新火种
2023-12-26
新火种
2023-12-26 


深度学习应用:三步走,轻松掌握自然语言处理关键技巧
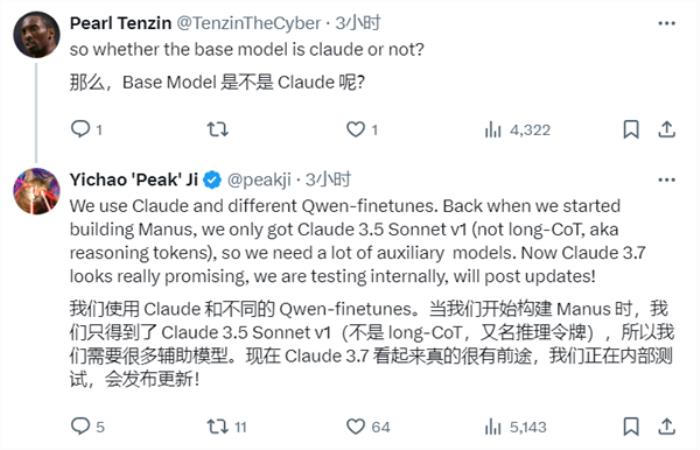
尊敬的同仁们,我是专注于深度学习应用和探究自然语言处理领域的专业人士,很荣幸能与你们分享我所获得的丰富知识。
一、数据预处理是关键
首先,为了做好自然语言处理项目,我们会先对原文本进行净化和标准化处理,删除多余干扰和特殊字符。然后,使用合适的示例来进行词义分割和标注设置,以便提取文本里的实体信息,为之后的模型训练提供高质量的素材。对于不同的任务和资源库,根据实际需求挑选适合的数据预处理方法绝对是关键步骤哦!
二、选择合适的模型架构
面对复杂的任务与数据规模,如何精准挑选深度学习模型如CNN、RNN乃至注意力机制等至关重要。举例来说,若需处理文本文档类任务,选用CNN当属适宜;对序列识别或机器翻译等问题,加入注意力机制的RNN则能发挥更好作用。此外,注意恰当地调整参数并进行超参数优化,也将有助于提升模型性能,不可忽视哦!
三、有效利用预训练模型
预训练模型(例如BERT和GPT)表现出色,具备卓越的语义理解力,能有效从大量文本资料中挖掘出重要语义特征。这些模型在实际语言处理过程中与传统深度学习技术相互配合,极大提升了分析准确性。经过适当调优并借助少量标记数据的训练之后,预训练模型通常能达到令人惊艳的效果。
四、合理选择损失函数和优化算法
在深度学习应用上,挑选出适当的损失函数及优化方法非常关键。常用的损失函数学包括交叉熵损失函数、 squared loss 函数以及 contrastive loss function等等;至于优化方法,建议选用random gradient descent、Adam以及Adagrad等。如果能够充分利用这些工具,必定有助于您有效地缩短训练时间,提升模型效果哦!
五、模型评估和调优
评估方法是筛选出优质成果的必要手段,我们需明确定义符合实际需求的评价准则,如精确度、准确性和F1比值等。另外,通过交叉验证和对比测试来进一步增强结果的可信度。如果发现模型存在问题,可以考虑改变网络结构、丰富训练资料或者改善算法使其更高效地运行。
六、持续学习和更新
在这个深度学习持续发展的领域,让我们始终保持对知识进步的热爱,紧跟最新的科研成果,快速地了解最尖端的技术。此外,定期反思自我,全面总结分析,深刻思虑专业的深层问题,才能维持我们职业上的高度,以及提高技术能力。
七、团队协作与沟通
在实践中的经验告诉我们,团队成员间深厚而通畅的交流与配合是成功关键。特别是在深奥复杂的自然语言处理领域,跨部门协同的时候,一个和谐友好且明了的环境、严密精准的沟通以及熟练的项目管理模式成为了不可或缺的因素。强有力的团队合作和快速传递准确信息,能让我们的工作水准更加卓越,并有效提升产品的价值。
在此,我荣幸地献上此篇关于以上思考的话痨,希望为广大自然语言处理领域的小伙伴提供些许灵感与引导。虽然深度学习已然展示了其巨大潜力,但我坚信将来定有更丰富的科研果实在前方等你采摘。让我们携手共进,砥砺前行,引领自然语言处理行业乘风破浪,向前进发!
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章