新火种
2023-12-21
新火种
2023-12-21 


计算机行业大模型专题报告:多模态引领新篇章
大模型概述:具备强大生成能力,训练趋于标准化
概述:通用大模型带来强大生成能力,追求高泛化能力
大模型可以高质量完成自然语言理解和生成任务。大模型主要指大语言模型(Large Language Model,LLM),是一种基于大量数据学习完成文本识别、总结、翻译、预测和 生成等人物的深度学习算法。当前大语言模型底层基于 Transformer 框架,利用大量文本 数据进行预训练,可以按用户需求高质量完成自然语言理解或生成任务,应用于机器翻译、 文本摘要、内容创作、逻辑推理等诸多场景。随着技术发展,大模型逐步超越大语言模型范畴,输入输出上逐渐涵盖音频、图像、视频等模态,形成具备多模态能力的大模型。
通用大模型以通用人工智能(AGI)为最终目标,追求模型效果的高泛化能力。过去 几年,大模型领域主要针对通用大模型投入研发,涌现出 GPT、Llama、PaLM 等代表模 型。通用大模型要求模型可以在不进行重新训练的情况下,在大多数场景下理解用户提出 的非结构化提示词,并基于需求理解实现稳定且正确的文本生成。通用大模型最终目标为 通用人工智能(AGI),亦称强 AI,及人工智能可以单独完成人类可以完成的所有任务,该 目标要求模型具有高场景泛化能力,对新样本具有完全适应能力。对泛化能力的追求在通 用大模型的训练数据和模型特点上得以体现。
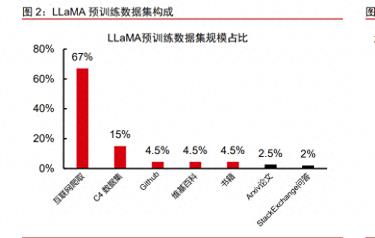
1)训练数据覆盖面扩大。过去几年,大模型预训练数据涵盖的行业快速增加,2019 年,谷歌基于互联网数据集 C4 推出 T5 模型;2023 年 Meta 发布开源通用大模型 LLaMA, 其预训练数据集以 C4 和其他互联网数据为基础,包含,维基百科、GitHub 代码、书籍、专 业论文等数据。预训练数据范围扩大有利于模型能力覆盖更多场景,提升模型通用能力。 2)训练数据分布上,通用语言文本占比较高,行业专业知识占比较低。通用大模型 预训练数据集以互联网数据、书籍等通用语言文本为基础,结合部分历史、地理等通识类 学科知识,行业专业知识占比较少,最大程度保证模型通用语言能力提升。以 LLaMA 的 预训练数据集为例,高专业度 ArXiv 论文数据占比 2.5%,Stack Exchange 专业行业问答 数据占比 2%,通用知识类文本占比超过 95%。 3)模型设计上,通用大模型参数和训练数据规模快速增长,模型以大体量承载大知 识量,让模型“学习”并“记忆”尽可能多的知识。根据 semianalysis 的数据,OpenAI 的 GPT-4 模型参数规模约为 1.8 万亿,为 GPT-3(1750 亿)的十倍以上;GPT-4 训练数 据规模约 20 万亿 Token,为 GPT-3(5000 亿 Token)的 40 倍,模型参数和预训练数据 规模保持高速增长,带来模型效果快速增强,根据 OpenAI 官方数据,GPT-4 较 GPT3.5 在回答真实性方面提升约 40%,并且生成不符合价值观答案的概率减少 82%。
通用大模型采用多数据集验证,取得优秀成绩。通用大模型通常以多领域、多层次的 数据集综合衡量模型效果,并不追求在单一数据集上的极致表现。根据 OpenAI 的 GPT-4 技术报告,模型评价利用学术测试集 MMLU、科学测试集 ARC、日常对话测试集 HellaSwag、 Python 测试集 HumanEval 等,以 7 大数据集全面覆盖多学科、多学段、多场景的生成能 力,力求全面综合评价模型整体表现。与之相对的是,小模型由于应用场景相对单一,模 型目标性更强,普遍采用单一测试集,例如 CV 领域知名的 ILSVRC 挑战赛便长期采用 ImageNet 数据集,其子集 ImageNet 1K(ILSVRC2012)长期被用于各论文的模型效果 评价。长期使用单一数据集带来时效性较差、评价指标相对单一的问题。
通用大模型以“预训练+微调”的模式加持应用场景。预训练阶段模型学习大量无标 注文本数据,使其模仿人类语言构成的训练数据集,进而具备各场景通用的生成能力;微 调阶段模型学习小规模行业专业知识,利用有标注的专业数据集针对模型输出层参数进行 调整,强化模型对特定领域的生成能力。“预训练+微调”的模式可以低成本提升模型在特 定行业领域的表现能力,成为长期伴随深度模型行业应用的通用模式。根据 AI 创业公司 Cohere 最新论文,在极限条件下只更新 0.32%的模型参数就可以实现模型微调,充分发 挥通用大模型的通用性,极大降低大模型行业应用成本。但由于微调改变的参数量小,只 能采用针对细分场景下特定功能进行针对性微调,导致单模型只能有效应对单一场景。
模型训练:流程逐步趋于标准化,数据需求持续提升
大模型训练可划分两大阶段,流程趋于标准化。大模型训练大致可分为通用能力培养 和行业能力提升两大阶段。其中通用能力培养主要包括无监督预训练、价值观对齐等核心 训练步骤,全面提升模型通用能力;行业能力培养主要包括有监督微调、行业预训练、偏 好对齐等训练流程,主要针对特定应用场景和行业需求进行模型优化。
1)训练数据:分词技术影响模型效果,训练数据规模应与模型参数规模相适应
数据以语义单元为单位输入模型,分词技术影响模型效果。语义单元(Token)是数 据输入大模型的最小单位,分词技术和向量化属模型核心技术。分词(Tokenization)是 自然语言处理领域的常用技术,指将完整的文本信息切分为语义单元(Token)并将其进 行数值化作为模型输入。当前以 Sub-word 为单位进行分词是最常用的方式,而具体的分 词方式例如 BPE、WordPiece、UniLM 等技术,以及语义信息的向量化技术均会对模型输 入产生直接影响。当前语义单元是计量大模型训练数据量的单位,对于训练数据集规模的 描述在 2020 年左右经历了从储存空间(GB、TB)到 Token 数量的转变。
训练数据规模应与模型参数规模相适应,大量模型数据规模不足的问题。2022 年 9 月,DeepMind 提出 Chinchilla Scaling Laws,提出了最优的模型规模-数据规模匹配方案, 其研究认为单个参数需要 20 个左右的 Token 进行训练,并且模型规模越大,单个参数所 需的数据Token越多。在Chinchilla law之前,行业遵循OpenAI提出的Kaplan Scaling law, 及单个参数需要 1.7 个 Token 投入训练。以 GPT-3 为代表,2022 年之前的大模型主要依 据 Kaplan law 确定训练数据的规模,存在模型参数量大但训练数据不充分的问题。根据 semianalysis 的数据,OpenAI 的 GPT-4 模型参数规模约为 1.8 万亿,训练数据规模约 20 万亿 Token,较 GPT-3 更趋近 Chinchilla 定律但数据规模仍有不足。
2)模型设计:参数量、规模持续增长带来模型效果提升
AI 大模型参数量快速增长,规模快速扩大表现出涌现能力。2018 年发布的 GPT-1 和 BERT 模型参数量大约为 1 亿,2020 年发布的 GPT-3 模型参数规模为 1750 亿,2023 年 推出的 GPT-4 和 Gemini 模型规模已经达到万亿水平,大模型参数规模持续高速增长。涌 现指大模型规模达到一定程度时在特定任务上的表现显著提升。涌现能力并非人为设计和 构建的,是大模型作为端到端模型可解释度较低的情况下,对于大模型具有一定思维能力 的概括性描述。
3)模型预训练:自监督预训练成为行业标配
预训练强调训练模型的通用能力,自监督预训练(self-supervised pre-training)推 动模型发展。通过预训练得到通用大模型(GPT-4、PaLM 2)。预训练及在应用场景未知 的情况下,让模型自主学习通用表征以尽可能满足更多场景的应用需求。大语言模型数据 规模极大,数据标注成本极高,自监督预训练模式无需数据标注,有力支持大模型训练数据规模的快速增长。
4)模型价值观对齐:价值观注入保证模型输出符合道德人伦
模型价值观对齐主要目标是确保模型输出结果符合社会道德和法律约束。模型对齐是 近年来研究者开始
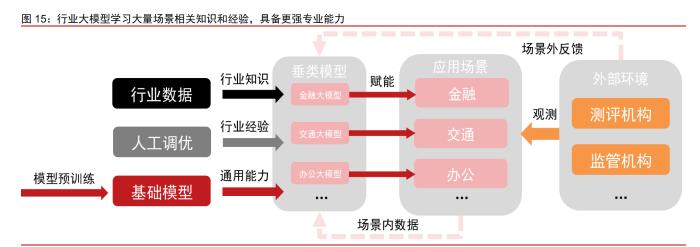
5)大模型行业化:基于通用大模型形成垂类模型主要有三种方式。三种方式可以在 单一模型上同时使用以最大程度提升模型效果。 1)行业数据预训练:利用大量无标注行业数据对模型整体进行预训练。行业知识大 量注入模型使得经过行业预训练的模型获得单行业能力提升,可有效降低模型在特定行业 内的幻觉问题,同时最大程度保留模型的通用能力,维持模型的基本泛化性能,因此备受青睐。但该方法数据需求大,同时消耗较多算力资源,适合在特定有大量数据积累的行业 使用。 2)模型对齐:利用 RLHF 机制人工介入对模型进行微调。模型较微调而言更加温和, 可以在提升模型特定行业表现的同时,维持模型通用能力,但同样无法杜绝模型出现幻觉 问题。同时模型对其安全性较强,人工介入保证模型输出符合法律、道德等约束,同时保 证模型各领域的能力平衡,但需要大量人工成本和较长训练时间,往往作为模型训练的最 后步骤。 3)模型有监督微调:利用少量有标注的行业数据对模型靠近输出侧的部分参数进行 微调。微调可以利用少量参数显著提升模型在特定行业上的表现,同时算力成本只相当于 通用大模型预训练的 1%左右,但该方法会牺牲模型通用能力,严重加剧模型在其他领域 的幻觉问题。
海外厂商:OpenAI 领先通用大模型,Google 和 Anthropic 形成第二梯队
1)OpenAI:通用大模型的领跑者
坚持长期投入,引领本轮大模型技术发展。OpenAI 公司成立于 2016 年,早期专注于 自然语言处理赛道开发可商用的 AI 聊天机器人,如今公司核心宗旨为实现安全的通用人工 智能(AGI),致力于提供通用能力更强的大模型。GPT(Generative Pre-trained Transformer)最早可以追溯到 2018 年 OpenAI 发布 GPT-1,此后随着模型迭代,GPT 模型能力不断提升。最新的 GPT-4 与 GPT-3 的模型规模相当(1750 亿),但通过更多的 数据和计算资源投入实现进一步发展。GPT-4 支持多模态,可以理解复杂概念,并在语言 以外的数学、医学、法律的多学科上表现出与人类相近的能力。
GPT-4 Turbo 以更低价格提供更强能力,多模态接口全面开放。较原版 GPT-4,GPT-4 Turbo 本次主要获得五大更新:1)上下文能力增强,模型上下文窗口从 32K 提升到 128K, 相当于单次可输入超过 300 页的英文文本;2)模型知识更新,外界知识从 2021 年 9 月 更新到 2023 年 4 月;3)调用优化,推出 JSON 模式优化 API 多任务调用效率,模型格 式化输出能力提升;4)单价降低,输入定价 0.01 美元/Token,较原版便宜 3 倍,输出定 价 0.03 美元/Token,较原版便宜 2 倍;5)速度提升,Token 输出限制速率提升一倍,用 户可自主申请提速。同时,OpenAI 在 GPT-4 Turbo 上开放图像输入,定价视图片尺寸而 定,1080x1080 图像输入定价 0.00765 美元。图像模型 DALL·E 3 和文转声模型 TTS 通过单独 API 开放给用户。在模型能力提升、多模态能力加持、服务价格降低等多重因素 共同作用下,GPT-4 流量或将迎来全新增长。
2)Google:技术积累深厚,逐步实现追赶
Google 在自然语言处理领域有深厚技术积累。2017 年谷歌公司发表论文 Attention is All You Need(Ashish Vaswani, Noam Shazeer, Niki Parmar 等),开启 Transformer 框架 下的大模型时代。公司在三条技术路线均有布局,有大量自研模型发布。2017-2021 年, 由于自身核心搜索引擎业务影响,谷歌大力投入自然语言理解而非生成能力研发,因此 Google 在 BERT 路线和 T5 路线上投入大量研究力量,导致公司在 GPT 路线上落后于 OpenAI。2022 年,谷歌先后推出 1370 亿参数的 LaMDA 和 5400 亿参数的 PaLM 模型, 但模型效果并未超越 1750 亿参数的 GPT-3。2023 年 5 月,公司推出对标 GPT-4 的 PaLM 2 模型,成为当前可以与 OpenAI 正面竞争的主要公司。
谷歌官方发布公司迄今为止规模最大、能力最强的 Gemini 大模型。12 月 6 日,谷歌 发布 Gemini 模型,按不同模型规模包括 Gemini Ultra、 Gemini Pro、Gemini Nano 三个 版本。根据官方测试数据,模型文本能力出众,在特定测试方法下,性能最优的 Ultra 模 型在 MMLU 测试集上以 90.0%的高分,成为历史上第一个超越人类专家的模型。Gemini 采用“原生多模态”架构,具备强大多模态能力和图文结合的逻辑推理能力,在数学、物 理等学科问题上表现优秀,可以基于视觉和文本提出具有一定创新性的观点。针对 Gemini 定制版,谷歌推出 AlphaCode 2,性能超过 85%的人类程序员。同时谷歌同步发布 TPU v5e, 较 TPU v4 性价比提升 2.3 倍,采用全新计算芯片的 Gemini 模型,较前代 PaLM 模型运 行速度更快、更便宜。
3)Anthropic:核心团队来自 OpenAI,注重模型安全
注重模型安全问题,公司快速发展。创始人 Anthropic 是由 OpenAI 前研发副总裁 Dario Amodei 带领其团队成员于 2021 年成立的公司,对高级人工智能安全问题的保持高度
积极探索新技术应用。在 Claude 模型训练中,Anthropic 提出 CAI 机制及模型排序代 替人工排序的 RLHF 以提升训练效率,同时推测其通过为底层 Transformer 增加 Memory 模块使模型记忆力为 ChatGPT 的三倍。公司未来计划构建名为“Claude-Next”的前沿模 型,比目前最强大的 AI(GPT-4)还要强大 10 倍,需要在未来 18 个月内投入 10 亿美元。
4)Meta:开源模型领导者,积极探索多元技术
目前采取低成本开源策略,与闭源大模型形成差异化竞争。2023 年 7 月 19 日,Meta 正式发布可商用开源大语言模型 Llama 2,成为开源模型标杆。根据 Llama 2 技术报告 (Hugo Touvron, Louis Martin, Kevin Stone 等),和初代 Llama 相比,Llama 2 最大模型 参数规模从 650 亿提升到 700 亿,训练数据提升 40%达到 2 万亿,模型效果明显优于其 他开源模型,是目前能力较强的开源大语言模型,但由于模型规模较小等原因,和 GPT-4 等闭源模型相比仍有差距。低成本的大模型能力是 Llama 2 打造自身生态的最大优势,主 要反映在:1)Llama 作为开源模型支持免费商用,极大降低企业模型调用成本。2)模型 参数量较小,最小具有 70 亿参数版本,形成垂域过程中需要的行业数据量较小,适合数 据量小、数据质量欠佳的行业应用,数据成本更为可控。
探索多元大模型技术发展路线。Meta 首席科学家、图灵奖得主 Yann LeCun 作为人工智能行业权威专家,并不满足于 GPT 路线下的大模型架构,并基于类人人工智能模型 提出了“世界模型”框架。目前部分模组得以发布(I-JEPA),但相关框架在现行技术水 平下仍然缺乏足够可行性。
大模型技术:形成三大技术路线,GPT 路线得到认可
底层技术:自注意力机制为 Transformer 带来优秀性能
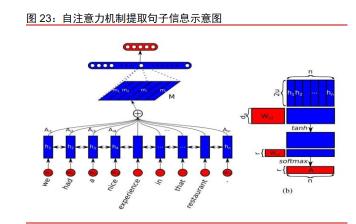
Transformer 的出现从根本上颠覆了 NLP 领域生态,成为大语言模型发展的基石。 2017 年,谷歌提出 Transformer 框架,底层为自注意力机制(Self-attention)。引入自注 意力机制的 Transformer 彻底解决了远距离信息丢失和并行计算问题,当前 Transformer 架构已经成为自然语言处理(NLP)领域的统一研究范式: 1)模型训练中一次性输入全部序列统一求解,远距离信息被包含在同一次模型运算 当中,解决了远距离信息丢失问题; 2)Transformer 不具备时序特征,训练运算没有关联性,可以有效支持并行计算。高 并行效率赋予了模型更强的拓展性,为参数规模快速提升提供了条件。
模型技术:基于 Transformer 形成三大主流技术路线,GPT 路线脱颖而出
以 Transformer 为基础,业界形成三大主流技术路线:编码器路线、解码器-编码器 路线、解码器路线。 1)编码器路线(Encoder-Only)只利用 Transformer 的解码器,侧重理解任务。BERT 模型采用双向自编码算法,模型 Mask 设计使运算输入包括目标词的前文和后文内容。因 为利用了前后文推测目标词,模型预测稳定、表现良好,同等参数规模下,BERT 类模型 效果往往优于其他路线。 2)编码器-解码器路线(Encoder-Decoder)同时利用编码器和解码器,侧重转换任 务。该路线在 BERT 模型基础上增加了一组与编码器大小相似的解码器。其编码器部分采 用与 BERT 相同的双向自编码策略加强理解,而在解码器部分采用了 GPT 的自回归策略 方便生成。模型初步具备统一的多任务能力,以单一模型完成大部分自然语言处理任务, 编码器-解码器形成的理解+生成结构使得模型擅长翻译等转换类任务。 3)解码器路线(Decoder-Only)只利用编码器部分,侧重生成任务。该路线只采用 解码器部分,利用大参数规模和大规模预训练强化模型的通用能力。优秀的生成能力带来 的应用前景,该路线已经获得了行业的广泛认可。
编码器路线:BERT 初步展现大模型能力
2018 年,Google 发布基于 Transformer 的 BERT 模型,拥有 3.4 亿参数,采用双向 预训练+Fine Tuning(微调) 的训练模式。模型一经推出便在 11 个 NLP 任务上超越当时 最高水平,在部分场景上表现追平人类。BERT 的出现让人们看到了 Transformer 框架的 价值和自然语言理解的无限可能,互联网厂商相继建设人工智能研究部门,大模型发展进 入快车道。 BERT 路线(编码器路线)只使用 Transformer 中的编码器部分,采用双向自编码算 法,及模型 Mask 设计使运算输入包括目标词的前文和后文内容。该设计的不足是模型计 算需要后文内容,因此无法进行生成式任务,只适用于自然语言理解(NLU)任务。但优 势是因为利用了前后文推测目标词,模型预测稳定且效率较高,小参数规模下 BERT 类模 型效果往往优于其他路线。
编码器-解码器路线:T5 模型探索多任务能力
2019 年,T5 模型发布并提出一个统一框架,将所有 NLP 任务均转化为 Text2text 的 文本任务,及利用文本生成文本的任务。基于统一的任务框架,所有任务均可以使用相同 的训练目标函数和推理解码过程,模型初步具备了统一的多任务能力,探索了大模型的通 用能力。 模型在聚焦自然语言理解(NLU)任务的同时,具备一定自然语言生成(NLG)能力。 T5 路线模型是在 BERT 模型基础上增加了一组与编码器大小相似的解码器,使得模型在 利用编码器理解输入的基础上具备一定利用解码器输出的能力。其编码器部分采用与 BERT 相同的双向自编码策略加强理解,而在解码器部分采用了 GPT 的自回归策略方便生 成。模型在翻译等任务重表现良好,但生成能力不足。
解码器路线:生成能力优势明显,已经成为行业共识
以 GPT 为代表的解码器路线早期专注自然语言生成(NLG)领域。2018 年,OpenAI 推出了 GPT 模型,舍弃了 Transformer 中的编码器,只利用解码器部分强化生成能力。初代 GPT 模型依然采用了类 BERT 的多任务微调模式,有多个模型适配不同任务需求。2019 年,GPT-2 的发布奠定了解码器路线无监督预训练和通用模型的基调,解决了零次学习 (zero-shot)的问题,使得单一模型可以适用所有任务。GPT-2 和 T5 相比,在不损失模 型生成能力的前提下,去除解码器极大降低了模型规模和训练难度。2020 年,GPT-3 发 布并展现的强大生成能力,成果得到业界广泛认可,各大公司开始跟进解码器路线模型研 发,2021 年 Deepmind 推出 Gopher,2022 年 Google 推出 LaMDA。
GPT(解码器)路线采用单向信息传递和自回归特征。模型训练阶段,GPT 路线模型 利用解码器的 Mask 结构屏蔽目标词后方的内容,保证信息的单向传递,只学习利用目标 词左侧(前侧)内容进行目标词预测;推理阶段,模型从左到右进行单向生成,同样保持 单向信息传递。与之对应的是,解码器(BERT)路线采用双向信息传递,训练和推理中 模型可以利用全部文本信息;解码器-编码器(T5)路线采用部分单向信息传递,编码器 中的输出序列及解码器中前面的文本会参与后方目标的注意力计算。
GPT 路线模型擅长生成,强大能力在考试和测评中得到体现。单向生成符合人类正常 思维逻辑,人类正常表达方式及为根据前文思考后文,从前到后顺序思考。与 BERT 根据前后文“填空”的方式相比,自回归模型更像“写作”,生成模式完全符合上述人类思考 逻辑。该逻辑全面融入训练和推理流程,因此模型输出文本质量高,语言流畅。2023 年 3 月,OpenAI 最新模型 GPT-4 模拟考试中表现优异,在环境科学、历史、生物等学科考试 中已经可以取得前 10%分位的成绩,在其他大量学科上达到前 20%分位。GPT 路线代表 模型 GPT-4、Claude、PaLM、Llama 等更是长期位于模型能力榜单前列,展现强大理解 和生成能力。
未来展望:当前大模型与 AGI 仍有差距,多模态成为重要途径
通用人工智能(AGI)具备人类级别智能。作为强人工智能的典型代表,未来通用人 工智能(AGI)系统将具备达到或超过人类的智能,具有高度自主性,可以独立完成大量 工作,因此可以规模化实现人力替代,进而推动社会生产力全面提升。当前主流公司对于 通用人工智能的探索持续从未止步,OpenAI 将构建安全、符合共同利益的 AGI 系统作为 企业核心使命;谷歌 DeepMind 研究团队发布 AGI 的 5 级分级定义,并认为当前主流大模 型只达到 1 级水平。
当前主流大语言模型和 AGI 之间仍有较大差距。GPT 路线构建的大语言模型已展现 出强大的自然语言理解和生成能力,但参考 Deepmind、OpenAI、Meta 等公司对于 AGI 能力的定义,我们认为当前大语言模型在各维度上距离 AGI 仍有较大差距,主要体现在性 能和通用性、认知能力、工具使用能力、创作能力等方面。
多模态能力提升模型各维度能力,推动大模型走向 AGI。当前大模型主要指大语言模 型(LLM),输入输出均已文本形式进行,而多模态大模型(MLLM)则可以输入或输出文 本及其他模态,包括图像、视频、音频、数据库等。多模态能力全面提升模型各维度能力, 成大语言模型走向 AGI 的重要途径。
1)性能和通用性:多模态能力突破文本对模型训练的限制,保障模型效果快速提升。 大模型多模态能力可以打破训练上对文本信息的完全依赖,通过图片以更加直观的方式学 习更多知识,提升模型训练效果。根据论文信息(Huang, Z., Bianchi, F., Yuksekgonul, M. et al. A visual–language foundation model for pathology image analysis using medical Twitter. Nat Med 29, 2307–2316 (2023).),斯坦福大学团队融合多模态病理图片、专业知 识、社交网络等数据,构建了 OpenPath 数据库并训练 PLIP 模型。新模型在诊断效率提 升和医学教育等领域具有潜在应用空间,展现了多模态数据对于模型训练的重要价值。此 外,大模型学习文本以外的知识对于打破文本规模对模型规模限制具有重要意义,根据未 尽研究数据,当前高质量语言数据总存量约 9 万亿个单词,年化增长率为 4%-5%,明显 慢于模型规模增长速度,最早 2026 年就会出现因文本量不足导致的模型规模扩增放缓, 突破文本规模对模型规模的限制对于大模型未来的持续增长具有重要意义。
2)认知能力:多模态协同实现精准认知,推理能力显著提升。大模型直接扩展多模 态认知渠道,实现从文本单维度认知到多维度混合认知的转变,可以利用多信息理解用户 需求。根据麦拉宾法则,面对面沟通时的信息表达中视觉信息占比达到 55%,其次是语音 语调的 38%;而根据中科院数据显示,对于一个正常人,视觉信息占全部感觉信息的 70% 以上。只利用文本的大语言模型存在信息利用效率过低的问题,拥有听觉和视觉的大模型 可以捕捉更多外界信息,实现对环境和用户需求的精准认知,可以实现基于外部环境、用 户情绪、问题语境等要素的实时输出优化。同时,利用大模型多模态能力的融合复杂信息, 可以形成更加有效推理和相对复杂的思维链,如利用图片里的物体位置、状态、关系等信 息,结合用户文本输入实现综合判断,进行准确的推理和分析。
3)工具使用:多模态能力支持更多工具调用,同时提升能力和效果。当前大模型输 出仍存在常识性错误,反映对以搜索工具为代表的外部工具使用能力不足。结合多模态能 力的大模型可以使用更多工具提升模型效果,如利用代码解释器(Code Interpreter)实现 网页上的数据分析,通过类似 CLIP 的图文模型进行跨模态搜索。更强的工具使用能力有 利于大模型接入外部模块化工具,提升模型输出效率;另一方面,随着工具集扩展,模型工具学习方案不断丰富,模型输出准确性和时效性有望进一步提升。
4)创作能力:多模态输入提升模型“创作”空间,艺术创作能力得到行业权威认可。 在以图灵测试为代表的现行 AI 标准下,类人的行为和更高的回答正确率即为智能,因此大 模型训练以正确模仿人类为主要目标,更倾向于输出“学习过的”答案。GPT-4 模型发布 之初就强调模型拥有写小说的能力,但高质量生成需要人工限定主题、框架、背景、思想 等各要素,并且尚未出现获得广泛认可的作品,大语言模型的创作能力相对有限。多模态 的引入和融合,让模型的模仿维度更加多元和随机,实现类似联想的创作能力。2021 年, OpenAI 发布 DaLL·E 模型,模型生成的牛油果椅子图片,因多元的设计风格、优秀的元 素融合获得广泛
多模态:视觉能力为核心,能力升级带动应用落地
概述:语音和视觉能力先行,模型效果全面提升
语音和视觉能力先行,视觉能力为核心。当前模态主要包括图像、视频、音频、代码、 标准数据库等,多模态大模型进展主要围绕语音和视觉任务,其中语音任务和文本任务本 质上相通,有成熟开源技术方案,门槛相对较低;而视觉任务主要涵盖视觉理解和视觉生 成,由于信息复杂度高、利用难度较大,并且对模型感知能力和应用开发潜力提升具有重 要价值,成为当前多模态大模型发展的核心方向。
OpenAI 和谷歌引领基于大语言模型的多模态能力探索
OpenAI 引领行业发展,ChatGPT-4V 展现强大能力。根据官方技术文档,OpenAI 于 2022 年完成 GPT-4V 版本(视频版本)的模型训练;2023 年 3 月,GPT-4 模型发布会 上展示了模型的图像输入处理能力,并与移动应用 Be My Eyes 合作落地图像处理能力, 但始终未在官方 ChatGPT 产品中开放语音输入以外的多模态能力。2023 年 9 月 25 日, OpenAI 正式发布 ChatGPT-4V(ision)版本,ChatGPT 新增图片输入和语音输出能力, 多模态能力正式融入 ChatGPT。本次更新显示 GPT-4 多模态能力已经成熟,新能力有望 加速落地。逐步拥有“视觉”和“听觉”的大模型有潜力在更多场景下获得应用,未来随 着软硬件革新,大模型有望支持“触觉”、“嗅觉”等全新模态,应用场景将实现加速扩展。
谷歌发布原生多模态大模型 Gemini,实现对 GPT-4V 的技术追赶。Gemini 采用“原 生多模态”架构,文本和视觉等输入在统一模型架构下参与预训练,各模态之间的结合更 加流畅。推理能力方面,模型在数学、物理等学科问题上表现优秀,可以对解题过程的进 行步骤拆分,并可以针对任一步骤单独提问。同时模型具备支持多模态的复杂推理能力, 可以理解视觉信息,可以基于视觉和文本提出具有一定创新性的观点。
语音能力:STT+TTS+GPT 便捷实现语音对话,优化人机交互体验
语音转文字模型(Speech-To-Text,STT)技术成熟度高,难构成行业壁垒。语音识 别技术历史悠久,最早可以追溯到 1952 年,成熟度相对较高,并已融入各类日常场景。最近几年技术层面逐步从统计模型和走向端到端的深度模型,底层架构逐步从小模型走向 大模型。在多模态大模型系统中,STT 模型将语音转换为特定模式的文本文件,并直接输 入模型。以 OpenAI 推出的 Whisper 模型为代表,模型底层使用 Transformer 的编码器解码器架构,可以将音频信息直接转化成包含提示词的标准化 Token,基于 68 万小时的 对话学习,较主流小模型可以将错误率降低 50%左右。Meta 推出 MMS,谷歌推出 AudioPaLM 模型,均采用 Transformer 架构实现端到端的 STT 模型。
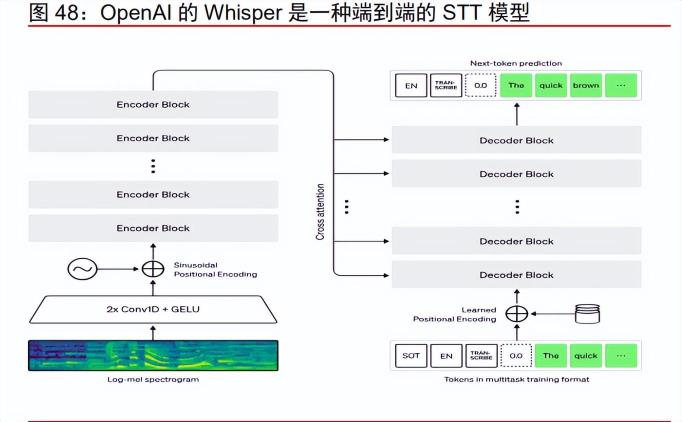
文本转语音(Text-To-Speech,TTS)模型是实现大模型语音能力的核心技术,差异 主要体现在音色和情感方面。TTS 模型同样具有悠久技术历史。过去几年,TTS 模型和 STT 模型在技术层面同步发展,实现从 HMM-GMM 为基础的概率统计模型走向 Transformer 基础的端到端大模型的技术转变,形成 Tacotron 2、Fastspeech 等代表模型。 技术进展下,TTS 模型语音合成效果有明显提升,可以模拟真人的语气、情感和停顿,音 色更加贴近真人,可以实现高质量流畅合成。由于模型训练阶段使用的音源在音色、情感、 语种等方面存在差异,底层模型设计也不尽相同,当前主流 TTS 模型合成效果存在明显差 异,对于用户的使用体验影响较大。
STT+TTS+GPT 模式成为实现大模型语音对话的主流,技术门槛相对较低。通过构建 STT+TTS+GPT 的模式,可以便捷实现基于大语言模型的语言对话,为大模型增加音频模 态。在该模式下,STT、TTS、LLM 模型均为独立模块,可以实现低成本替换,因此在应 用开发层面可进行灵活组合。当前市面主流对话助手的语音功能均以此方式实现,以 ChatGPT 语音功能为例,采用 Whisper+GPT-4+OpenAI 自研 TTS 模型的组合,实现优秀 语音对话效果。考虑到 STT 和 TTS 模型均有成熟开源解决方案,大模型实现语音模态兼 容技术门槛相对较低。
ChatGPT 最新更新 TTS 模型带来接近人类的对话体验。本次更新前,ChatGPT 只支 持基于 Whisper 模型的语音输入,更新后的 ChatGPT 可以将语音作为输出模态,用户可 直接进行语音问答对话。OpenAI 为新场景开发了全新的 TTS 模型,提供五种逼真的输出 音色,每种声音都基于真人录制音源,拥有独特的音调和字符。依托 GPT-4 强大的文本生 成能力,结合高质量和流畅度的语音生成技术,ChatGPT 可以为用户提供逼真的对话体验。 相关技术有望进一步落地智能客服、语言学习等领域,颠覆用户的 AI 对话体验。
视觉能力:形成两大主流路线,图文融合带动应用场景全面扩展
传统计算机视觉(CV)技术储备有助于构建视觉认知模型。计算机视觉(CV)长期 以来是人工智能的核心领域之一,过去十年围绕卷积神经网络实现快速发展。近年来部分CV 模型采用 Transformer 架构,对于大模型时代的视觉系统构建实现技术积累。传统 CV 模型受限规模等原因,主要解决单一场景问题,具备独立的视觉信息处理能力。与传统 CV 模型不同,大模型时代的视觉系统主要围绕提升模型整体的通用能力,以理解和认知 视觉信息为核心,和文本等模态有机结合满足多模态任务的需求,但底层技术存在共通之 处,传统 CV 领域的 Transformer 技术经验积累对于构建大模型视觉系统具有重要价值。
目前在底层架构设计上主要形成两大技术路线:
1)模块化设计: 模块化多模态设计单独处理视觉信息输入。考虑到视觉信息和文本信息差距较大,当 前大模型千亿规模统一处理所有模态信息具有较大难度。因此,设计上可以分别针对文本 和模型等模态分别进行模型训练,并通过系统优化实现各模型的结合。以 GPT-4V(ision) 版本为例,其视觉方案以大语言模型 GPT-4 为核心,图像认知能力上或采用与 OpenAI 2021 年发布的 CLIP 模型类似的方案,未来有望基于 DALL·E 3 模型融合图像输出能力, 形成完整的视觉多模态系统。
模块化设计提升系统灵活性,带来更高模型性价比。视觉认知、视觉生成和大语言模 型在模型设计、训练数据集、目标函数设计等方面差异较大,训练和推理相对独立,模块 化设计和分别训练的模块在性能、性价比、灵活性上存在优势。性能上,各个模块可以针 对特定任务单独优化,更容易在各子任务上实现高性能;性价比上,把各模态的需求分割 成多模块,并进行分开训练的模式,降低了单次训练的模型规模,显著降低算力需求;灵 活性上,各模块可进行单独替换,也可以基于任务需求进行模块增减,同时大模型系统可 以快速接入第三方服务,多维度实现更加灵活的解决方案。
2)一体化(原生多模态)设计: 原生多模态设计统一文本和视觉信息输入。前端利用不同的处理模块将文本、图像等 信息分别 Token 化,并直接输入统一的大模型。12 月 6 日,谷歌发布 Gemini 模型,作为 第一款“原生多模态”大模型,文本和视觉等模态在统一架构下预训练。统一的训练有望 使得各模态之间的结合更加顺畅。根据官方技术文档,模型可以实现图文结合的理解和推 理,目前在数学和物理等领域有所进展,体现了模型的复杂问题拆解能力,对于扩展应用 领域以及提升输出准确性有较大价值。
原生多模态设计实现更强图文结合效果,但模型成本较高。可以针对图像和文本结合 的综合任务进行端到端的统一训练和优化,把图文结合当成一项任务直接进行学习,而不 是通过系统层面基于人为规则制定的融合和调优。因此,采用原生多模态设计的大模型可 以实现多模态信息的无缝共享、互通和融合,例如谷歌 Gemini 模型演示中就展示了基于 模型对于视觉、文本、代码的融合生成能力。但同时为了容纳多模态的处理能力,模型单 次参与推理的参数较多,训练数据的多样性和规模也相应提升,将显著提升模型训练和推 理成本。
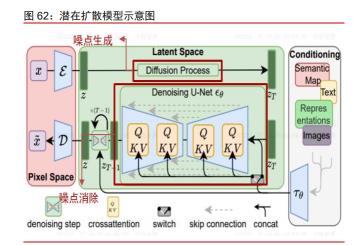
图像生成模型主要采用扩散模型架构,各产品存在显著差异。潜在扩散模型(Latent Diffusion model)是 Transformer 大模型在图像领域的特化应用,通过图片噪点生成的方 式学习大量图片,并通过逆向去噪方式实现图片生成,成为图片生成领域的主流技术路径。 与文本生成注重正确性相比,图片生成需求更加多元,各产品在艺术风格、易用度等方面 的差异化竞争更加明显。目前主流产品可以实现对用户需求的准确理解,并生成高质量的、 具备一定艺术风格的图像。代表产品有主打低门槛高质量生成的 Midjourney,打造开源生 态实现工业级定制的 Stable Diffusion,结合 ChatGPT 实现便捷化使用的 DALL·E 3 等。
视频生成是图像生成在时间轴上的延续,视频与图像生成底层不存在技术壁垒。与图像生成类似,当前视频生成同样通过扩散模型实现,根据 RunwayGen1 模型论文(Patrick Esser, Johnathan Chiu, Parmida Atighehchian 等),在文生视频流程中,模型首先通过 DALL·E、Stable Diffusion 的文生图模型实现高质量图片生成,引入带有时间轴的预训练 图像模型,并在图像和是视频上做联合训练,从而将扩散模型从图像扩展到视频生成领域。 因此视频和图像生成底层不存在技术壁垒,核心能力在于如何更好的处理视频的流畅性和 艺术表达,提升视频生成的长度限制。目前视频模型产品主要功能包括文生视频、文图结 合生成视频、视频智能编辑等功能。根据论文统计,视频生成领域热度明显高于视频编辑 和理解。目前视频生成代表产品包括 Pika、NeverEnds、Runway 等,参考
大模型融合视觉能力可更好支持理解和生成任务,能力升级带动应用场景扩展。
1)对视觉信息的准确理解:视觉问答、组合式问答等任务
多模态大模型提升对视觉信息的理解能力和逻辑能力,实现更加有效的用户反馈。视 觉问答(VQA)要求模型根据图片、视频等视觉信息回答以文本形式提出的事实性问题, 而组合式问答更注重模型的推理能力,要求模型判断非视觉关系并执行推理。与纯视觉模 型相比,拥有视觉能力的大模型在相关任务处理能力上有显著提升。由于大模型拥有庞大 的知识储备,可以结合图像外知识进行详细解释,对于传统 VQA 模型只基于单图的问答 进行了有效扩展和延伸,极大丰富了技术的应用场景。同时,大模型具有图文结合能力、 逻辑能力和复杂问题的拆解能力,有助于模型更好的理解用户复杂需求,回答更抽象的问 题,高质量完成类似组合式问答的逻辑任务。
能力得到第三方验证,有望重塑安防等领域。根据论文 Yunxin Li, Longyue Wang, Baotian Hu 等 发 表 的 论 文 A Comprehensive Evaluation of GPT-4V on Knowledge-Intensive Visual Question Answering 显示,GPT-4V 在 VQA 等问答任务评估 中表现优异,主要体现在有机结合图片信息和外部知识,并可以为答案提供完整且正确的 逻辑解释。未来随着模型效果提升,对于视觉信息的准确理解和逻辑建构能力有望广泛赋 能数据统计、自动筛查、视觉助理、智能助手等领域,实现各行业应用落地。例如在智能 安防领域,可广泛应用于监测、巡检等场景,实现实时快速筛查和安全预警;落地智能助 手领域帮助视觉受损人群理解环境情况等。
2)视觉生成能力:文生图、文生视频等任务
开拓全新图片与视频生成,持续发掘新概念和新产品。大语言模型对用户需求的准确 理解,结合模型的多模态处理能力,形成强大视觉生成能力,包括文生图、文生视频、图 生图等产品,并围绕生成能力产生图片和视频编辑、图片扩展和优化等功能。相关能力落 地各类创意工具,将实现个人生产能力和效率的全面提升。Adobe 推出的 Firefly 工具包,基于大模型多模态能力实现了文字和图像之间的高效交互,发布生成填色、重新上色、3D 互动式生成、图像扩展等智能编辑功能。Pika labs 发布了全新的文生视频产品 Pika 1.0, 仅凭一句话就可以生成 3D 动画、动漫、卡通、电影等各种风格的视频,实现高质量、低 门槛的视频生成。
代码生成:代码大模型快速发展,国产厂商位于第一梯队
通过大语言模型微调构建代码大模型,正确率和多模态融合能力快速提高。代码大模 型主要将自然语言转化成可执行代码,作用于开发领域提升程序员工作效率。由于代码标 准化程度高、容错低,和自然语言差异较大,普遍采取基于语言模型使用代码数据进行微 调的方式,构建专用的代码大模型,这样既可以保留模型对用户输入的高理解能力,又可 以将输出严格限制为代码格式。过去几年,代码大模型围绕提升变成正确率不断升级,最 新基于 GPT-4 构建的代码大模型在 HumanEval 测试级上单次正确率可以达到 82%。此外, 代码与其他模态的互动与融合也是主要进展方向之一,谷歌最新 Gemini 模型演示了基于 文字和图像生成代码的能力,展现相关技术的巨大潜力。
国际巨头加速布局,国厂商位列第一梯队。过去一年全球主要厂商大力投入代码大模型研发,模型能力屡创新高。3 月,OpenAI 基于 GPT-4 推出代码模型,官方技术公告显 示模型在 HumanEval 测试集上的正确率为 67%。9 月,Meta 发布基于 Llama 2 的开源代 码大模型 Code Llama,在 Hugging Face 平台测评中一度超越 GPT-4 等主流代码模型, 占据榜首位置。12 月,Google 基于 Gemini 模型推出 AlphaCode 2,性能超过 85%的人 类程序员,将加持 Gemini 模型定制版。国产厂商中,根据论文 A Survey on Language Models for Code(Zibin Zheng, Kaiwen Ning, Yanlin Wang 等),蚂蚁集团的开源代码大 模型 CodeFuse 和华为代码大模型 PanGu-Coder 2 性能优异,位列行业第一梯队。
短期展望:国外大模型加强多模态支持,国产大模型加速追赶
海外通用大模型更新有望加强的多模态能力支持。根据谷歌官网,目前 Gemini Pro 模型已经接入 Bard 并开放 API 使用,但能力更强的 Gemini Ultra 模型预计将在明年年初 接入 Bard Advanced,正式开启商业化进程。根据 OpenAI CEO Sam Altman 透露,公司 和微软已开始合作开发 GPT-5 模型。Anthropic 曾在提出 2-3 年实现 AGI 的目标,考虑到 多模态能力对 AGI 的重要作用,公司多模态大模型或将于近期推出。海外高质量源生多模 态大模型技术和商业化进程保持高速推进,推动行业保持高速发展。
借鉴海外成熟经验,国产多模态大模型加速追赶。GPT-4V(ision)和 Gemini 大模型 的成功为多模态大模型的技术路径提供参考,国产多模态大模型进展有望逐步加速。金山 软件与华中科技大学联合推出高性能多模态大模型 Monkey,可对图形进行深入问答交流 和精确描述,根据测试,模型在 18 个数据集中表现出色,在图像描述、视觉问答和文本 密集的问答任务上显现优势。考虑到国产厂商在 CV、语音合成等任务上具有一定积累, 大语言模型能力持续提升,我们认为国产多模态大模型有望加速。
行业落地:大模型赋能千行百业,应用市场蓬勃发展
落地机遇:大模型赋能千行百业,整体市场空间广阔
大模型能力赋能千行百业,打造繁荣模型生态。当前大模型已经展现强大文本生成能 力和通用性,在办公、企业管理、金融、教育等领域逐步落地应用。未来,大模型对图像 的识别、理解、总结和推理能力将不断提升,模型可以把图像、视频、文本等信息有机结 合,更智能的认知和回应用户诉求,促进模型融入千行百业,实现规模化落地应用,形成 围绕大模型的繁荣生态。
公有云和私有部署模式共同推进,探索多样化商业模式
公有云模式下 MaaS 模式值得期待,采用“订阅+流量”的收费模式。MaaS(Model as a Service)是一种新的商业模式,将模型作为基础设施部署在公有云端,为下游用户 提供模型使用和基于模型的功能开发支持。行业大模型可利用 MaaS 模式广泛加持各场景, 实现模型生态的快速发展。采用 MaaS 模式的行业大模型主要采取“订阅+流量”收费模 式,用户通过基础订阅获取模型能力接入,同时基于用户模型流量使用情况确定模型服务 价格。
私有化部署模型通过项目制收费,满足客户定制化需求。考虑到模型规模和算力限制, 大模型难以实现终端部署,以私有云模式进行分层部署将是实现模型应用的主要模式。各公司基于经营管理、市场定位、历史文化等方面的考量,容易形成差异化的市场理解,进 而提出不同的模型需求。定制化模型带来更高的开发成本和更长的交付周期,更适用于拥 有深刻行业理解的行业龙头和超大型公司。
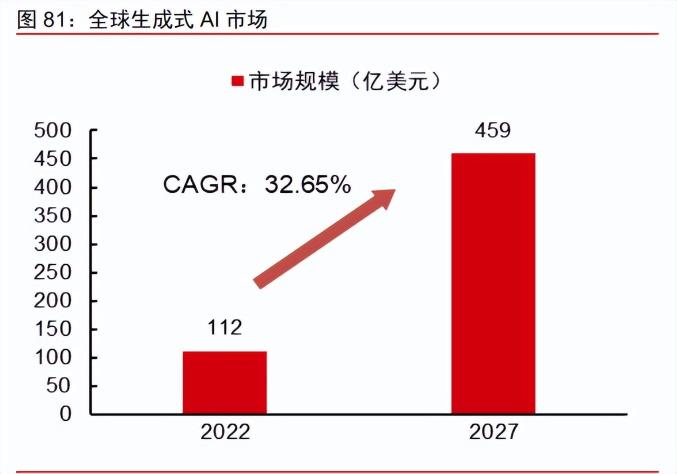
生成式 AI 整体市场空间广阔,有望超过 2000 亿元。根据 technavio 数据,全球生成 式 AI 市场规模有望从 2022 年的 112 亿美元增长到 2027 年的 459 亿美元,2022-2027 年 CAGR 为 32.65%,其中 2023 年将实现 31.65%的增速;根据前瞻产业研究院的数据,2022 年我国生成式 AI 市场规模约 660 亿元,预计 2020~2025 年复合增速将达到 84%,行业整 体处于高速增长通道。在大模型的催化下,生成式 AI 市场规模有望在中短期保持高速成长, 2025 年有望超过 2000 亿元,大模型行业未来发展前景广阔。
办公:模型落地核心场景,打造智能办公助理
四大特征共同作用下,办公软件成大模型应用落地的核心场景之一。1)应用场景扎 实:办公场景关系连接多、信息含量高、时效性强;2)效率提升明确:AI+办公软件在 AIGC(内容创作)、Copilot(智慧助手)、Insight(知识洞察)等方向将带来效率提升;3) 功能演进清晰:伴随扩大测试范围以及正式推向客户,功能有望结合反馈进行快速演进;4)商业落地加速:海外 Microsoft 365 Copilot 计划将以 30 美元/月提供,E3、E5、商业 标准版和商业高级版收费为 36/57/12.5/22 美元/月,国内 WPS AI 已经开启公测。
模型能力限制下,短期以场景化点工具结合为主。由于当前模型通用能力无法覆盖所 有场景,办公软件 AI 产品短期需结合场景进行优化,以点工具集合的形式实现完善模型产 品矩阵。以 WPS AI 为例,公司或将右边栏的对话框化整为零,如在表格中的不同位置提 示对应生成函数、处理数据、分析数据等不同功能;同时针对特定场景,公司基于开源底 座 7B、13B 等小模型,以 Copilot 场景中的表格函数生成为例,大模型在相关领域效果较 差,公司自研小模型实现低成本且高效的表格函数生成。
多模态能力结合打造办公场景下的智能助理。微软全新打造 Microsoft 365 Chat,结 合电子邮件、会议、聊天、文档以及网络数据等多模态信息,Microsoft 365 Chat 对用户 工作需求和习惯形成深刻理解,可以在用户的文件中快速找到所需要的内容并将其与群体 内容相连接,还可以写战略文件、预定商旅、收发电子邮件,全面扮演办公场景下的智能 助理角色。我们认为,伴随大模型应用的逐步深入,智能助理或是公司在生成式 AI 方向上 的潜在布局选择之一,即将当前的 AIGC、Copilot、Insight 三大战略方向统一为全面的智 能助理。
教育:全面引领教学变革,海外产品落地获得认可
应用上形成“教、管、学、考”四大场景,融入具体的教育应用环节。其中“学”和 “考”针对学生,大模型的生成能力融入线下和线上,促进学生教学提质增效,以数据驱 动科学备考和科学练习,学生在学习过程中使用大模型技术,能够提高学习效率。“教” 和“管”主要针对教育者,行业大模型可以利用数据整合能力实现科学的教师和学生评价 管理体系,利用大模型工具学习能力和知识整合能力实现高效备课,将有效减少教师的工 作量,并实现更好地因材施教。
Duolingo 和 Khanmigo 实现大模型线上辅助教学,取得良好市场反馈。Khanmigo 为 Khan Academy 推出的针对专业教育的模型产品,可以充当学生的虚拟导师解释概念、 提供提示、检查答案,并通过个性化教学和自适应辅导的模增强学生对知识的掌握程度。 作为语言教育软件,Duolingo 在最新“Max 订阅方案”中推出两项基于 GPT-4 的设计的 教辅功能,分别是答案解释(Explain my Answer)和角色扮演。在答案解释功能中,模型 可以对用户个性错误加以解释,以提升学习效果;角色扮演中,用户可以在 AI 设计的一系 列语境中扮演各种角色,通过语言时间来深层激发“内在学习(implicit learning)”,挑语 言学习效率。根据多邻国公司财报,23Q2 月活用户达 7410 万,同比增长 50%;日活用 户数 2140 万,同比增长 62%;付费订阅用户为 520 万,同比增长 59%,大模型产品取得 良好市场反馈。
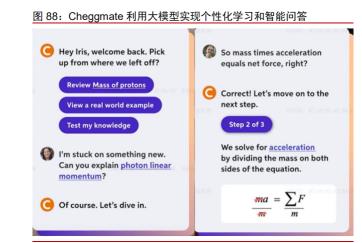
Cheggmate 和 Q-Chat 利用模型文本生成和逻辑能力,落地智能答题和自适应学习 系统领域。3 月,知识记忆工具 Quizlet 基于 GPT 推出 Q-Chat,可作为学习助手为学生 答疑解惑,并辅助学生记忆学科知识。4 月,美国领先的互联网学习平台 Chegg 推出 Cheggmate 利用 GPT-4 构建 AI 学习伴侣,主要加持线上题目问答和课程学习业务。基于 Chegg 自有高质量学习数据集,Cheggmate 可以为学生提供个性化的学习规划、考试设 计、智能问答等服务,其中智能问答功能支持文字、图片、图表等多模态输入知识点和题 目等,并且可以根据用户输入需求定制格式、步骤分解等细节需求,有效帮助学生理解知 识和题目。
企业管理:助力企业降本增效,国内龙头产品逐步落地
数据驱动科学决策实现整体提升,工作助手带动个人效率提升。大模型有望落地 ERP 系统助力企业管理,通过两大方式实现降本增效:1)企业整体角度,行业大模型利用异 构复杂数据流处理能力实现公司内外知识和数据整合,经营上实现数据驱动企业科学决策, 内部管理上实现工作流程优化,实现企业经营能力全面提升。2)个人工作效率上,行业 大模型利用多模态能力开发多样化工作助手,包括智能表单生成、代码开发助手、一键 OA 生成等功能,辅助员工提升工作效率。行业大模型融入 ERP 系统实现企业整体和员工 个人能力提升,从宏观和微观全面提升企业生产经营效率。
Salesforce 推出 Einstein GPT 实现企业对话助手。2023 年 3 月 7 日,Salesforce 基于 ChatGPT 推出企业对话助手 Einstein GPT,该模型在 ChatGPT 基础上融合行业知 识,涵盖客服、营销、市场推广、开发四大应用场景,以对话助手的方式为员工提供快速 会议创建、智能建议、内容生成等功能。同时产品采用开放和可扩展战略,允许订阅用户 进行差异化定制开发,提升了行业模型落地的灵活性。
SAP 公司推出 Joule 助手,全面融入企业经营管理。2023 年 9 月 27 日,SAP 公司 推出生成式 AI 助手 Joule,为企业员工提供基于第三方海量商业数据的智能问答。与 Einstein GPT 项目,Joule 更加深入公司核心生产经营,可以在人力、财务、供应链管理 等领域提供专业意见,将公司和外部数据结合带来经营状况综合分析,并实现数据驱动的 科学决策。Joule 同样包含便捷化的销售服务、差旅工具等流程优化工具,有效提升员工 个人工作效率。
国产龙头加速布局,模型产品逐步落地。国产 ERP 龙头积极跟进大模型落地趋势, 相继发布行业相关产品。7 月 27 日,用友网络发布行业首个企业服务大模型 YonGPT,形 成三大核心能力:1)交互式数据查询和指令执行;2)业务知识问答;3)跨模块复杂任 务执行,并发布首批四大应用场景:1)企业收入、利税分析;2)智能生成销售订单;3) 智能招聘;4)智能大搜。8 月 8 日,金蝶国际在创见者大会上发布“苍穹 GPT”大模型, 未来将作为金蝶云的智能新引擎,融合打造“最懂管理”的企业级大模型平台,并基于模型能力发布四大应用场景:1)财务、2)HR、3)供应链与制造、4)开发,助力公司大 企业产品智能化发展。
消费娱乐:新场景层出不穷,数字营销与游戏行业有望快速落地
行业大模型多模态能力应用广泛,细分场景层出不穷。传媒行业长期需求高质量文本 和图像,行业大模型多模态能力具有广泛应用空间。当前大模型在传媒行业主要应用于营 销、游戏、出版领域,聚焦 C 端用户内容生成和 B 端专业内容生产,实现文本和图片生成、 创意生成、用户个性化等功能。随着大模型技术持续进展,尤其是多模态能力快速发展, 传媒领域新应用场景层出不穷。例如基于大模型多模态能力开发的文生图功能实现广告和 游戏素材生成,代表应用 Stable Diffusion 和 Midjourney 快速取得千万级别用户规模。
数字营销实现个性化高效营销,整体市场空间快速增长。大模型在数字营销上表现优 秀,5 月 Google Marketing Live 上,谷歌展示了最新的广告推送方案,利用大模型实现针 对用户特点的个性化广告内容生成,实现有针对性的精准营销。同时展示了 Product Studio 产品,帮助用户生成高质量商品图片,助力高效产品营销。据群邑全球 2023 年 3 月 9 日 发布的《聚焦中国(China Spotlight 2023)》报告显示,预计 2023 年中国广告市场将增长 6.3%,扭转 2022 年度负增长 0.6%的状况,重回快速增长轨道,2024 年增幅将达到 6.4%,数字营销市场将保持快速增长。
多模态能力带来沉浸式体验,模型辅助代码和素材开发。利用大模型多模态能力,各 游戏公司均加速开发各类 AI 组件,实现沉浸式玩家体验和快速游戏开发。Epic 发布了虚 幻引擎 5 新应用 MetaHuman Animator,实现基于图片的高质量面部生成,以更真实的面 部建模提升用户沉浸式体验。网易伏羲将大模型能力融入网游逆水寒,实验文字生成角色 面部建模,智能 NPC 对话生成等功能。育碧开发 AI 工具 Ghostwriter,利用大模型实现 结合场景的高质量 NPC 对话文本快速生成,辅助快速游戏开发。
(本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)
精选报告来源:【未来智库】。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章