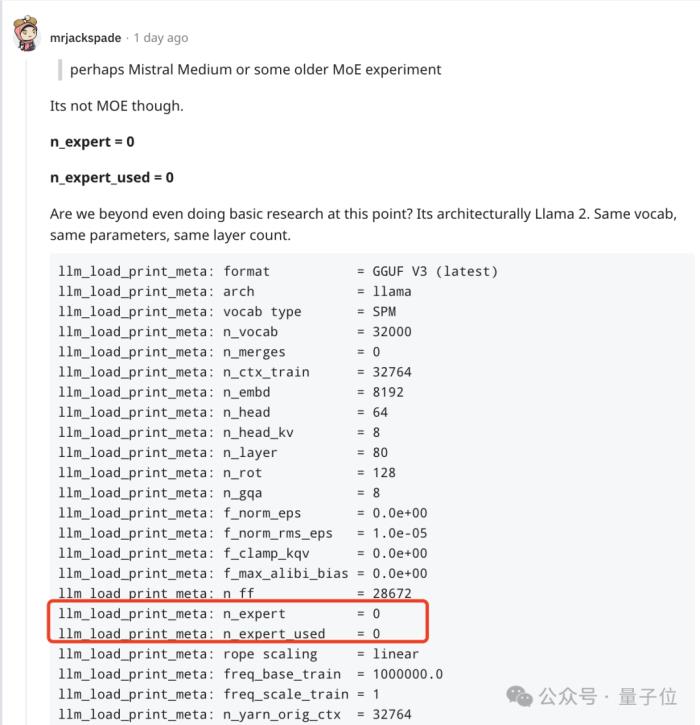
不过马上就受到其他网友的质疑,Mistral 7b也具有与 llama 7B 相同的参数和层数。
相反,这更像是Mistral早期非MoE版本模型。

不过讨论来讨论去,不可否认的是在不少人心中,这已经是最接近GPT-4的模型了。
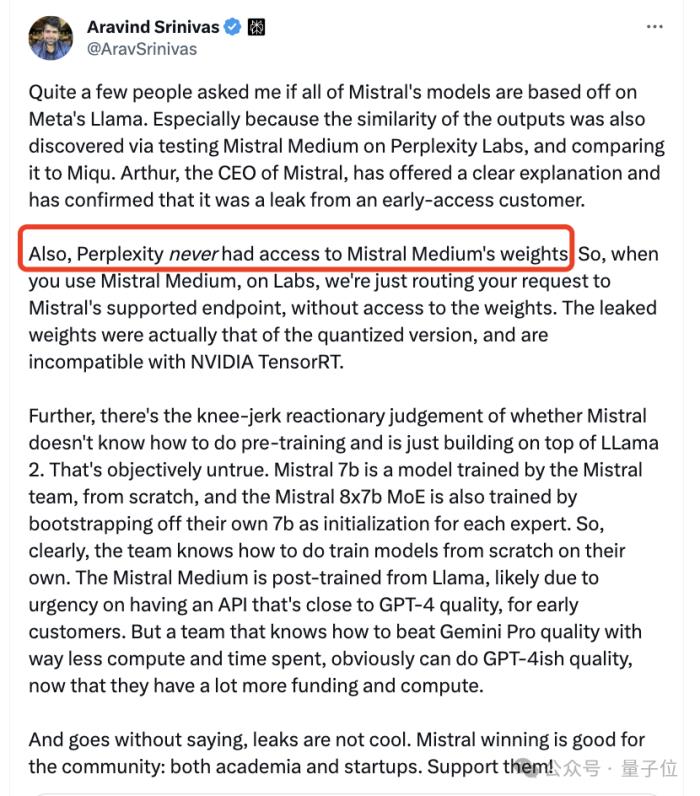
如今,Mistral 联合创始人兼首席执行官 Arthur Mensch承认泄露,是他们一位早期客户员工过于热情,泄露了他们训练并公开发布的一个旧模型量化版本。
至于Perplexity这边CEO也澄清说,他们从未获得过Mistral Medium的权重。
网友担心是否会撤下这个版本。

有趣的是,Mensch并没有要求删除HuggingFace上的帖子。
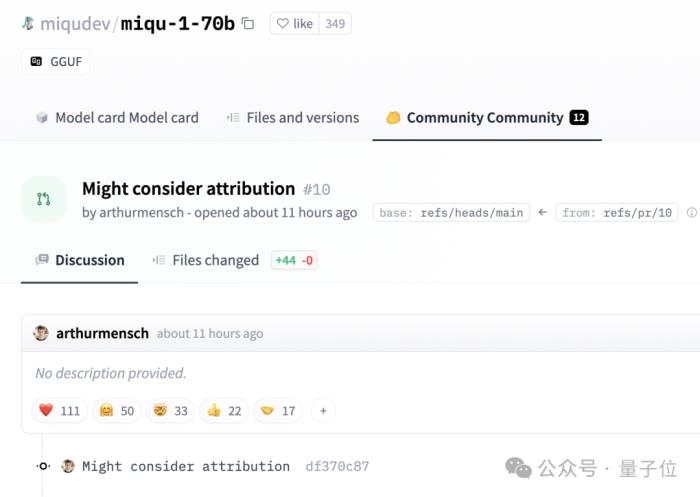
而是留下评论说:可能会考虑归属问题。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










