

 新火种
2024-01-05
新火种
2024-01-05 


深度网络数据编码新突破,上交大SPARK登上计算机体系结构顶会
随着深度神经网络(DNNs)模型在规模和复杂性上的迅速增长,传统的神经网络处理方法面临着严峻的挑战。现有的神经网络压缩技术在处理参数规模大、精度要求高的神经网络模型时效率低下,无法满足现有应用的需求。
数值量化是神经网络模型压缩的一种有效手段。在模型推理过程中,低位宽(比特)数据的存取和计算可以大幅度节省存储空间、访存带宽与计算负载,从而降低推理延迟和能耗。当前,大多数量化技术的位宽在 8bit。更为激进的量化算法,必须要修改硬件的操作粒度与数据流特征,才能在真实推理时获得接近理论的收益。比如混合精度量化,激活数据的量化等方案。一方面,这些方案会显式增加 book-keeping 存储开销和硬件逻辑,使得实际收益下降 [1,2,3]。另一方面,一些方案利用分布特征对量化范围和粒度做约束,来减小上述硬件开销 [4,5]。但其精度损失也受到不同模型和参数分布的影响,无法满足现有应用的需求。
为此,本文的研究者提出了 SPARK 技术,一种可扩展细粒度混合精度编码的软硬件协同设计。

其核心优势如下:
固有比特冗余:SPARK 不对模型进行压缩,而是剔除数据表示中固有的比特冗余,与现有的压缩方案正交,可以协同使用。
变长编码方案:SPARK 创新了变长数据表示格式,有效压缩模型大小,不需要增加额外的 book-keeping(如 index 等)代价(如硬件,访问与更新延迟)。该编码方案对模型参数与激活值同样适用。
硬件兼容性:SPARK 不需要修改硬件加速器微架构(如:脉动阵列),不会引入额外的设计复杂性,可行性较高。
平衡精度与效率:在大型模型中,SPARK 通过其高效的编码机制,不仅提升了处理速度,还精确地保持了模型的准确性。与其他同类型加速器相比平均获得了 4.65 倍的加速,降低了 74.7% 的能耗。
研究动机
本工作源于对模型参数与激活值分布的观察分析:由于权重和激活的分布成长尾型,量化后的数据仍会保持该分布,呈现高位稀疏的特性。具体的,按 INT8 精度量化后的模型参数中,80% 左右的数据都可以用 INT4 表示,只有一小部分较重要的值需要高位宽存储,如图 1 所示。
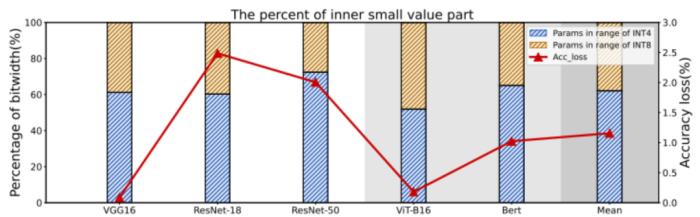
图 1 不同网络中 INT4 范围内数据和 INT8 范围内数据的比例
为了利用数据表示中固有的比特冗余,作者提出了 SPARK—— 一种可变长度的编码方案,通过引入一位指示符和新颖的编解码模式来支持混合精度。这种编码方案电路设计简单,而且维持存储对齐。
主要方法
在 SPARK 中,本工作只简单地用最高位作为指示符区分高 / 低精度数据,而不同于其他分离尾数域和指数域的复杂编码策略。同时,模型训练时就可以模拟该编码行为,而不用进行训练后微调来补偿由量化带来的精度损失。
编码方案及电路设计
该工作以 INT8 量化为例,每个数据为 8bit unsigned 整型。原始数据的编码表示为(b0,b1, b2, b3, b4,b5,b6,b7),具体的编码原则如图 2 所示。
1. 当原编码中只有b4- b7 这低 4 位包含非零有效位时,直接进行低精度无损编码,缩短为 4bit,其中最高位 C4 是指示符位,设为 0。
2. 当原编码中b0-b3 这高 4 位也包含非零有效位时,进行高精度编码。其中,最高位 c0 为指示符位,设为 1。之后,视 b0 异或 b3 的结果,决定是否进行有损近似编码或无损编码。
a) 当原数值范围在 [8, 127],即b3-b1 位包含非零有效位时,最高位的指示符位不作为数值位计算。当 b3 位为 1 时,在编码阶段将 b3 位设为 0 并将低 4 位 C4-C7 补偿为 1111。虽然,这一步是有损的,但由于补偿效应、损失精度较小。b) 当原数值范围在 [128, 255],即b7-b0位这 8 位都包含非零有效位时,最高位的指示符位作为数值位计算。当b3 位为 0 时,在编码阶段将 b3 位设为 1 并将低 4 位 C4-C7 补偿为 0000。当然,该工作也可以更激进地舍弃这些 fixed bit 进一步压缩存储容量与带宽,但需要在解码阶段把 fixed bit 填补后再将 8bit 数据送入计算单元。这会增加一些解码器的硬件开销。
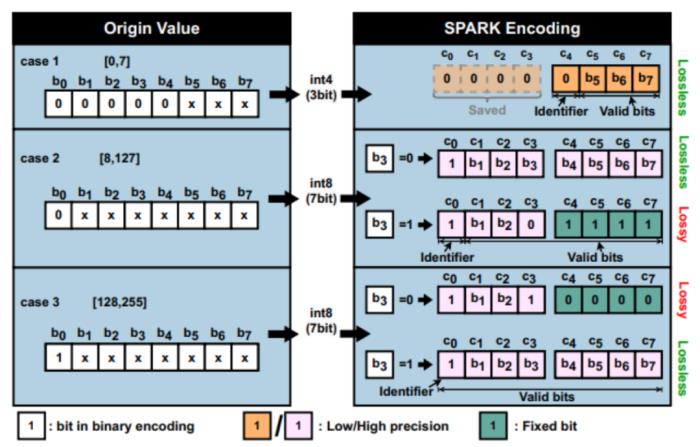
图 2 SPARK 编码对于不同范围的原数据的应用
硬件上实现该编码器只需要用到零检测器,多路选择器和异或门等熟知的硬件模块,具体电路设计如图 3 所示:输入 8bit 的原始数据,b0 ~ b4 先经过一个 5bit 的零检测器,判定该输入编码为高 / 低精度,如果编码为低精度则直接输出 b4,b5,b6,b7,若编码为高精度,则根据公式 1 和公式 2 分情况编码。
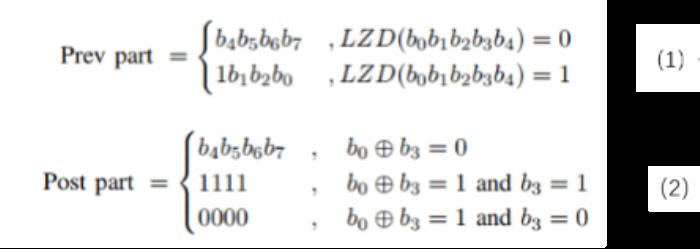
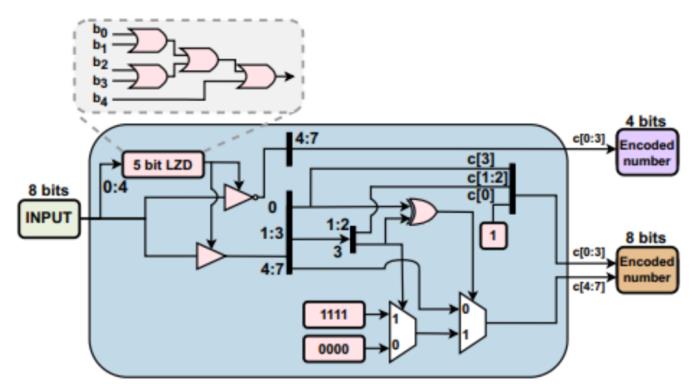
图 3 SPARK 方案的编码器电路设计
解码方案及电路设计
本工作设计了一个硬件友好的解码方案,下面将阐述如何将编码转换为十进制值。首先,本工作假定大端序存储(Big Endian),解码时输入位宽为 4bit,使能信号 1 位。
解码器电路需要的硬件模块为熟知的多路选择器,或门和非门。具体实现如图 4 所示,解码器每个周期读入 4bit 数据和使能信号。
当使能信号为 1,则指该输入是高精度值得后半部分编码;当使能信号为 0 时,若 c0 = 0,则判定输入是低精度值直接输出 c0c1c2c3 为解码值,若 c0 = 1 则根据 c3 判定将指示符位作为数值位计算。公式 3 阐述了具体的判定规则,图 4 是解码器的电路设计图。
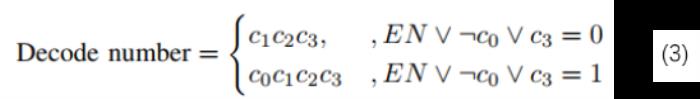
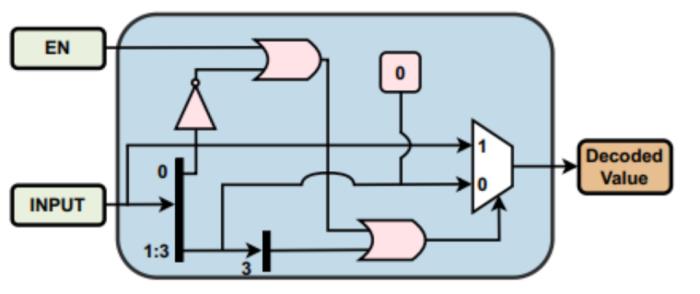
图 4 SPARK 方案的解码器设计
整体架构
SPARK 可以与常用的张量运算核心(脉动阵列,乘加树等)很好的兼容。如图 5 所示,解码器放置在 weight buffer 与 PE 之间,在参数灌入 PE 阵列之前解码;同样也放置在 Activation Buffer 与 PE 之间,在激活值灌入 PE 阵列之前解码。编码则分为两部分。对于参数的编码可以离线进行,在 DRAM 中直接存储已经编码压缩后的参数。在线硬件编码器则放置在 PE 计算完产生 Activation 之后。
若要进一步挖掘计算效率上的提升,则可以设计一个常见的混合位宽运算单元(SPARK PE Unit),支持两个 8bit 操作数的 MAC 操作,或者 2 对 4 个 4bit 操作数的 MAC 操作。
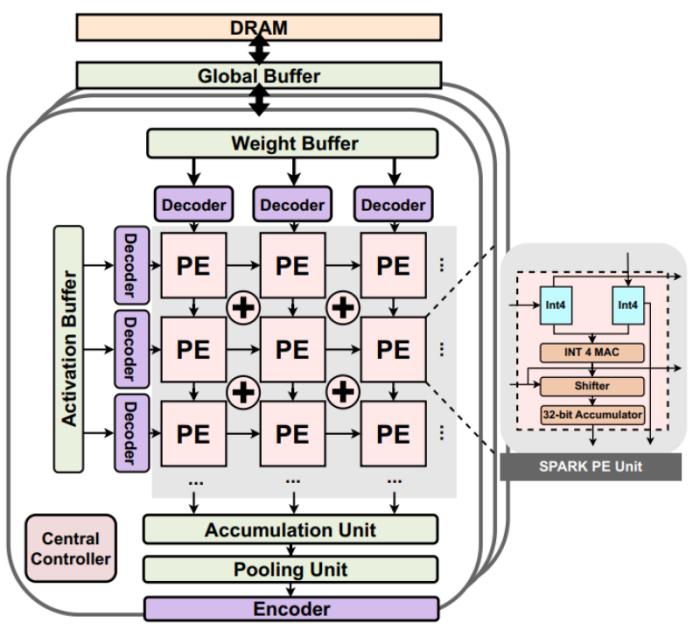
图 5 SPARK 整体架构图
实验结果
文章使用 CNN-based 和 attention-based 的模型簇进行实验,在 ImageNet 数据集上测试了 VGG-16,ResNet-18,ResNet-50 网络,在 GLUE 数据集上测试 BERT-based 模型,以及 ViT 模型。与 SPARK 进行对比的 baseline 架构有:Eyeriss [6], BitFusion [7], OLAccel [1], ANT [8], Olive [9]。
模型准确性评估
在 ImageNet 数据集上,和原始的 FP32 模型相比,SPARK 上的平均准确率损失大约为 0.1%,对于 attention-based 的模型,SPARK 获得了更好的准确性(+0.6%)。表 1 和表 2 展示了准确性评估的结果。
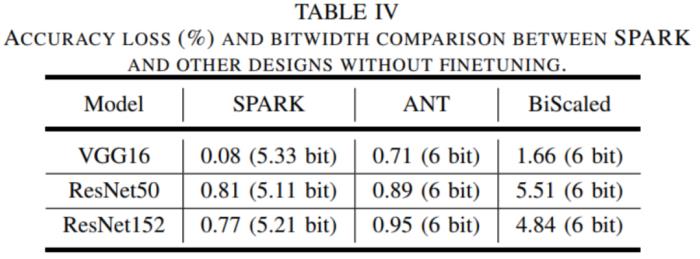
表 1 SPARK 和其他没有微调的架构在精度损失和平均存储位宽上的比较
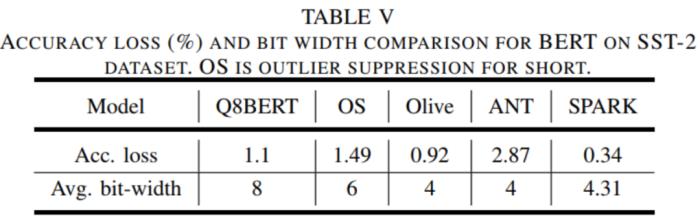
表 2 SPARK 和其他架构在 SST-2 数据集上测试 BERT 的精度损失和位宽比较
性能和能耗评估
执行效率上,图 5 展示了不同加速器在六个网络上的执行效率对比。和其他架构相比,SPARK 最多获得了 4.65 倍的加速,在 ResNet-50 网络上,SPARK 有 80.1% 的明显性能提升。
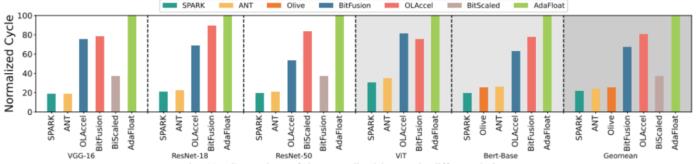
图 5 不同架构设计的延迟比较
能耗上,图 6 展示了不同架构的 DRAM,BUFFER,CORE 的能耗贡献在 5 个网络上的比较结果。对于 ResNet-50,SPARK 最多下降了 74.7%。
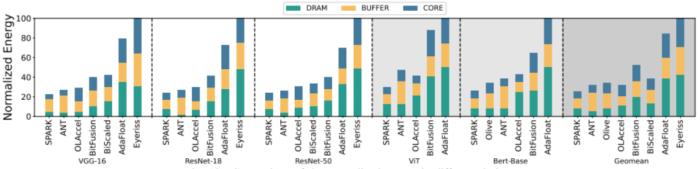
图 6 不同架构设计的能耗比较
结语
SPARK 利用数据表示中的比特冗余,结合高效的编解码方案,使得 AI 模型在保证精度需求的情况下,利用本就存在的比特稀疏,这对于计算、存储、传输都带来了巨大的开销节省。在处理越来越大的模型时,SPARK 展现出了其独特的优势。它不仅能够处理大规模数据,还能在精度极其敏感的场景下保持高效率。这一点对于现在 AI 应用尤为关键,如自动驾驶、医学诊断和语言处理等。
在未来,这套编码方法还可以进一步扩展到交换芯片,存储盘控芯片等关键位置,用于优化 AI 数据中心的通信瓶颈。
这一工作由上海交大先进计算机体系结构实验室蒋力教授课题组(IMPACT)完成,同时也获得了上海期智研究院的支持。第一作者是刘方鑫教授与博士生杨宁。
参考文献
[1] Park, Eunhyeok, Dongyoung Kim, and Sungjoo Yoo. "Energy-efficient neural network accelerator based on outlier-aware low-precision computation." 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2018.
[2] Zadeh, Ali Hadi, et al. "Gobo: Quantizing attention-based nlp models for low latency and energy efficient inference." 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2020.
[3] Guo, Cong, et al. "OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization." Proceedings of the 50th Annual International Symposium on Computer Architecture. 2023.
[4] Song, Zhuoran, et al. "Drq: dynamic region-based quantization for deep neural network acceleration." 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020.
[5] Jain, Shubham, et al. "BiScaled-DNN: Quantizing long-tailed datastructures with two scale factors for deep neural networks." Proceedings of the 56th Annual Design Automation Conference 2019.
[6] Y. -H. Chen, T. Krishna, J. S. Emer and V. Sze, "Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks," in IEEE Journal of Solid-State Circuits, vol. 52, no. 1, pp. 127-138, Jan. 2017.
[7] H. Sharma et al., "Bit Fusion: Bit-Level Dynamically Composable Architecture for Accelerating Deep Neural Network," 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 2018, pp. 764-775.
[8] C. Guo et al., "ANT: Exploiting Adaptive Numerical Data Type for Low-bit Deep Neural Network Quantization," 2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO), Chicago, IL, USA, 2022, pp. 1414-1433.
[9] Guo, Cong et al. “OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization,” In Proceedings of International Symposium on Computer Architecture (ISCA), 2023
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










